NoTeamName 的 ACM-XCPC 板子
非本人原创
NoTeamName 的 ACM-XCPC 板子
基础算法
常用函数
i64 mysqrt(i64 n) { // 针对 sqrt 无法精确计算 ll 型
i64 ans = sqrt(n);
while ((ans + 1) * (ans + 1) <= n) ans++;
while (ans * ans > n) ans--;
return ans;
}
int mylcm(int x, int y) {
return x / gcd(x, y) * y;
}template<class T> int log2floor(T n) { // 针对 log2 无法精确计算 ll 型;向下取整
assert(n > 0);
for (T i = 0, chk = 1;; i++, chk *= 2) {
if (chk <= n && n < chk * 2) {
return i;
}
}
}
template<class T> int log2ceil(T n) { // 向上取整
assert(n > 0);
for (T i = 0, chk = 1;; i++, chk *= 2) {
if (n <= chk) {
return i;
}
}
}
int log2floor(int x) {
return 31 - __builtin_clz(x);
}
int log2ceil(int x) { // 向上取整
return log2floor(x) + (__builtin_popcount(x) != 1);
}template <class T> T sign(const T &a) {
return a == 0 ? 0 : (a < 0 ? -1 : 1);
}
template <class T> T floor(const T &a, const T &b) { // 注意大数据计算时会丢失精度
T A = abs(a), B = abs(b);
assert(B != 0);
return sign(a) * sign(b) > 0 ? A / B : -(A + B - 1) / B;
}
template <class T> T ceil(const T &a, const T &b) { // 注意大数据计算时会丢失精度
T A = abs(a), B = abs(b);
assert(b != 0);
return sign(a) * sign(b) > 0 ? (A + B - 1) / B : -A / B;
}最大公约数 gcd
速度不如内置函数! 以 的复杂度求解最大公约数。与内置函数 __gcd 功能基本相同(支持 )。有使用位运算的常数优化版本。
inline int mygcd(int a, int b) { return b ? gcd(b, a % b) : a; }整数域二分
- 或 的后继
int l = 0, r = 1E8, ans = r;
while (l <= r) {
int mid = (l + r) / 2;
if (judge(mid)) {
r = mid - 1;
ans = mid;
} else {
l = mid + 1;
}
}
return ans;- 或 的前驱
int l = 0, r = 1E8, ans = l;
while (l <= r) {
int mid = (l + r) / 2;
if (judge(mid)) {
l = mid + 1;
ans = mid;
} else {
r = mid - 1;
}
}
return ans;实数域二分
目前主流的写法是限制二分次数。
for (int t = 1; t <= 100; t++) {
ld mid = (l + r) / 2;
if (judge(mid)) r = mid;
else l = mid;
}
cout << l << endl;整数域三分
while (l < r) {
int mid = (l + r) / 2;
if (check(mid) <= check(mid + 1)) r = mid;
else l = mid + 1;
}
cout << check(l) << endl;实数域三分
限制次数实现。
ld l = -1E9, r = 1E9;
for (int t = 1; t <= 100; t++) {
ld mid1 = (l * 2 + r) / 3;
ld mid2 = (l + r * 2) / 3;
if (judge(mid1) < judge(mid2)) {
r = mid2;
} else {
l = mid1;
}
}
cout << l << endl;二维前缀和
for(int i = 1; i <= n; ++i)
for(int j = 1; j <= m; ++j) cin >> a[i][j];
for(int i = 1; i <= n; ++i)
for(int j = 1; j <= m; ++j)
pre[i][j] = pre[i - 1][j] + pre[i][j - 1] - pre[i - 1][j - 1] + a[i][j];
while(q--)
cin >> x1 >> y1 >> x2 >> y2,
cout << pre[x2][y2] - pre[x2][y1 - 1] - pre[x1 - 1][y2] + pre[x1 - 1][y1 - 1] << '\n';二维差分
for (int i = 1; i <= n; ++i) {
cin >> x1 >> y1 >> x2 >> y2;
diff[x1][y1] += 1;
diff[x2 + 1][y1] -= 1;
diff[x1][y2 + 1] -= 1;
diff[x2 + 1][y2 + 1] -= 1;
}
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
a[i][j] = a[i - 1][j] + a[i][j - 1] - a[i - 1][j - 1] + diff[i][j];
cout << a[i][j] << ' ';
}
cout << '\n';
}树上问题
树的直径
struct Tree {
int n;
vector<vector<int>> ver;
Tree(int n) {
this->n = n;
ver.resize(n + 1);
}
void add(int x, int y) {
ver[x].push_back(y);
ver[y].push_back(x);
}
int getlen(int root) { // 获取x所在树的直径
map<int, int> dep; // map用于优化输入为森林时的深度计算,亦可用vector
function<void(int, int)> dfs = [&](int x, int fa) -> void {
for (auto y : ver[x]) {
if (y == fa) continue;
dep[y] = dep[x] + 1;
dfs(y, x);
}
if (dep[x] > dep[root]) {
root = x;
}
};
dfs(root, 0);
int st = root; // 记录直径端点
dep.clear();
dfs(root, 0);
int ed = root; // 记录直径另一端点
return dep[root];
}
};树论大封装(直径+重心+中心)
struct Tree {
int n;
vector<vector<pair<int, int>>> e;
vector<int> dep, parent, maxdep, d1, d2, s1, s2, up;
Tree(int n) {
this->n = n;
e.resize(n + 1);
dep.resize(n + 1);
parent.resize(n + 1);
maxdep.resize(n + 1);
d1.resize(n + 1);
d2.resize(n + 1);
s1.resize(n + 1);
s2.resize(n + 1);
up.resize(n + 1);
}
void add(int u, int v, int w) {
e[u].push_back({w, v});
e[v].push_back({w, u});
}
void dfs(int u, int fa) {
maxdep[u] = dep[u];
for (auto [w, v] : e[u]) {
if (v == fa) continue;
dep[v] = dep[u] + 1;
parent[v] = u;
dfs(v, u);
maxdep[u] = max(maxdep[u], maxdep[v]);
}
}
void dfs1(int u, int fa) {
for (auto [w, v] : e[u]) {
if (v == fa) continue;
dfs1(v, u);
int x = d1[v] + w;
if (x > d1[u]) {
d2[u] = d1[u], s2[u] = s1[u];
d1[u] = x, s1[u] = v;
} else if (x > d2[u]) {
d2[u] = x, s2[u] = v;
}
}
}
void dfs2(int u, int fa) {
for (auto [w, v] : e[u]) {
if (v == fa) continue;
if (s1[u] == v) {
up[v] = max(up[u], d2[u]) + w;
} else {
up[v] = max(up[u], d1[u]) + w;
}
dfs2(v, u);
}
}
int radius, center, diam;
void getCenter() {
center = 1; //中心
for (int i = 1; i <= n; i++) {
if (max(d1[i], up[i]) < max(d1[center], up[center])) {
center = i;
}
}
radius = max(d1[center], up[center]); //距离最远点的距离的最小值
diam = d1[center] + up[center] + 1; //直径
}
int rem; //删除重心后剩余连通块体积的最小值
int cog; //重心
vector<bool> vis;
void getCog() {
vis.resize(n);
rem = INT_MAX;
cog = 1;
dfsCog(1);
}
int dfsCog(int u) {
vis[u] = true;
int s = 1, res = 0;
for (auto [w, v] : e[u]) {
if (vis[v]) continue;
int t = dfsCog(v);
res = max(res, t);
s += t;
}
res = max(res, n - s);
if (res < rem) {
rem = res;
cog = u;
}
return s;
}
};点分治 / 树的重心
重心的定义:删除树上的某一个点,会得到若干棵子树;删除某点后,得到的最大子树最小,这个点称为重心。我们假设某个点是重心,记录此时最大子树的最小值,遍历完所有点后取最大值即可。
重心的性质:重心最多可能会有两个,且此时两个重心相邻。
点分治的一般过程是:取重心为新树的根,随后使用 处理当前这棵树,灵活运用 child 和 pre 两个数组分别计算通过根节点、不通过根节点的路径信息,根据需要进行答案的更新;再对子树分治,寻找子树的重心,……。时间复杂度降至 。
int root = 0, MaxTree = 1e18; //分别代表重心下标、最大子树大小
vector<int> vis(n + 1), siz(n + 1);
auto get = [&](auto self, int x, int fa, int n) -> void { // 获取树的重心
siz[x] = 1;
int val = 0;
for (auto [y, w] : ver[x]) {
if (y == fa || vis[y]) continue;
self(self, y, x, n);
siz[x] += siz[y];
val = max(val, siz[y]);
}
val = max(val, n - siz[x]);
if (val < MaxTree) {
MaxTree = val;
root = x;
}
};
auto clac = [&](int x) -> void { // 以 x 为新的根,维护询问
set<int> pre = {0}; // 记录到根节点 x 距离为 i 的路径是否存在
vector<int> dis(n + 1);
for (auto [y, w] : ver[x]) {
if (vis[y]) continue;
vector<int> child; // 记录 x 的子树节点的深度信息
auto dfs = [&](auto self, int x, int fa) -> void {
child.push_back(dis[x]);
for (auto [y, w] : ver[x]) {
if (y == fa || vis[y]) continue;
dis[y] = dis[x] + w;
self(self, y, x);
}
};
dis[y] = w;
dfs(dfs, y, x);
for (auto it : child) {
for (int i = 1; i <= m; i++) { // 根据询问更新值
if (q[i] < it || !pre.count(q[i] - it)) continue;
ans[i] = 1;
}
}
pre.insert(child.begin(), child.end());
}
};
auto dfz = [&](auto self, int x, int fa) -> void { // 点分治
vis[x] = 1; // 标记已经被更新过的旧重心,确保只对子树分治
clac(x);
for (auto [y, w] : ver[x]) {
if (y == fa || vis[y]) continue;
MaxTree = 1e18;
get(get, y, x, siz[y]);
self(self, root, x);
}
};
get(get, 1, 0, n);
dfz(dfz, root, 0);最近公共祖先 LCA
树链剖分解法
预处理时间复杂度 ;单次查询 ,常数较小。
struct HLD {
int n, idx;
vector<vector<int>> ver;
vector<int> siz, dep;
vector<int> top, son, parent;
HLD(int n) {
this->n = n;
ver.resize(n + 1);
siz.resize(n + 1);
dep.resize(n + 1);
top.resize(n + 1);
son.resize(n + 1);
parent.resize(n + 1);
}
void add(int x, int y) { // 建立双向边
ver[x].push_back(y);
ver[y].push_back(x);
}
void dfs1(int x) {
siz[x] = 1;
dep[x] = dep[parent[x]] + 1;
for (auto y : ver[x]) {
if (y == parent[x]) continue;
parent[y] = x;
dfs1(y);
siz[x] += siz[y];
if (siz[y] > siz[son[x]]) {
son[x] = y;
}
}
}
void dfs2(int x, int up) {
top[x] = up;
if (son[x]) dfs2(son[x], up);
for (auto y : ver[x]) {
if (y == parent[x] || y == son[x]) continue;
dfs2(y, y);
}
}
int lca(int x, int y) {
while (top[x] != top[y]) {
if (dep[top[x]] > dep[top[y]]) {
x = parent[top[x]];
} else {
y = parent[top[y]];
}
}
return dep[x] < dep[y] ? x : y;
}
int clac(int x, int y) { // 查询两点间距离
return dep[x] + dep[y] - 2 * dep[lca(x, y)];
}
void work(int root = 1) { // 在此初始化
dfs1(root);
dfs2(root, root);
}
};树上倍增解法
预处理时间复杂度 ;单次查询 ,但是常数比树链剖分解法更大。
封装一:基础封装,针对无权图。
struct Tree {
int n;
vector<vector<int>> ver, val;
vector<int> lg, dep;
Tree(int n) {
this->n = n;
ver.resize(n + 1);
val.resize(n + 1, vector<int>(30));
lg.resize(n + 1);
dep.resize(n + 1);
for (int i = 1; i <= n; i++) { //预处理 log
lg[i] = lg[i - 1] + (1 << lg[i - 1] == i);
}
}
void add(int x, int y) { // 建立双向边
ver[x].push_back(y);
ver[y].push_back(x);
}
void dfs(int x, int fa) {
val[x][0] = fa; // 储存 x 的父节点
dep[x] = dep[fa] + 1;
for (int i = 1; i <= lg[dep[x]]; i++) {
val[x][i] = val[val[x][i - 1]][i - 1];
}
for (auto y : ver[x]) {
if (y == fa) continue;
dfs(y, x);
}
}
int lca(int x, int y) {
if (dep[x] < dep[y]) swap(x, y);
while (dep[x] > dep[y]) {
x = val[x][lg[dep[x] - dep[y]] - 1];
}
if (x == y) return x;
for (int k = lg[dep[x]] - 1; k >= 0; k--) {
if (val[x][k] == val[y][k]) continue;
x = val[x][k];
y = val[y][k];
}
return val[x][0];
}
int clac(int x, int y) { // 倍增查询两点间距离
return dep[x] + dep[y] - 2 * dep[lca(x, y)];
}
void work(int root = 1) { // 在此初始化
dfs(root, 0);
}
};封装二:扩展封装,针对有权图,支持“倍增查询两点路径上的最大边权”功能。
struct Tree {
int n;
vector<vector<int>> val, Max;
vector<vector<pair<int, int>>> ver;
vector<int> lg, dep;
Tree(int n) {
this->n = n;
ver.resize(n + 1);
val.resize(n + 1, vector<int>(30));
Max.resize(n + 1, vector<int>(30));
lg.resize(n + 1);
dep.resize(n + 1);
for (int i = 1; i <= n; i++) { //预处理 log
lg[i] = lg[i - 1] + (1 << lg[i - 1] == i);
}
}
void add(int x, int y, int w) { // 建立双向边
ver[x].push_back({y, w});
ver[y].push_back({x, w});
}
void dfs(int x, int fa) {
val[x][0] = fa;
dep[x] = dep[fa] + 1;
for (int i = 1; i <= lg[dep[x]]; i++) {
val[x][i] = val[val[x][i - 1]][i - 1];
Max[x][i] = max(Max[x][i - 1], Max[val[x][i - 1]][i - 1]);
}
for (auto [y, w] : ver[x]) {
if (y == fa) continue;
Max[y][0] = w;
dfs(y, x);
}
}
int lca(int x, int y) {
if (dep[x] < dep[y]) swap(x, y);
while (dep[x] > dep[y]) {
x = val[x][lg[dep[x] - dep[y]] - 1];
}
if (x == y) return x;
for (int k = lg[dep[x]] - 1; k >= 0; k--) {
if (val[x][k] == val[y][k]) continue;
x = val[x][k];
y = val[y][k];
}
return val[x][0];
}
int clac(int x, int y) { // 倍增查询两点间距离
return dep[x] + dep[y] - 2 * dep[lca(x, y)];
}
int query(int x, int y) { // 倍增查询两点路径上的最大边权(带权图)
auto get = [&](int x, int y) -> int {
int ans = 0;
if (x == y) return ans;
for (int i = lg[dep[x]]; i >= 0; i--) {
if (dep[val[x][i]] > dep[y]) {
ans = max(ans, Max[x][i]);
x = val[x][i];
}
}
ans = max(ans, Max[x][0]);
return ans;
};
int fa = lca(x, y);
return max(get(x, fa), get(y, fa));
}
void work(int root = 1) { // 在此初始化
dfs(root, 0);
}
};树上路径交
计算两条路径的交点数量,直接载入任意 LCA 封装即可。
int intersection(int x, int y, int X, int Y) {
vector<int> t = {lca(x, X), lca(x, Y), lca(y, X), lca(y, Y)};
sort(t.begin(), t.end());
int r = lca(x, y), R = lca(X, Y);
if (dep[t[0]] < min(dep[r], dep[R]) || dep[t[2]] < max(dep[r], dep[R])) {
return 0;
}
return 1 + clac(t[2], t[3]);
}三点距离
计算三个点连接形成的路径长度 结论:(三点相互的距离相加除2)!!!
(t.clac(u, v) + t.clac(u, to) + t.clac(v, to)) / 2树上启发式合并 (DSU on tree)
。
void dfs1(int u, int fa) {
siz[u] = 1;
for (auto v: e[u]) {
if (v == fa) continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > siz[son[u]]) son[u] = v;
}
}
void calc(int u, int fa, int val) {
cnt[color[u]] += val;
if (cnt[color[u]] > Max) {
Max = cnt[color[u]];
sum = color[u];
} else if (cnt[color[u]] == Max) {
sum += color[u];
}
for (auto v: e[u]) {
if (v == fa || v == hson) continue;
calc(v, u, val);
}
}
void dfs2(int u, int fa, int opt) {
for (auto v: e[u]) {
if (v == fa || v == son[u]) continue;
dfs2(v, u, 0);
}
if (son[u]) {
dfs2(son[u], u, 1);
hson = son[u]; //记录重链编号,计算的时候跳过
}
calc(u, fa, 1);
hson = 0; //消除的时候所有儿子都清除
ans[u] = sum;
if (!opt) {
calc(u, fa, -1);
sum = 0;
Max = 0;
}
}图论
常见概念
oriented graph:有向图
bidirectional edges:双向边
平面图:若能将无向图 画在平面上使得任意两条无重合顶点的边不相交,则称 是平面图。
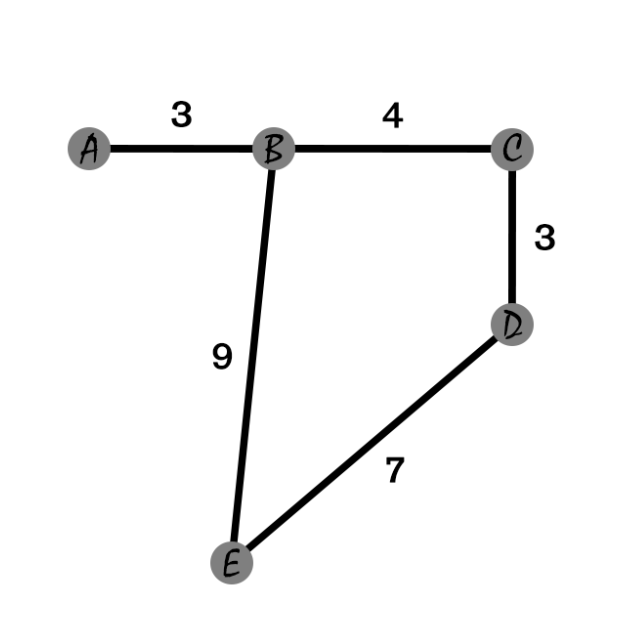
无向正权图上某一点的偏心距:记为 ,即以这个点为源,到其他点的所有最短路的最大值。如下图 点, 即为 。
图的直径:定义为 ,即最大的偏心距,亦可以简化为图中最远的一对点的距离。
图的中心:定义为 ,即偏心距最小的点。如下图,图的中心即为 点。
图的绝对中心:可以定义在边上的图的中心。
图的半径:图的半径不同于圆的半径,其不等于直径的一半(但对于绝对中心定义上的直径而言是一半)。定义为 ,即中心的偏心距。计算方式:使用全源最短路,计算出所有点的偏心距,再加以计算。
单源最短路径(SSSP问题)
(正权稀疏图)动态数组存图+Djikstra算法
使用优先队列优化,以 的复杂度计算。
vector<int> dis(n + 1, 1E18);
auto djikstra = [&](int s = 1) -> void {
using PII = pair<int, int>;
priority_queue<PII, vector<PII>, greater<PII>> q;
q.emplace(0, s);
dis[s] = 0;
vector<int> vis(n + 1);
while (!q.empty()) {
int x = q.top().second;
q.pop();
if (vis[x]) continue;
vis[x] = 1;
for (auto [y, w] : ver[x]) {
if (dis[y] > dis[x] + w) {
dis[y] = dis[x] + w;
q.emplace(dis[y], y);
}
}
}
};(负权图、判负环)Bellman-ford 算法
使用结构体存边(该算法无需存图),以 的复杂度计算。
int n, m, s;
cin >> n >> m >> s;
vector<tuple<int, int, i64>> ver(m + 1);
for (int i = 1; i <= m; ++i) {
int x, y;
i64 w;
cin >> x >> y >> w;
ver[i] = {x, y, w};
}
vector<i64> dis(n + 1, inf), chk(n + 1);
dis[s] = 0;
for (int i = 1; i <= 2 * n; ++i) { // 双倍松弛,获取负环信息
vector<i64> backup = dis;
for (int j = 1; j <= m; ++j) {
auto [x, y, w] = ver[j];
chk[y] |= (i > n && backup[x] + w < dis[y]);
dis[y] = min(dis[y], backup[x] + w);
}
}
for (int i = 1; i <= n; ++i) {
if (i == s) {
cout << 0 << " ";
} else if (dis[i] >= inf / 2) {
cout << "no ";
} else if (chk[i]) {
cout << "inf ";
} else {
cout << dis[i] << " ";
}
}(负权图)SPFA 算法
以 的复杂度计算,其中 虽然为常数,但是可以通过特殊的构造退化成接近 ,需要注意被卡。
const int N = 1e5 + 7, M = 1e6 + 7;
int n, m;
int ver[M], ne[M], h[N], edge[M], tot;
int d[N], v[N];
void add(int x, int y, int w) {
ver[++ tot] = y, ne[tot] = h[x], h[x] = tot;
edge[tot] = w;
}
void spfa() {
ms(d, 0x3f); d[1] = 0;
queue<int> q; q.push(1);
v[1] = 1;
while(!q.empty()) {
int x = q.front(); q.pop(); v[x] = 0;
for (int i = h[x]; i; i = ne[i]) {
int y = ver[i];
if(d[y] > d[x] + edge[i]) {
d[y] = d[x] + edge[i];
if(v[y] == 0) q.push(y), v[y] = 1;
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; ++ i) {
int x, y, w; cin >> x >> y >> w;
add(x, y, w);
}
spfa();
for (int i = 1; i <= n; ++ i) {
if (d[i] == INF) cout << "N" << endl;
else cout << d[n] << endl;
}
}多源汇最短路(APSP问题)
使用邻接矩阵存图,可以处理负权边,以 的复杂度计算。注意,这里建立的是单向边,计算双向边需要额外加边。
const int N = 210;
int n, m, d[N][N];
void floyd() {
for (int k = 1; k <= n; k ++)
for (int i = 1; i <= n; i ++)
for (int j = 1; j <= n; j ++)
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i ++)
for (int j = 1; j <= n; j ++)
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
while (m --) {
int x, y, w; cin >> x >> y >> w;
d[x][y] = min(d[x][y], w);
}
floyd();
for (int i = 1; i <= n; ++ i) {
for (int j = 1; j <= n; ++ j) {
if (d[i][j] > INF / 2) cout << "N" << endl;
else cout << d[i][j] << endl;
}
}
}平面图最短路(对偶图)
对于矩阵图,建立对偶图的过程如下(注释部分为建立原图),其中数据的给出顺序依次为:各 个数字分别代表从左向右、从上向下、从右向左、从下向上的边。
for (int i = 1; i <= n + 1; i++) {
for (int j = 1, w; j <= n; j++) {
cin >> w;
int pre = Hash(i - 1, j), now = Hash(i, j);
if (i == 1) {
add(s, now, w);
} else if (i == n + 1) {
add(pre, t, w);
} else {
add(pre, now, w);
}
// flow.add(Hash(i, j), Hash(i, j + 1), w);
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1, w; j <= n + 1; j++) {
cin >> w;
int now = Hash(i, j), net = Hash(i, j - 1);
if (j == 1) {
add(now, t, w);
} else if (j == n + 1) {
add(s, net, w);
} else {
add(now, net, w);
}
// flow.add(Hash(i, j), Hash(i + 1, j), w);
}
}
for (int i = 1; i <= n + 1; i++) {
for (int j = 1, w; j <= n; j++) {
cin >> w;
int now = Hash(i, j), net = Hash(i - 1, j);
if (i == 1) {
add(now, s, w);
} else if (i == n + 1) {
add(t, net, w);
} else {
add(now, net, w);
}
// flow.add(Hash(i, j), Hash(i, j - 1), w);
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1, w; j <= n + 1; j++) {
cin >> w;
int pre = Hash(i, j - 1), now = Hash(i, j);
if (j == 1) {
add(t, now, w);
} else if (j == n + 1) {
add(pre, s, w);
} else {
add(pre, now, w);
}
// flow.add(Hash(i, j), Hash(i - 1, j), w);
}
}最小生成树(MST问题)
(稀疏图)Prim算法
使用邻接矩阵存图,以 的复杂度计算,思想与 基本一致。
const int N = 550, INF = 0x3f3f3f3f;
int n, m, g[N][N];
int d[N], v[N];
int prim() {
ms(d, 0x3f); //这里的d表示到“最小生成树集合”的距离
int ans = 0;
for (int i = 0; i < n; ++ i) { //遍历 n 轮
int t = -1;
for (int j = 1; j <= n; ++ j)
if (v[j] == 0 && (t == -1 || d[j] < d[t])) //如果这个点不在集合内且当前距离集合最近
t = j;
v[t] = 1; //将t加入“最小生成树集合”
if (i && d[t] == INF) return INF; //如果发现不连通,直接返回
if (i) ans += d[t];
for (int j = 1; j <= n; ++ j) d[j] = min(d[j], g[t][j]); //用t更新其他点到集合的距离
}
return ans;
}
int main() {
ms(g, 0x3f); cin >> n >> m;
while (m -- ) {
int x, y, w; cin >> x >> y >> w;
g[x][y] = g[y][x] = min(g[x][y], w);
}
int t = prim();
if (t == INF) cout << "impossible" << endl;
else cout << t << endl;
} //22.03.19已测试(稠密图)Kruskal算法
平均时间复杂度为 ,简化了并查集。
struct DSU {
vector<int> fa;
DSU(int n) : fa(n + 1) {
iota(fa.begin(), fa.end(), 0);
}
int get(int x) {
while (x != fa[x]) {
x = fa[x] = fa[fa[x]];
}
return x;
}
bool merge(int x, int y) { // 设x是y的祖先
x = get(x), y = get(y);
if (x == y) return false;
fa[y] = x;
return true;
}
bool same(int x, int y) {
return get(x) == get(y);
}
};
struct Tree {
using TII = tuple<int, int, int>;
int n;
priority_queue<TII, vector<TII>, greater<TII>> ver;
Tree(int n) {
this->n = n;
}
void add(int x, int y, int w) {
ver.emplace(w, x, y); // 注意顺序
}
int kruskal() {
DSU dsu(n);
int ans = 0, cnt = 0;
while (ver.size()) {
auto [w, x, y] = ver.top();
ver.pop();
if (dsu.same(x, y)) continue;
dsu.merge(x, y);
ans += w;
cnt++;
}
assert(cnt < n - 1); // 输入有误,建树失败
return ans;
}
};最小乘积生成树
求该图的一棵生成树 T ,使得 最小。
每条边均有2个值。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 202, M = 10002;
template<typename typC>
void read(typC &x) {
int c = getchar(), fh = 1;
while ((c < 48) || (c > 57)) {
if (c == '-') {
c = getchar();
fh = -1;
break;
}
c = getchar();
}
x = c ^ 48;
c = getchar();
while ((c >= 48) && (c <= 57)) {
x = x * 10 + (c ^ 48);
c = getchar();
}
x *= fh;
}
struct P {
int x, y;
P(int a = 0, int b = 0) : x(a), y(b) {}
bool operator<(const P &o) const { return (ll) x * y < (ll) o.x * o.y || (ll) x * y == (ll) o.x * o.y && x < o.x; }
};
struct Q {
int u, v, x, y, val;
bool operator<(const Q &o) const { return val < o.val; }
};
P ans = P(1e9, 1e9), l, r;
Q a[M];
int f[N];
int n, m, i;
int getf(int x) {
if (f[x] == x) return x;
return f[x] = getf(f[x]);
}
P sol1() {
P r = P(0, 0);
for (i = 1; i <= n; i++) f[i] = i;
sort(a + 1, a + m + 1);
for (i = 1; i <= m; i++)
if (getf(a[i].u) != getf(a[i].v)) {
f[f[a[i].u]] = f[a[i].v];
r.x += a[i].x, r.y += a[i].y;
}
return r;
}
void sol2(P l, P r) {
for (i = 1; i <= m; i++) a[i].val = (r.x - l.x) * a[i].y + (l.y - r.y) * a[i].x;
P np = sol1();
ans = min(ans, np);
if ((ll) (r.x - l.x) * (np.y - l.y) - (ll) (r.y - l.y) * (np.x - l.x) >= 0) return;
sol2(l, np);
sol2(np, r);
}
int main() {
read(n);
read(m);
for (i = 1; i <= m; i++) read(a[i].u), read(a[i].v), read(a[i].x), read(a[i].y), ++a[i].u, ++a[i].v;
for (i = 1; i <= m; i++) a[i].val = a[i].x;
l = sol1();
for (i = 1; i <= m; i++) a[i].val = a[i].y;
r = sol1();
ans = min(ans, min(l, r));
sol2(l, r);
printf("%d %d", ans.x, ans.y);
}最小斯坦纳树
找到能包括k个节点权值最小的子图
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
using i128 = __int128_t;
//#define int long long
#define endl '\n'
const int N = 102, M = 1002, K = 1024;
typedef long long ll;
typedef pair<ll, int> pa;
priority_queue<pa, vector<pa>, greater<pa> > heap;
pa cr;
ll f[K][N], inf;
int lj[M], len[M], nxt[M], fir[N];
int n, m, q, i, j, k, x, y, z, bs, c;
void add() {
lj[++bs] = y;
len[bs] = z;
nxt[bs] = fir[x];
fir[x] = bs;
lj[++bs] = x;
len[bs] = z;
nxt[bs] = fir[y];
fir[y] = bs;
}
void read(int &x) {
c = getchar();
while ((c < 48) || (c > 57)) c = getchar();
x = c ^ 48;
c = getchar();
while ((c >= 48) && (c <= 57)) {
x = x * 10 + (c ^ 48);
c = getchar();
}
}
void dijk(int s) {
int i;
while (!heap.empty()) {
x = heap.top().second;
heap.pop();
for (i = fir[x]; i; i = nxt[i])
if (f[s][lj[i]] > f[s][x] + len[i]) {
cr.first = f[s][cr.second = lj[i]] = f[s][x] + len[i];
heap.push(cr);
}
while ((!heap.empty()) && (heap.top().first != f[s][heap.top().second])) heap.pop();
}
}
int main() {
memset(f, 0x3f, sizeof(f));
inf = f[0][0];
read(n);
read(m);
read(q);
while (m--) {
read(x);
read(y);
read(z);
add();
}
for (i = 1; i <= q; i++) {
read(x);
f[1 << i - 1][x] = 0;
}
q = (1 << q) - 1;
for (i = 1; i <= q; i++) {
for (k = 1; k <= n; k++) {
for (j = i & (i - 1); j; j = i & (j - 1)) f[i][k] = min(f[i][k], f[j][k] + f[i ^ j][k]);
if (f[i][k] < inf) heap.push(pa(f[i][k], k));
}
dijk(i);
}
for (i = 1; i <= n; i++) inf = min(inf, f[q][i]);
printf("%lld", inf);
}缩点(Tarjan 算法)
(有向图)强连通分量缩点
强连通分量缩点后的图称为 SCC。以 的复杂度完成上述全部操作。
性质:缩点后的图拥有拓扑序 ,可以不需再另跑一遍 ;缩点后的图是一张有向无环图( 、拓扑图)。
struct SCC {
int n, now, cnt;
vector<vector<int>> ver;
vector<int> dfn, low, col, S;
SCC(int n) : n(n), ver(n + 1), low(n + 1) {
dfn.resize(n + 1, -1);
col.resize(n + 1, -1);
now = cnt = 0;
}
void add(int x, int y) {
ver[x].push_back(y);
}
void tarjan(int x) {
dfn[x] = low[x] = now++;
S.push_back(x);
for (auto y : ver[x]) {
if (dfn[y] == -1) {
tarjan(y);
low[x] = min(low[x], low[y]);
} else if (col[y] == -1) {
low[x] = min(low[x], dfn[y]);
}
}
if (dfn[x] == low[x]) {
int pre;
cnt++;
do {
pre = S.back();
col[pre] = cnt;
S.pop_back();
} while (pre != x);
}
}
auto work() { // [cnt 新图的顶点数量]
for (int i = 1; i <= n; i++) { // 避免图不连通
if (dfn[i] == -1) {
tarjan(i);
}
}
vector<int> siz(cnt + 1); // siz 每个 scc 中点的数量
vector<vector<int>> adj(cnt + 1);
for (int i = 1; i <= n; i++) {
siz[col[i]]++;
for (auto j : ver[i]) {
int x = col[i], y = col[j];
if (x != y) {
adj[x].push_back(y);
}
}
}
return {cnt, adj, col, siz};
}
};(无向图)割边缩点
割边缩点后的图称为边双连通图 (E-DCC),该模板可以在 复杂度内求解图中全部割边、划分边双(颜色相同的点位于同一个边双连通分量中)。
割边(桥):将某边 删去后,原图分成两个以上不相连的子图,称 为图的割边。
边双连通:在一张连通的无向图中,对于两个点 和 ,删去任何一条边(只能删去一条)它们依旧连通,则称 和 边双连通。一个图如果不存在割边,则它是一个边双连通图。
性质补充:对于一个边双,删去任意边后依旧联通;对于边双中的任意两点,一定存在两条不相交的路径连接这两个点(路径上可以有公共点,但是没有公共边)。
struct EDCC {
int n, m, now, cnt;
vector<vector<array<int, 2>>> ver;
vector<int> dfn, low, col, S;
set<array<int, 2>> bridge, direct; // 如果不需要,删除这一部分可以得到一些时间上的优化
EDCC(int n) : n(n), low(n + 1), ver(n + 1), dfn(n + 1), col(n + 1) {
m = now = cnt = 0;
}
void add(int x, int y) { // 和 scc 相比多了一条连边
ver[x].push_back({y, m});
ver[y].push_back({x, m++});
}
void tarjan(int x, int fa) {
dfn[x] = low[x] = ++now;
S.push_back(x);
for (auto &[y, id] : ver[x]) {
if (!dfn[y]) {
direct.insert({x, y});
tarjan(y, id);
low[x] = min(low[x], low[y]);
if (dfn[x] < low[y]) {
bridge.insert({x, y});
}
} else if (id != fa && dfn[y] < dfn[x]) {
direct.insert({x, y});
low[x] = min(low[x], dfn[y]);
}
}
if (dfn[x] == low[x]) {
int pre;
cnt++;
do {
pre = S.back();
col[pre] = cnt;
S.pop_back();
} while (pre != x);
}
}
auto work() {
for (int i = 1; i <= n; i++) { // 避免图不连通
if (!dfn[i]) {
tarjan(i, 0);
}
}
/**
* @param cnt 新图的顶点数量, adj 新图, col 旧图节点对应的新图节点
* @param siz 旧图每一个边双中点的数量
* @param bridge 全部割边, direct 非割边定向
*/
vector<int> siz(cnt + 1);
vector<vector<int>> adj(cnt + 1);
for (int i = 1; i <= n; i++) {
siz[col[i]]++;
for (auto &[j, id] : ver[i]) {
int x = col[i], y = col[j];
if (x != y) {
adj[x].push_back(y);
}
}
}
return tuple{cnt, adj, col, siz};
}
};(无向图)割点缩点
割点缩点后的图称为点双连通图 (V-DCC),该模板可以在 复杂度内求解图中全部割点、划分点双(颜色相同的点位于同一个点双连通分量中)。
割点(割顶):将与某点 连接的所有边删去后,原图分成两个以上不相连的子图,称 为图的割点。
点双连通:在一张连通的无向图中,对于两个点 和 ,删去任何一个点(只能删去一个,且不能删 和 自己)它们依旧连通,则称 和 边双连通。如果一个图不存在割点,那么它是一个点双连通图。
性质补充:每一个割点至少属于两个点双。
struct V_DCC {
int n;
vector<vector<int>> ver, col;
vector<int> dfn, low, S;
int now, cnt;
vector<bool> point; // 记录是否为割点
V_DCC(int n) : n(n) {
ver.resize(n + 1);
dfn.resize(n + 1);
low.resize(n + 1);
col.resize(2 * n + 1);
point.resize(n + 1);
S.clear();
cnt = now = 0;
}
void add(int x, int y) {
if (x == y) return; // 手动去除重边
ver[x].push_back(y);
ver[y].push_back(x);
}
void tarjan(int x, int root) {
low[x] = dfn[x] = ++now;
S.push_back(x);
if (x == root && !ver[x].size()) { // 特判孤立点
++cnt;
col[cnt].push_back(x);
return;
}
int flag = 0;
for (auto y : ver[x]) {
if (!dfn[y]) {
tarjan(y, root);
low[x] = min(low[x], low[y]);
if (dfn[x] <= low[y]) {
flag++;
if (x != root || flag > 1) {
point[x] = true; // 标记为割点
}
int pre = 0;
cnt++;
do {
pre = S.back();
col[cnt].push_back(pre);
S.pop_back();
} while (pre != y);
col[cnt].push_back(x);
}
} else {
low[x] = min(low[x], dfn[y]);
}
}
}
pair<int, vector<vector<int>>> rebuild() { // [新图的顶点数量, 新图]
work();
vector<vector<int>> adj(cnt + 1);
for (int i = 1; i <= cnt; i++) {
if (!col[i].size()) { // 注意,孤立点也是 V-DCC
continue;
}
for (auto j : col[i]) {
if (point[j]) { // 如果 j 是割点
adj[i].push_back(point[j]);
adj[point[j]].push_back(i);
}
}
}
return {cnt, adj};
}
void work() {
for (int i = 1; i <= n; ++i) { // 避免图不连通
if (!dfn[i]) {
tarjan(i, i);
}
}
}
};染色法判定二分图 (dfs算法)
判断一张图能否被二分染色。
vector<int> vis(n + 1);
auto dfs = [&](auto self, int x, int type) -> void {
vis[x] = type;
for (auto y : ver[x]) {
if (vis[y] == type) {
cout << "NO\n";
exit(0);
}
if (vis[y]) continue;
self(self, y, 3 - type);
}
};
for (int i = 1; i <= n; ++i) {
if (vis[i]) {
dfs(dfs, i, 1);
}
}
cout << "Yes\n";链式前向星建图与搜索
很少使用这种建图法。 :标准复杂度为 。节点子节点的数量包含它自己(至少为 ),深度从 开始(根节点深度为 )。 :深度从 开始(根节点深度为 )。 :有向无环图(包括非联通)才拥有完整的拓扑序列(故该算法也可用于判断图中是否存在环)。每次找到入度为 的点并将其放入待查找队列。
namespace Graph {
const int N = 1e5 + 7;
const int M = 1e6 + 7;
int tot, h[N], ver[M], ne[M];
int deg[N], vis[M];
void clear(int n) {
tot = 0; //多组样例清空
for (int i = 1; i <= n; ++i) {
h[i] = 0;
deg[i] = vis[i] = 0;
}
}
void add(int x, int y) {
ver[++tot] = y, ne[tot] = h[x], h[x] = tot;
++deg[y];
}
void dfs(int x) {
a.push_back(x); // DFS序
siz[x] = vis[x] = 1;
for (int i = h[x]; i; i = ne[i]) {
int y = ver[i];
if (vis[y]) continue;
dis[y] = dis[x] + 1;
dfs(y);
siz[x] += siz[y];
}
a.push_back(x);
}
void bfs(int s) {
queue<int> q;
q.push(s);
dis[s] = 1;
while (!q.empty()) {
int x = q.front();
q.pop();
for (int i = h[x]; i; i = ne[i]) {
int y = ver[i];
if (dis[y]) continue;
d[y] = d[x] + 1;
q.push(y);
}
}
}
bool topsort() {
queue<int> q;
vector<int> ans;
for (int i = 1; i <= n; ++i)
if (deg[i] == 0) q.push(i);
while (!q.empty()) {
int x = q.front();
q.pop();
ans.push_back(x);
for (int i = h[x]; i; i = ne[i]) {
int y = ver[i];
--deg[y];
if (deg[y] == 0) q.push(y);
}
}
return ans.size() == n; //判断是否存在拓扑排序
}
} // namespace Graph一般图最大匹配(带花树算法)
与二分图匹配的差别在于图中可能存在奇环,时间复杂度与边的数量无关,为 。下方模板编号从 开始,例题为 UOJ #79. 一般图最大匹配 。
struct Graph {
int n;
vector<vector<int>> e;
Graph(int n) : n(n), e(n) {}
void add(int u, int v) {
e[u].push_back(v);
e[v].push_back(u);
}
pair<int, vector<int>> work() {
vector<int> match(n, -1), vis(n), link(n), f(n), dep(n);
auto find = [&](int u) {
while (f[u] != u) u = f[u] = f[f[u]];
return u;
};
auto lca = [&](int u, int v) {
u = find(u), v = find(v);
while (u != v) {
if (dep[u] < dep[v]) swap(u, v);
u = find(link[match[u]]);
}
return u;
};
queue<int> q;
auto blossom = [&](int u, int v, int p) {
while (find(u) != p) {
link[u] = v;
v = match[u];
if (vis[v] == 0) {
vis[v] = 1;
q.push(v);
}
f[u] = f[v] = p;
u = link[v];
}
};
auto augment = [&](int u) {
while (!q.empty()) q.pop();
iota(f.begin(), f.end(), 0);
fill(vis.begin(), vis.end(), -1);
q.push(u);
vis[u] = 1;
dep[u] = 0;
while (!q.empty()) {
int u = q.front();
q.pop();
for (auto v : e[u]) {
if (vis[v] == -1) {
vis[v] = 0;
link[v] = u;
dep[v] = dep[u] + 1;
if (match[v] == -1) {
for (int x = v, y = u, temp; y != -1;
x = temp, y = x == -1 ? -1 : link[x]) {
temp = match[y];
match[x] = y;
match[y] = x;
}
return;
}
vis[match[v]] = 1;
dep[match[v]] = dep[u] + 2;
q.push(match[v]);
} else if (vis[v] == 1 && find(v) != find(u)) {
int p = lca(u, v);
blossom(u, v, p);
blossom(v, u, p);
}
}
}
};
auto greedy = [&]() {
for (int u = 0; u < n; ++u) {
if (match[u] != -1) continue;
for (auto v : e[u]) {
if (match[v] == -1) {
match[u] = v;
match[v] = u;
break;
}
}
}
};
greedy();
for (int u = 0; u < n; u++) {
if (match[u] == -1) {
augment(u);
}
}
int ans = 0;
for (int u = 0; u < n; u++) {
if (match[u] != -1) {
ans++;
}
}
return {ans / 2, match};
}
};
signed main() {
int n, m;
cin >> n >> m;
Graph graph(n);
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
graph.add(x - 1, y - 1);
}
auto [ans, match] = graph.work();
cout << ans << endl;
for (auto it : match) {
cout << it + 1 << " ";
}
}一般图最大权匹配(带权带花树算法)
下方模板编号从 开始,复杂度为 。
namespace Graph {
const int N = 403 * 2; //两倍点数
typedef int T; //权值大小
const T inf = numeric_limits<int>::max() >> 1;
struct Q { int u, v; T w; } e[N][N];
T lab[N];
int n, m = 0, id, h, t, lk[N], sl[N], st[N], f[N], b[N][N], s[N], ed[N], q[N];
vector<int> p[N];
#define dvd(x) (lab[x.u] + lab[x.v] - e[x.u][x.v].w * 2)
#define FOR(i, b) for (int i = 1; i <= (int)(b); i++)
#define ALL(x) (x).begin(), (x).end()
#define ms(x, i) memset(x + 1, i, m * sizeof x[0])
void upd(int u, int v) {
if (!sl[v] || dvd(e[u][v]) < dvd(e[sl[v]][v])) {
sl[v] = u;
}
}
void ss(int v) {
sl[v] = 0;
FOR(u, n) {
if (e[u][v].w > 0 && st[u] != v && !s[st[u]]) {
upd(u, v);
}
}
}
void ins(int u) {
if (u <= n) { q[++t] = u; }
else {
for (int v : p[u]) ins(v);
}
}
void mdf(int u, int w) {
st[u] = w;
if (u > n) {
for (int v : p[u]) mdf(v, w);
}
}
int gr(int u, int v) {
v = find(ALL(p[u]), v) - p[u].begin();
if (v & 1) {
reverse(1 + ALL(p[u]));
return (int)p[u].size() - v;
}
return v;
}
void stm(int u, int v) {
lk[u] = e[u][v].v;
if (u <= n) return;
Q w = e[u][v];
int x = b[u][w.u], y = gr(u, x);
for (int i = 0; i < y; i++) {
stm(p[u][i], p[u][i ^ 1]);
}
stm(x, v);
rotate(p[u].begin(), y + ALL(p[u]));
}
void aug(int u, int v) {
int w = st[lk[u]];
stm(u, v);
if (!w) return;
stm(w, st[f[w]]), aug(st[f[w]], w);
}
int lca(int u, int v) {
for (++id; u | v; swap(u, v)) {
if (!u) continue;
if (ed[u] == id) return u;
ed[u] = id;
if (u = st[lk[u]]) u = st[f[u]];
}
return 0;
}
void add(int u, int a, int v) {
int x = n + 1, i, j;
while (x <= m && st[x]) ++x;
if (x > m) ++m;
lab[x] = s[x] = st[x] = 0;
lk[x] = lk[a];
p[x].clear();
p[x].push_back(a);
for (i = u; i != a; i = st[f[j]]) {
p[x].push_back(i);
p[x].push_back(j = st[lk[i]]);
ins(j);
}
reverse(1 + ALL(p[x]));
for (i = v; i != a; i = st[f[j]]) { // 复制,只需改循环
p[x].push_back(i);
p[x].push_back(j = st[lk[i]]);
ins(j);
}
mdf(x, x);
FOR(i, m) {
e[x][i].w = e[i][x].w = 0;
}
memset(b[x] + 1, 0, n * sizeof b[0][0]);
for (int u : p[x]) {
FOR(v, m) {
if (!e[x][v].w || dvd(e[u][v]) < dvd(e[x][v])) {
e[x][v] = e[u][v], e[v][x] = e[v][u];
}
}
FOR(v, n) {
if (b[u][v]) { b[x][v] = u; }
}
}
ss(x);
}
void ex(int u) {
for (int x : p[u]) mdf(x, x);
int a = b[u][e[u][f[u]].u], r = gr(u, a);
for (int i = 0; i < r; i += 2) {
int x = p[u][i], y = p[u][i + 1];
f[x] = e[y][x].u;
s[x] = 1;
s[y] = sl[x] = 0;
ss(y), ins(y);
}
s[a] = 1, f[a] = f[u];
for (int i = r + 1; i < p[u].size(); i++) {
s[p[u][i]] = -1;
ss(p[u][i]);
}
st[u] = 0;
}
bool on(const Q &e) {
int u = st[e.u], v = st[e.v];
if (s[v] == -1) {
f[v] = e.u, s[v] = 1;
int a = st[lk[v]];
sl[v] = sl[a] = s[a] = 0;
ins(a);
} else if (!s[v]) {
int a = lca(u, v);
if (!a) {
return aug(u, v), aug(v, u), 1;
} else {
add(u, a, v);
}
}
return 0;
}
bool bfs() {
ms(s, -1), ms(sl, 0);
h = 1, t = 0;
FOR(i, m) {
if (st[i] == i && !lk[i]) {
f[i] = s[i] = 0;
ins(i);
}
}
if (h > t) return 0;
while (1) {
while (h <= t) {
int u = q[h++];
if (s[st[u]] == 1) continue;
FOR(v, n) {
if (e[u][v].w > 0 && st[u] != st[v]) {
if (dvd(e[u][v])) upd(u, st[v]);
else if (on(e[u][v])) return 1;
}
}
}
T x = inf;
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && s[i] == 1) {
x = min(x, lab[i] >> 1);
}
}
FOR(i, m) {
if (st[i] == i && sl[i] && s[i] != 1) {
x = min(x, dvd(e[sl[i]][i]) >> s[i] + 1);
}
}
FOR(i, n) {
if (~s[st[i]]) {
if ((lab[i] += (s[st[i]] * 2 - 1) * x) <= 0) return 0;
}
}
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && ~s[st[i]]) {
lab[i] += (2 - s[st[i]] * 4) * x;
}
}
h = 1, t = 0;
FOR(i, m) {
if (st[i] == i && sl[i] && st[sl[i]] != i && !dvd(e[sl[i]][i]) && on(e[sl[i]][i])) {
return 1;
}
}
for (int i = n + 1; i <= m; i++) {
if (st[i] == i && s[i] == 1 && !lab[i]) ex(i);
}
}
return 0;
}
template<typename TT> i64 work(int N, const vector<tuple<int, int, TT>> &edges) {
ms(ed, 0), ms(lk, 0);
n = m = N; id = 0;
iota(st + 1, st + n + 1, 1);
T wm = 0; i64 r = 0;
FOR(i, n) FOR(j, n) {
e[i][j] = {i, j, 0};
}
for (auto [u, v, w] : edges) {
wm = max(wm, e[v][u].w = e[u][v].w = max(e[u][v].w, (T)w));
}
FOR(i, n) { p[i].clear(); }
FOR(i, n) FOR(j, n) {
b[i][j] = i * (i == j);
}
fill_n(lab + 1, n, wm);
while (bfs()) {};
FOR(i, n) if (lk[i]) {
r += e[i][lk[i]].w;
}
return r / 2;
}
auto match() {
vector<array<int, 2>> ans;
FOR(i, n) if (lk[i]) {
ans.push_back({i, lk[i]});
}
return ans;
}
} // namespace Graph
using Graph::work, Graph::match;
signed main() {
int n, m;
cin >> n >> m;
vector<tuple<int, int, i64>> ver(m);
for (auto &[u, v, w] : ver) {
cin >> u >> v >> w;
}
cout << work(n, ver) << "\n";
auto ans = match();
}二分图最大匹配
二分图:一个图能被分为左右两部分,任何一条边的两个端点都不在同一部分中。
匹配(独立边集):一个边的集合,这些边没有公共顶点。
二分图最大匹配即找到边的数量最多的那个匹配。
一般我们规定,左半部包含 个点(编号 ),右半部包含 个点(编号 ),保证任意一条边的两个端点都不可能在同一部分中。
匈牙利算法(KM算法)解
。
signed main() {
int n1, n2, m;
cin >> n1 >> n2 >> m;
vector<vector<int>> ver(n1 + 1);
for (int i = 1; i <= m; ++i) {
int x, y;
cin >> x >> y;
ver[x].push_back(y); //只需要建立单向边
}
int ans = 0;
vector<int> match(n2 + 1);
for (int i = 1; i <= n1; ++i) {
vector<int> vis(n2 + 1);
auto dfs = [&](auto self, int x) -> bool {
for (auto y : ver[x]) {
if (vis[y]) continue;
vis[y] = 1;
if (!match[y] || self(self, match[y])) {
match[y] = x;
return true;
}
}
return false;
};
if (dfs(dfs, i)) {
ans++;
}
}
cout << ans << endl;
}HopcroftKarp算法(基于最大流)解
该算法基于最大流,常数极小,且引入随机化,几乎卡不掉。最坏时间复杂度为 ,经测试,在 均为 的情况下能在 内跑完。
struct HopcroftKarp {
int n, m;
vector<array<int, 2>> ver;
vector<int> l, r;
HopcroftKarp(int n, int m) : n(n), m(m) { // 左右半部
l.assign(n, -1);
r.assign(m, -1);
}
void add(int x, int y) {
x--, y--; // 这个板子是 0-idx 的
ver.push_back({x, y});
}
int work() {
vector<int> adj(ver.size());
mt19937 rgen(chrono::steady_clock::now().time_since_epoch().count());
shuffle(ver.begin(), ver.end(), rgen); // 随机化防卡
vector<int> deg(n + 1);
for (auto &[u, v] : ver) {
deg[u]++;
}
for (int i = 1; i <= n; i++) {
deg[i] += deg[i - 1];
}
for (auto &[u, v] : ver) {
adj[--deg[u]] = v;
}
int ans = 0;
vector<int> a, p, q(n);
while (true) {
a.assign(n, -1), p.assign(n, -1);
int t = 0;
for (int i = 0; i < n; i++) {
if (l[i] == -1) {
q[t++] = a[i] = p[i] = i;
}
}
bool match = false;
for (int i = 0; i < t; i++) {
int x = q[i];
if (~l[a[x]]) continue;
for (int j = deg[x]; j < deg[x + 1]; j++) {
int y = adj[j];
if (r[y] == -1) {
while (~y) {
r[y] = x;
swap(l[x], y);
x = p[x];
}
match = true;
++ans;
break;
}
if (p[r[y]] == -1) {
q[t++] = y = r[y];
p[y] = x;
a[y] = a[x];
}
}
}
if (!match) break;
}
return ans;
}
vector<array<int, 2>> answer() {
vector<array<int, 2>> ans;
for (int i = 0; i < n; i++) {
if (~l[i]) {
ans.push_back({i, l[i]});
}
}
return ans;
}
};
signed main() {
int n1, n2, m;
cin >> n1 >> n2 >> m;
HopcroftKarp flow(n1, n2);
while (m--) {
int x, y;
cin >> x >> y;
flow.add(x, y);
}
cout << flow.work() << "\n";
auto match = flow.answer();
for (auto [u, v] : match) {
cout << u << " " << v << "\n";
}
}二分图最大权匹配(二分图完美匹配)
定义:找到边权和最大的那个匹配。
一般我们规定,左半部包含 个点(编号 ),右半部包含 个点(编号 )。
使用匈牙利算法(KM算法)解,时间复杂度为 。下方模板用于求解最大权值、且可以输出其中一种可行方案,例题为 UOJ #80. 二分图最大权匹配 。
struct MaxCostMatch {
vector<int> ansl, ansr, pre;
vector<int> lx, ly;
vector<vector<int>> ver;
int n;
MaxCostMatch(int n) : n(n) {
ver.resize(n + 1, vector<int>(n + 1));
ansl.resize(n + 1, -1);
ansr.resize(n + 1, -1);
lx.resize(n + 1);
ly.resize(n + 1, -1E18);
pre.resize(n + 1);
}
void add(int x, int y, int w) {
ver[x][y] = w;
}
void bfs(int x) {
vector<bool> visl(n + 1), visr(n + 1);
vector<int> slack(n + 1, 1E18);
queue<int> q;
function<bool(int)> check = [&](int x) {
visr[x] = 1;
if (~ansr[x]) {
q.push(ansr[x]);
visl[ansr[x]] = 1;
return false;
}
while (~x) {
ansr[x] = pre[x];
swap(x, ansl[pre[x]]);
}
return true;
};
q.push(x);
visl[x] = 1;
while (1) {
while (!q.empty()) {
int x = q.front();
q.pop();
for (int y = 1; y <= n; ++y) {
if (visr[y]) continue;
int del = lx[x] + ly[y] - ver[x][y];
if (del < slack[y]) {
pre[y] = x;
slack[y] = del;
if (!slack[y] && check(y)) return;
}
}
}
int val = 1E18;
for (int i = 1; i <= n; ++i) {
if (!visr[i]) {
val = min(val, slack[i]);
}
}
for (int i = 1; i <= n; ++i) {
if (visl[i]) lx[i] -= val;
if (visr[i]) {
ly[i] += val;
} else {
slack[i] -= val;
}
}
for (int i = 1; i <= n; ++i) {
if (!visr[i] && !slack[i] && check(i)) {
return;
}
}
}
}
int work() {
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= n; ++j) {
ly[i] = max(ly[i], ver[j][i]);
}
}
for (int i = 1; i <= n; ++i) bfs(i);
int res = 0;
for (int i = 1; i <= n; ++i) {
res += ver[i][ansl[i]];
}
return res;
}
void getMatch(int x, int y) { // 获取方案 (0代表无匹配)
for (int i = 1; i <= x; ++i) {
cout << (ver[i][ansl[i]] ? ansl[i] : 0) << " ";
}
cout << endl;
for (int i = 1; i <= y; ++i) {
cout << (ver[i][ansr[i]] ? ansr[i] : 0) << " ";
}
cout << endl;
}
};
signed main() {
int n1, n2, m;
cin >> n1 >> n2 >> m;
MaxCostMatch match(max(n1, n2));
for (int i = 1; i <= m; i++) {
int x, y, w;
cin >> x >> y >> w;
match.add(x, y, w);
}
cout << match.work() << '\n';
match.getMatch(n1, n2);
}二分图最大独立点集(Konig 定理)
给出一张二分图,要求选择一些点使得它们两两没有边直接连接。最小点覆盖等价于最大匹配数,转换为最小割模板,答案即为总点数减去最大流得到的值。
cout << n - flow.work(s, t) << endl;最长路(topsort+DP算法)
计算一张 中的最长路径,在执行前可能需要使用 重构一张正确的 ,复杂度 。
struct DAG {
int n;
vector<vector<pair<int, int>>> ver;
vector<int> deg, dis;
DAG(int n) : n(n) {
ver.resize(n + 1);
deg.resize(n + 1);
dis.assign(n + 1, -1E18);
}
void add(int x, int y, int w) {
ver[x].push_back({y, w});
++deg[y];
}
int topsort(int s, int t) {
queue<int> q;
for (int i = 1; i <= n; i++) {
if (deg[i] == 0) {
q.push(i);
}
}
dis[s] = 0;
while (!q.empty()) {
int x = q.front();
q.pop();
for (auto [y, w] : ver[x]) {
dis[y] = max(dis[y], dis[x] + w);
--deg[y];
if (deg[y] == 0) {
q.push(y);
}
}
}
return dis[t];
}
};
signed main() {
int n, m;
cin >> n >> m;
DAG dag(n);
for (int i = 1; i <= m; i++) {
int x, y, w;
cin >> x >> y >> w;
dag.add(x, y, w);
}
int s, t;
cin >> s >> t;
cout << dag.topsort(s, t) << "\n";
}最短路径树(SPT问题)
定义:在一张无向带权联通图中,有这样一棵生成树:满足从根节点到任意点的路径都为原图中根到任意点的最短路径。
性质:记根节点 到某一结点 的最短距离 ,在 上这两点之间的距离为 ——则两者长度相等。
该算法与最小生成树无关,基于最短路 算法完成(但多了个等于号)。下方代码实现的功能为:读入图后,输出以 为根的 所使用的各条边的编号、边权和。
map<pair<int, int>, int> id;
namespace G {
vector<pair<int, int> > ver[N];
map<pair<int, int>, int> edge;
int v[N], d[N], pre[N], vis[N];
int ans = 0;
void add(int x, int y, int w) {
ver[x].push_back({y, w});
edge[{x, y}] = edge[{y, x}] = w;
}
void djikstra(int s) { // !注意,该 djikstra 并非原版,多加了一个等于号
priority_queue<PII, vector<PII>, greater<PII> > q; q.push({0, s});
memset(d, 0x3f, sizeof d); d[s] = 0;
while (!q.empty()) {
int x = q.top().second; q.pop();
if (v[x]) continue; v[x] = 1;
for (auto [y, w] : ver[x]) {
if (d[y] >= d[x] + w) { // !注意,SPT 这里修改为>=号
d[y] = d[x] + w;
pre[y] = x; // 记录前驱结点
q.push({d[y], y});
}
}
}
}
void dfs(int x) {
vis[x] = 1;
for (auto [y, w] : ver[x]) {
if (vis[y]) continue;
if (pre[y] == x) {
cout << id[{x, y}] << " "; // 输出SPT所使用的边编号
ans += edge[{x, y}];
dfs(y);
}
}
}
void solve(int n) {
djikstra(1); // 以 1 为根
dfs(1); // 以 1 为根
cout << endl << ans; // 输出SPT的边权和
}
}
bool Solve() {
int n, m; cin >> n >> m;
for (int i = 1; i <= m; ++ i) {
int x, y, w; cin >> x >> y >> w;
G::add(x, y, w), G::add(y, x, w);
id[{x, y}] = id[{y, x}] = i;
}
G::solve(n);
return 0;
}无源汇点的最小割问题 Stoer–Wagner
也称为全局最小割。定义补充(与《网络流》中的定义不同):
割:是一个边集,去掉其中所有边能使一张网络流图不再连通(即分成两个子图)。
通过递归的方式来解决无向正权图上的全局最小割问题,算法复杂度 ,一般可近似看作 。
signed main() {
int n, m;
cin >> n >> m;
DSU dsu(n); // 这里引入DSU判断图是否联通,如题目有保证,则不需要此步骤
vector<vector<int>> edge(n + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++) {
int x, y, w;
cin >> x >> y >> w;
dsu.merge(x, y);
edge[x][y] += w;
edge[y][x] += w;
}
if (dsu.Poi(1) != n || m < n - 1) { // 图不联通
cout << 0 << endl;
return 0;
}
int MinCut = INF, S = 1, T = 1; // 虚拟源汇点
vector<int> bin(n + 1);
auto contract = [&]() -> int { // 求解S到T的最小割,定义为 cut of phase
vector<int> dis(n + 1), vis(n + 1);
int Min = 0;
for (int i = 1; i <= n; i++) {
int k = -1, maxc = -1;
for (int j = 1; j <= n; j++) {
if (!bin[j] && !vis[j] && dis[j] > maxc) {
k = j;
maxc = dis[j];
}
}
if (k == -1) return Min;
S = T, T = k, Min = maxc;
vis[k] = 1;
for (int j = 1; j <= n; j++) {
if (!bin[j] && !vis[j]) {
dis[j] += edge[k][j];
}
}
}
return Min;
};
for (int i = 1; i < n; i++) { // 这里取不到等号
int val = contract();
bin[T] = 1;
MinCut = min(MinCut, val);
if (!MinCut) {
cout << 0 << endl;
return 0;
}
for (int j = 1; j <= n; j++) {
if (!bin[j]) {
edge[S][j] += edge[j][T];
edge[j][S] += edge[j][T];
}
}
}
cout << MinCut << endl;
}欧拉路径/欧拉回路 Hierholzers
欧拉路径:一笔画完图中全部边,画的顺序就是一个可行解;当起点终点相同时称欧拉回路。
有向图欧拉路径存在判定
有向图欧拉路径存在: 恰有一个点出度比入度多 (为起点); 恰有一个点入度比出度多 (为终点); 恰有 个点入度均等于出度。如果是欧拉回路,则上方起点与终点的条件不存在,全部点均要满足最后一个条件。
signed main() {
int n, m;
cin >> n >> m;
DSU dsu(n + 1); // 如果保证连通,则不需要 DSU
vector<unordered_multiset<int>> ver(n + 1); // 如果对于字典序有要求,则不能使用 unordered
vector<int> degI(n + 1), degO(n + 1);
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
ver[x].insert(y);
degI[y]++;
degO[x]++;
dsu.merge(x, y); // 直接当无向图
}
int s = 1, t = 1, cnt = 0;
for (int i = 1; i <= n; i++) {
if (degI[i] == degO[i]) {
cnt++;
} else if (degI[i] + 1 == degO[i]) {
s = i;
} else if (degI[i] == degO[i] + 1) {
t = i;
}
}
if (dsu.size(1) != n || (cnt != n - 2 && cnt != n)) {
cout << "No\n";
} else {
cout << "Yes\n";
}
}无向图欧拉路径存在判定
无向图欧拉路径存在: 恰有两个点度数为奇数(为起点与终点); 恰有 个点度数为偶数。
signed main() {
int n, m;
cin >> n >> m;
DSU dsu(n + 1); // 如果保证连通,则不需要 DSU
vector<unordered_multiset<int>> ver(n + 1); // 如果对于字典序有要求,则不能使用 unordered
vector<int> deg(n + 1);
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
ver[x].insert(y);
ver[y].insert(x);
deg[y]++;
deg[x]++;
dsu.merge(x, y); // 直接当无向图
}
int s = -1, t = -1, cnt = 0;
for (int i = 1; i <= n; i++) {
if (deg[i] % 2 == 0) {
cnt++;
} else if (s == -1) {
s = i;
} else {
t = i;
}
}
if (dsu.size(1) != n || (cnt != n - 2 && cnt != n)) {
cout << "No\n";
} else {
cout << "Yes\n";
}
}有向图欧拉路径求解(字典序最小)
vector<int> ans;
auto dfs = [&](auto self, int x) -> void {
while (ver[x].size()) {
int net = *ver[x].begin();
ver[x].erase(ver[x].begin());
self(self, net);
}
ans.push_back(x);
};
dfs(dfs, s);
reverse(ans.begin(), ans.end());
for (auto it : ans) {
cout << it << " ";
}无向图欧拉路径求解
auto dfs = [&](auto self, int x) -> void {
while (ver[x].size()) {
int net = *ver[x].begin();
ver[x].erase(ver[x].find(net));
ver[net].erase(ver[net].find(x));
cout << x << " " << net << endl;
self(self, net);
}
};
dfs(dfs, s);差分约束
给出一组包含 个不等式,有 个未知数的形如: 的不等式组,求任意一组满足这个不等式组的解。 解, 。参考
signed main() {
int n, m;
cin >> n >> m;
vector<array<int, 3>> e(m + 1);
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
e[i] = {v, u, w};
}
vector<int> d(n + 1, 1E9);
d[1] = 0;
for (int i = 1; i < n; i++) {
for (int j = 1; j <= m; j++) {
auto [u, v, w] = e[j];
d[v] = min(d[v], d[u] + w);
}
}
for (int i = 1; i <= m; i++) {
auto [u, v, w] = e[i];
if (d[v] > d[u] + w) {
cout << "NO\n";
return 0;
}
}
for (int i = 1; i <= n; i++) {
cout << d[i] << " \n"[i == n];
}
return 0;
}2-Sat
基础封装
基于 tarjan 缩点,时间复杂度为 。注意下标从 开始,答案输出为字典序最小的一个可行解。
struct TwoSat {
int n;
vector<vector<int>> e;
vector<bool> ans;
TwoSat(int n) : n(n), e(2 * n), ans(n) {}
void add(int u, bool f, int v, bool g) {
e[2 * u + !f].push_back(2 * v + g);
e[2 * v + !g].push_back(2 * u + f);
}
bool work() {
vector<int> id(2 * n, -1), dfn(2 * n, -1), low(2 * n, -1);
vector<int> stk;
int now = 0, cnt = 0;
auto tarjan = [&](auto self, int u) -> void {
stk.push_back(u);
dfn[u] = low[u] = now++;
for (auto v : e[u]) {
if (dfn[v] == -1) {
self(self, v);
low[u] = min(low[u], low[v]);
} else if (id[v] == -1) {
low[u] = min(low[u], dfn[v]);
}
}
if (dfn[u] == low[u]) {
int v;
do {
v = stk.back();
stk.pop_back();
id[v] = cnt;
} while (v != u);
++cnt;
}
};
for (int i = 0; i < 2 * n; ++i) {
if (dfn[i] == -1) {
tarjan(tarjan, i);
}
}
for (int i = 0; i < n; ++i) {
if (id[2 * i] == id[2 * i + 1]) return false;
ans[i] = id[2 * i] > id[2 * i + 1];
}
return true;
}
vector<bool> answer() {
return ans;
}
};答案不唯一时不输出
在运行后针对每一个点进行一次 dfs,时间复杂度为 ,当且仅当答案唯一时才输出,否则输出 ? 替代。
// 结构体中增加
int check(int x, int y) {
vector<int> vis(2 * n);
auto dfs = [&](auto self, int x) -> void {
vis[x] = 1;
for (auto y : e[x]) {
if (vis[y]) continue;
self(self, y);
}
};
dfs(dfs, x);
return vis[y];
}
// 主函数中增加
for (int i = 0; i < n; i++) {
if (sat.check(2 * i, 2 * i + 1)) {
cout << 1 << " ";
} else if (sat.check(2 * i + 1, 2 * i)) {
cout << 0 << " ";
} else {
cout << "?" << " ";
}
}圆方树
void tarjan(int x){
dfn[x] = low[x] = ++tim;
s[++tp] = x;
for(auto to_x:edge[x]){
if(!dfn[to_x]){
tarjan(to_x);
low[x] = min(low[to_x],low[x]);
if(low[to_x] == dfn[x]){
++cnt;
for (int v = 0; v != to_x; --tp) {
v = s[tp];
edge1[cnt].push_back(v);
edge1[v].push_back(cnt);
}
edge1[cnt].push_back(x);
edge1[x].push_back(cnt);
}
}else low[x] = min(dfn[to_x],low[x]);
}
}常见结论
- 要在有向图上求一个最大点集,使得任意两个点 之间至少存在一条路径(可以是从 到 ,也可以反过来,这两种有一个就行),即求解最长路;
- 要求出连通图上的任意一棵生成树,只需要跑一遍 bfs ;
- 给出一棵树,要求添加尽可能多的边,使得其是二分图:对树进行二分染色,显然,相同颜色的点之间连边不会破坏二分图的性质,故可添加的最多的边数即为 ;
- 当一棵树可以被黑白染色时,所有染黑节点的度之和等于所有染白节点的度之和;
- 在竞赛图中,入度小的点,必定能到达出度小(入度大)的点 See 。
- 在竞赛图中,将所有点按入度从小到大排序,随后依次遍历,若对于某一点 满足前 个点的入度之和恰好等于 ,那么对于上一次满足这一条件的点 , 到 点构成一个新的强连通分量 See 。
举例说明,设满足上方条件的点为 ,那么点 到 构成一个强连通分量、点 到 构成一个强连通分量。
- 选择图中最少数量的边删除,使得图不连通,即求最小割;如果是删除点,那么拆点后求最小割 See。
- 如果一张图是平面图,那么其边数一定小于等于 See 。
- 若一张有向完全图存在环,则一定存在三元环。
- 竞赛图三元环计数:See 。
- 有向图判是否存在环直接用 topsort;无向图判是否存在环直接用 dsu,也可以使用 topsort,条件变为
deg[i] <= 1时入队。
常见例题
杂
题意:给出一棵节点数为 的树,要求将点分割为 个点对,使得点对的点之间的距离和最大。
可以转化为边上问题:对于每一条边,其被利用的次数即为 ,使用树形 计算一遍即可。如下图样例,答案为 。
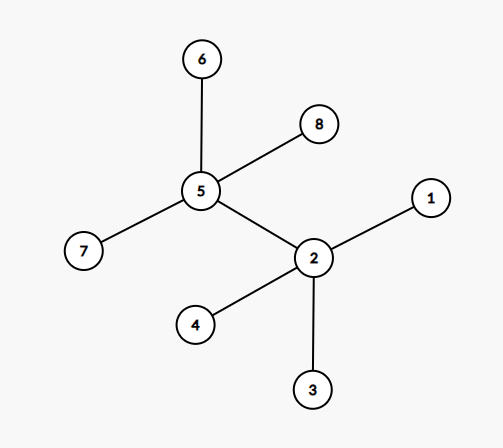
vector<int> val(n + 1, 1);
int ans = 0;
function<void(int, int)> dfs = [&](int x, int fa) {
for (auto y : ver[x]) {
if (y == fa) continue;
dfs(y, x);
val[x] += val[y];
ans += min(val[y], k - val[y]);
}
};
dfs(1, 0);
cout << ans << endl;题意:以哪些点为起点可以无限的在有向图上绕
概括一下这些点可以发现,一类是环上的点,另一类是可以到达环的点。建反图跑一遍 topsort 板子,根据容斥,未被移除的点都是答案 See 。
题意:添加最少的边,使得有向图变成一个 SCC
将原图的 SCC 缩点,统计缩点后的新图上入度为 和出度为 的点的数量 ,答案即为 。过程大致是先将一个出度为 的点和一个入度为 的点相连,剩下的点随便连 See 。
题意:添加最少的边,使得无向图变成一个 E-DCC
将原图的 E-DCC 缩点,统计缩点后的新图上入度为 的点(叶子结点)的数量 ,答案即为 。过程大致是每次找两个叶子结点(但是还有一些条件限制)相连,若最后余下一个点随便连 See 。
题意:在树上找到一个最大的连通块,使得这个联通内点权和边权之和最大,输出这个值,数据中存在负数的情况。
使用 dfs 即可解决。
LL n, point[N];
LL ver[N], head[N], nex[N], tot; bool v[N];
map<pair<LL, LL>, LL> edge;
// void add(LL x, LL y) {}
void dfs(LL x) {
for (LL i = head[x]; i; i = nex[i]) {
LL y = ver[i];
if (v[y]) continue;
v[y] = true; dfs(y); v[y] = false;
}
for (LL i = head[x]; i; i = nex[i]) {
LL y = ver[i];
if (v[y]) continue;
point[x] += max(point[y] + edge[{x, y}], 0LL);
}
}
void Solve() {
cin >> n;
FOR(i, 1, n) cin >> point[i];
FOR(i, 2, n) {
LL x, y, w; cin >> x >> y >> w;
edge[{x, y}] = edge[{y, x}] = w;
add(x, y), add(y, x);
}
v[1] = true; dfs(1); LL ans = -MAX18;
FOR(i, 1, n) ans = max(ans, point[i]);
cout << ans << endl;
}Prüfer 序列:凯莱公式
题意:给定 个顶点,可以构建出多少棵标记树?
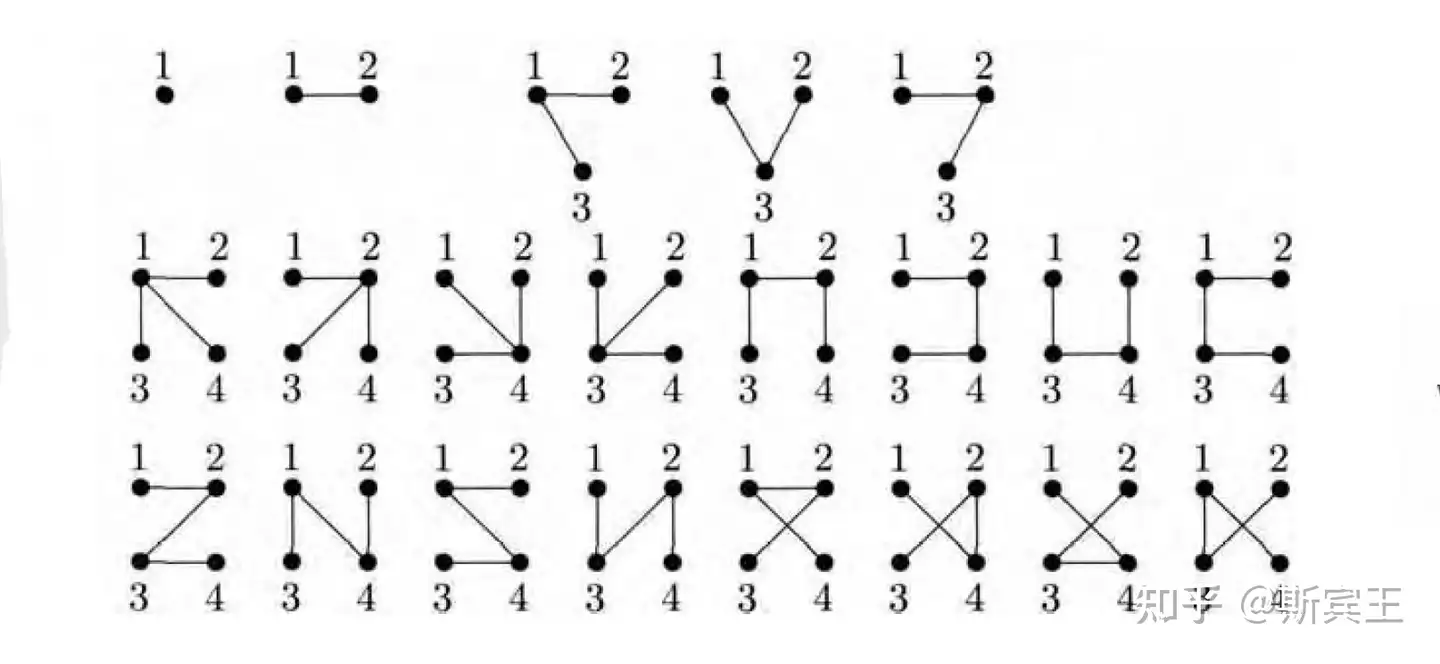
时的样例如上,通项公式为 。
Prüfer 序列
一个 个点 条边的带标号无向图有 个连通块。我们希望添加 条边使得整个图连通,求方案数量 See 。
设 表示每个连通块的数量,通项公式为 ,当 时答案为 。
单源最短/次短路计数
const int N = 2e5 + 7, M = 1e6 + 7;
int n, m, s, e; int d[N][2], v[N][2]; // 0 代表最短路, 1 代表次短路
Z num[N][2];
void Clear() {
for (int i = 1; i <= n; ++ i) h[i] = edge[i] = 0;
tot = 0;
for (int i = 1; i <= n; ++ i) num[i][0] = num[i][1] = v[i][0] = v[i][1] = 0;
for (int i = 1; i <= n; ++ i) d[i][0] = d[i][1] = INF;
}
int ver[M], ne[M], h[N], edge[M], tot;
void add(int x, int y, int w) {
ver[++ tot] = y, ne[tot] = h[x], h[x] = tot;
edge[tot] = w;
}
void dji() {
priority_queue<PIII, vector<PIII>, greater<PIII> > q; q.push({0, s, 0});
num[s][0] = 1; d[s][0] = 0;
while (!q.empty()) {
auto [dis, x, type] = q.top(); q.pop();
if (v[x][type]) continue; v[x][type] = 1;
for (int i = h[x]; i; i = ne[i]) {
int y = ver[i], w = dis + edge[i];
if (d[y][0] > w) {
d[y][1] = d[y][0], num[y][1] = num[y][0];
// 如果找到新的最短路,将原有的最短路数据转化为次短路
q.push({d[y][1], y, 1});
d[y][0] = w, num[y][0] = num[x][type];
q.push({d[y][0], y, 0});
}
else if (d[y][0] == w) num[y][0] += num[x][type];
else if (d[y][1] > w) {
d[y][1] = w, num[y][1] = num[x][type];
q.push({d[y][1], y, 1});
}
else if (d[y][1] == w) num[y][1] += num[x][type];
}
}
}
void Solve() {
cin >> n >> m >> s >> e;
Clear(); //多组样例务必完全清空
for (int i = 1; i <= m; ++ i) {
int x, y, w; cin >> x >> y; w = 1;
add(x, y, w), add(y, x, w);
}
dji();
Z ans = num[e][0];
if (d[e][1] == d[e][0] + 1) {
ans += num[e][1]; // 只有在次短路满足条件时才计算(距离恰好比最短路大1)
}
cout << ans.val() << endl;
}输出任意一个三元环
原题:给出一张有向完全图,输出任意一个三元环上的全部元素 See 。使用 dfs,复杂度 ,可以扩展到非完全图和无向图。
int n;
cin >> n;
vector<vector<int>> a(n + 1, vector<int>(n + 1));
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= n; ++j) {
char x;
cin >> x;
if (x == '1') a[i][j] = 1;
}
}
vector<int> vis(n + 1);
function<void(int, int)> dfs = [&](int x, int fa) {
vis[x] = 1;
for (int y = 1; y <= n; ++y) {
if (a[x][y] == 0) continue;
if (a[y][fa] == 1) {
cout << fa << " " << x << " " << y;
exit(0);
}
if (!vis[y]) dfs(y, x); // 这一步的if判断很关键
}
};
for (int i = 1; i <= n; ++i) {
if (!vis[i]) dfs(i, -1);
}
cout << -1;带权最小环大小与计数
原题:给出一张有向带权图,求解图上最小环的长度、有多少个这样的最小环 See 。使用 floyd,复杂度为 ,可以扩展到无向图。
LL Min = 1e18, ans = 0;
for (int k = 1; k <= n; k++) {
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (dis[i][j] > dis[i][k] + dis[k][j]) {
dis[i][j] = dis[i][k] + dis[k][j];
cnt[i][j] = cnt[i][k] * cnt[k][j] % mod;
} else if (dis[i][j] == dis[i][k] + dis[k][j]) {
cnt[i][j] = (cnt[i][j] + cnt[i][k] * cnt[k][j] % mod) % mod;
}
}
}
for (int i = 1; i < k; i++) {
if (a[k][i]) {
if (a[k][i] + dis[i][k] < Min) {
Min = a[k][i] + dis[i][k];
ans = cnt[i][k];
} else if (a[k][i] + dis[i][k] == Min) {
ans = (ans + cnt[i][k]) % mod;
}
}
}
}最小环大小
原题:给出一张无向图,求解图上最小环的长度、有多少个这样的最小环 See 。使用 floyd,可以扩展到有向图。
int flody(int n) {
for (int i = 1; i <= n; ++ i) {
for (int j = 1; j <= n; ++ j) {
val[i][j] = dis[i][j]; // 记录最初的边权值
}
}
int ans = 0x3f3f3f3f;
for (int k = 1; k <= n; ++ k) {
for (int i = 1; i < k; ++ i) { // 注意这里是没有等于号的
for (int j = 1; j < i; ++ j) {
ans = min(ans, dis[i][j] + val[i][k] + val[k][j]);
}
}
for (int i = 1; i <= n; ++ i) { // 往下是标准的flody
for (int j = 1; j <= n; ++ j) {
dis[i][j] = min(dis[i][j], dis[i][k] + dis[k][j]);
}
}
}
return ans;
}使用 bfs,复杂度为 。
auto bfs = [&] (int s) {
queue<int> q; q.push(s);
dis[s] = 0;
fa[s] = -1;
while (q.size()) {
auto x = q.front(); q.pop();
for (auto y : ver[x]) {
if (y == fa[x]) continue;
if (dis[y] == -1) {
dis[y] = dis[x] + 1;
fa[y] = x;
q.push(y);
}
else ans = min(ans, dis[x] + dis[y] + 1);
}
}
};
for (int i = 1; i <= n; ++ i) {
fill(dis + 1, dis + 1 + n, -1);
bfs(i);
}
cout << ans;本质不同简单环计数
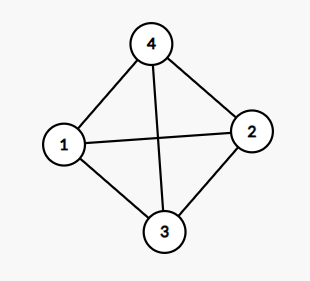
原题:给出一张无向图,输出简单环的数量 See 。注意这里环套环需要分别多次统计,下图答案应当为 。使用状压 dp,复杂度为 ,可以扩展到有向图。
int n, m;
cin >> n >> m;
vector<vector<int>> G(n);
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
u--, v--;
G[u].push_back(v);
G[v].push_back(u);
}
vector<vector<LL>> dp(1 << n, vector<LL>(n));
for (int i = 0; i < n; i++) dp[1 << i][i] = 1;
LL ans = 0;
for (int st = 1; st < (1 << n); st++) {
for (int u = 0; u < n; u++) {
if (!dp[st][u]) continue;
int start = st & -st;
for (auto v : G[u]) {
if ((1 << v) < start) continue;
if ((1 << v) & st) {
if ((1 << v) == start) {
ans += dp[st][u];
}
} else {
dp[st | (1 << v)][v] += dp[st][u];
}
}
}
}
cout << (ans - m) / 2 << "\n";输出任意一个非二元简单环
原题:给出一张无向图,不含自环与重边,输出任意一个简单环的大小以及其上面的全部元素 See 。注意输出的环的大小是随机的,不等价于最小环。
由于不含重边与自环,所以环的大小至少为 ,使用 dfs 处理出 dfs 序,复杂度为 ,可以扩展到有向图;如果有向图中二元环也允许计入答案,则需要删除下方标注行。
vector<int> dis(n + 1, -1), fa(n + 1);
auto dfs = [&](auto self, int x) -> void {
for (auto y : ver[x]) {
if (y == fa[x]) continue; // 二元环需删去该行
if (dis[y] == -1) {
dis[y] = dis[x] + 1;
fa[y] = x;
self(self, y);
} else if (dis[y] < dis[x]) {
cout << dis[x] - dis[y] + 1 << endl;
int pre = x;
cout << pre << " ";
while (pre != y) {
pre = fa[pre];
cout << pre << " ";
}
cout << endl;
exit(0);
}
}
};
for (int i = 1; i <= n; i++) {
if (dis[i] == -1) {
dis[i] = 0;
dfs(dfs, 1);
}
}有向图环计数
原题:给出一张有向图,输出环的数量。注意这里环套环仅需要计算一次,数据包括二元环和自环,下图例应当输出 个环。使用 dfs 染色法,复杂度为 。
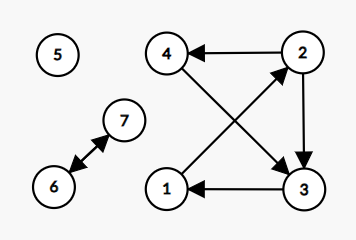
int ans = 0;
vector<int> vis(n + 1);
auto dfs = [&](auto self, int x) -> void {
vis[x] = 1;
for (auto y : ver[x]) {
if (vis[y] == 0) {
self(self, y);
} else if (vis[y] == 1) {
ans++;
}
}
vis[x] = 2;
};
for (int i = 1; i <= n; i++) {
if (!vis[i]) {
dfs(dfs, i);
}
}
cout << ans << endl;有向图简单环检查、输出
NowCoder ,带自环重边、不连通。
signed main() {
int n, m;
cin >> n >> m;
vector<vector<array<int, 2>>> ver(n + 1);
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
ver[x].push_back({y, i});
}
vector<int> vis(n + 1);
vector<array<int, 2>> fa(n + 1);
auto dfs = [&](auto self, int x, int from) -> void {
vis[x] = 1;
for (auto [y, id] : ver[x]) {
if (id == from) continue;
if (!vis[y]) {
fa[y] = {x, id};
self(self, y, id);
} else if (vis[y] == 1) {
vector<int> V = {y}, E = {id};
for (int pre = x; pre != y; pre = fa[pre][0]) {
V.push_back(pre);
E.push_back(fa[pre][1]);
}
int l = V.size();
cout << l << "\n";
reverse(V.begin(), V.end());
reverse(E.begin(), E.end());
rotate(E.begin(), E.begin() + 1, E.end());
for (int i = 0; i < l; i++) {
cout << V[i] << " \n"[i == l - 1];
}
for (int i = 0; i < l; i++) {
cout << E[i] << " \n"[i == l - 1];
}
exit(0);
}
}
vis[x] = 2;
};
for (int i = 1; i <= n; i++) {
if (!vis[i]) {
dfs(dfs, i, -1);
}
}
cout << -1 << "\n";
}无向图简单环检查、输出
NowCoder ,带自环重边、不连通。
signed main() {
int n, m;
cin >> n >> m;
vector<vector<array<int, 2>>> ver(n + 1);
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
ver[x].push_back({y, i});
ver[y].push_back({x, i});
}
vector<int> vis(n + 1);
vector<array<int, 2>> fa(n + 1);
auto dfs = [&](auto self, int x, int from) -> void {
vis[x] = 1;
for (auto [y, id] : ver[x]) {
if (id == from) continue;
if (!vis[y]) {
fa[y] = {x, id};
self(self, y, id);
} else if (vis[y] == 1) {
vector<int> ans1 = {y}, ans2 = {id};
for (int pre = x; pre != y; pre = fa[pre][0]) {
ans1.push_back(pre);
ans2.push_back(fa[pre][1]);
}
int l = ans1.size();
cout << l << "\n";
for (int i = 0; i < l; i++) {
cout << ans1[i] << " \n"[i == l - 1];
}
for (int i = 0; i < l; i++) {
cout << ans2[i] << " \n"[i == l - 1];
}
exit(0);
}
}
vis[x] = 2;
};
for (int i = 1; i <= n; i++) {
if (!vis[i]) {
dfs(dfs, i, -1);
}
}
cout << -1 << "\n";
}判定带环图是否是平面图
原题:给定一个环以一些额外边,对于每一条额外边判定其位于环外还是环内,使得任意两条无重合顶点的额外边都不相交(即这张图构成平面图)See1, See2 。
使用 2-sat。考虑全部边都位于环内,那么“一条边完全包含另一条边”、“两条边完全没有交集”这两种情况都不会相交,可以直接跳过这两种情况的讨论。
signed main() {
int n, m;
cin >> n >> m;
vector<pair<int, int>> in(m);
for (int i = 0, x, y; i < m; i++) {
cin >> x >> y;
in[i] = minmax(x, y);
}
TwoSat sat(m);
for (int i = 0; i < m; i++) {
auto [s, e] = in[i];
for (int j = i + 1; j < m; j++) {
auto [S, E] = in[j];
if (s < S && S < e && e < E || S < s && s < E && E < e) {
sat.add(i, 0, j, 0);
sat.add(i, 1, j, 1);
}
}
}
if (!sat.work()) {
cout << "Impossible\n";
return 0;
}
auto ans = sat.answer();
for (auto it : ans) {
cout << (it ? "out" : "in") << " ";
}
}网络流
最大流
使用 算法,理论最坏复杂度为 ,例题范围: 。一般步骤: 建立分层图,无回溯 寻找所有可行的增广路径。封装:求从点 到点 的最大流。预流推进见常数优化章节。
template<typename T> struct Flow_ {
const int n;
const T inf = numeric_limits<T>::max();
struct Edge {
int to;
T w;
Edge(int to, T w) : to(to), w(w) {}
};
vector<Edge> ver;
vector<vector<int>> h;
vector<int> cur, d;
Flow_(int n) : n(n + 1), h(n + 1) {}
void add(int u, int v, T c) {
h[u].push_back(ver.size());
ver.emplace_back(v, c);
h[v].push_back(ver.size());
ver.emplace_back(u, 0);
}
bool bfs(int s, int t) {
d.assign(n, -1);
d[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
auto x = q.front();
q.pop();
for (auto it : h[x]) {
auto [y, w] = ver[it];
if (w && d[y] == -1) {
d[y] = d[x] + 1;
if (y == t) return true;
q.push(y);
}
}
}
return false;
}
T dfs(int u, int t, T f) {
if (u == t) return f;
auto r = f;
for (int &i = cur[u]; i < h[u].size(); i++) {
auto j = h[u][i];
auto &[v, c] = ver[j];
auto &[u, rc] = ver[j ^ 1];
if (c && d[v] == d[u] + 1) {
auto a = dfs(v, t, std::min(r, c));
c -= a;
rc += a;
r -= a;
if (!r) return f;
}
}
return f - r;
}
T work(int s, int t) {
T ans = 0;
while (bfs(s, t)) {
cur.assign(n, 0);
ans += dfs(s, t, inf);
}
return ans;
}
};
using Flow = Flow_<int>;最小割
基础模型:构筑二分图,左半部 个点代表盈利项目,右半部 个点代表材料成本,收益为盈利之和减去成本之和,求最大收益。
建图:建立源点 向左半部连边,建立汇点 向右半部连边,如果某个项目需要某个材料,则新增一条容量 的跨部边。
割边:放弃某个项目则断开 至该项目的边,购买某个原料则断开该原料至 的边,最终的图一定不存在从 到 的路径,此时我们得到二分图的一个 割。此时最小割即为求解最大流,边权之和减去最大流即为最大收益。
signed main() {
int n, m;
cin >> n >> m;
int S = n + m + 1, T = n + m + 2;
Flow flow(T);
for (int i = 1; i <= n; i++) {
int w;
cin >> w;
flow.add(S, i, w);
}
int sum = 0;
for (int i = 1; i <= m; i++) {
int x, y, w;
cin >> x >> y >> w;
flow.add(x, n + i, 1E18);
flow.add(y, n + i, 1E18);
flow.add(n + i, T, w);
sum += w;
}
cout << sum - flow.work(S, T) << endl;
}最小割树 Gomory-Hu Tree
无向连通图抽象出的一棵树,满足任意两点间的距离是他们的最小割。一共需要跑 轮最小割,总复杂度 ,预处理最小割树上任意两点的距离 。
过程:分治 轮,每一轮在图上随机选点,跑一轮最小割后连接树边;这一网络的残留网络会将剩余的点分为两组,根据分组分治。
void reset() { // struct需要额外封装退流
for (int i = 0; i < ver.size(); i += 2) {
ver[i].w += ver[i ^ 1].w;
ver[i ^ 1].w = 0;
}
}
signed main() { // Gomory-Hu Tree
int n, m;
cin >> n >> m;
Flow<int> flow(n);
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
flow.add(u, v, w);
flow.add(v, u, w);
}
vector<int> vis(n + 1), fa(n + 1);
vector ans(n + 1, vector<int>(n + 1, 1E9)); // N^2 枚举出全部答案
vector<vector<pair<int, int>>> adj(n + 1);
for (int i = 1; i <= n; i++) { // 分治 n 轮
int s = 0; // 本质是在树上随机选点、跑最小割后连边
for (; s <= n; s++) {
if (fa[s] != s) break;
}
int t = fa[s];
int ans = flow.work(s, t); // 残留网络将点集分为两组,分治
adj[s].push_back({t, ans});
adj[t].push_back({s, ans});
vis.assign(n + 1, 0);
auto dfs = [&](auto dfs, int u) -> void {
vis[u] = 1;
for (auto it : flow.h[u]) {
auto [v, c] = flow.ver[it];
if (c && !vis[v]) {
dfs(dfs, v);
}
}
};
dfs(dfs, s);
for (int j = 0; j <= n; j++) {
if (vis[j] && fa[j] == t) {
fa[j] = s;
}
}
}
for (int i = 0; i <= n; i++) {
auto dfs = [&](auto dfs, int u, int fa, int c) -> void {
ans[i][u] = c;
for (auto [v, w] : adj[u]) {
if (v == fa) continue;
dfs(dfs, v, u, min(c, w));
}
};
dfs(dfs, i, -1, 1E9);
}
int q;
cin >> q;
while (q--) {
int u, v;
cin >> u >> v;
cout << ans[u][v] << "\n"; // 预处理答数组
}
}费用流
给定一个带费用的网络,规定 间的费用为 ,求解该网络中总花费最小的最大流称之为最小费用最大流。总时间复杂度为 ,其中 代表最大流。
struct MinCostFlow {
using LL = long long;
using PII = pair<LL, int>;
const LL INF = numeric_limits<LL>::max();
struct Edge {
int v, c, f;
Edge(int v, int c, int f) : v(v), c(c), f(f) {}
};
const int n;
vector<Edge> e;
vector<vector<int>> g;
vector<LL> h, dis;
vector<int> pre;
MinCostFlow(int n) : n(n), g(n) {}
void add(int u, int v, int c, int f) { // c 流量, f 费用
// if (f < 0) {
// g[u].push_back(e.size());
// e.emplace_back(v, 0, f);
// g[v].push_back(e.size());
// e.emplace_back(u, c, -f);
// } else {
g[u].push_back(e.size());
e.emplace_back(v, c, f);
g[v].push_back(e.size());
e.emplace_back(u, 0, -f);
// }
}
bool dijkstra(int s, int t) {
dis.assign(n, INF);
pre.assign(n, -1);
priority_queue<PII, vector<PII>, greater<PII>> que;
dis[s] = 0;
que.emplace(0, s);
while (!que.empty()) {
auto [d, u] = que.top();
que.pop();
if (dis[u] < d) continue;
for (int i : g[u]) {
auto [v, c, f] = e[i];
if (c > 0 && dis[v] > d + h[u] - h[v] + f) {
dis[v] = d + h[u] - h[v] + f;
pre[v] = i;
que.emplace(dis[v], v);
}
}
}
return dis[t] != INF;
}
pair<int, LL> flow(int s, int t) {
int flow = 0;
LL cost = 0;
h.assign(n, 0);
while (dijkstra(s, t)) {
for (int i = 0; i < n; ++i) h[i] += dis[i];
int aug = numeric_limits<int>::max();
for (int i = t; i != s; i = e[pre[i] ^ 1].v) aug = min(aug, e[pre[i]].c);
for (int i = t; i != s; i = e[pre[i] ^ 1].v) {
e[pre[i]].c -= aug;
e[pre[i] ^ 1].c += aug;
}
flow += aug;
cost += LL(aug) * h[t];
}
return {flow, cost};
}
};网络流 | 最大流 | 预流推进 HLPP
理论最坏复杂度为 ,例题范围: 。
template <typename T>
struct HLPP {
const int inf = 0x3f3f3f3f;
const T INF = 0x3f3f3f3f3f3f3f3f;
struct Edge {
int to, cap, flow, anti;
Edge(int v = 0, int w = 0, int id = 0) : to(v), cap(w), flow(0), anti(id) {}
};
vector<vector<Edge>> e;
vector<vector<int>> gap;
vector<T> ex; // 超额流
vector<bool> ingap;
vector<int> h;
int n, gobalcnt, maxH = 0;
T maxflow = 0;
HLPP(int n) : n(n), e(n + 1), ex(n + 1), gap(n + 1) {}
void addEdge(int u, int v, int w) {
e[u].push_back({v, w, (int)e[v].size()});
e[v].push_back({u, 0, (int)e[u].size() - 1});
}
void PushEdge(int u, Edge &edge) {
int v = edge.to, d = min(ex[u], 1LL * edge.cap - edge.flow);
ex[u] -= d;
ex[v] += d;
edge.flow += d;
e[v][edge.anti].flow -= d;
if (h[v] != inf && d > 0 && ex[v] == d && !ingap[v]) {
++gobalcnt;
gap[h[v]].push_back(v);
ingap[v] = 1;
}
}
void PushPoint(int u) {
for (auto k = e[u].begin(); k != e[u].end(); k++) {
if (h[k->to] + 1 == h[u] && k->cap > k->flow) {
PushEdge(u, *k);
if (!ex[u]) break;
}
}
if (!ex[u]) return;
if (gap[h[u]].empty()) {
for (int i = h[u] + 1; i <= min(maxH, n); i++) {
for (auto v : gap[i]) {
ingap[v] = 0;
}
gap[i].clear();
}
}
h[u] = inf;
for (auto [to, cap, flow, anti] : e[u]) {
if (cap > flow) {
h[u] = min(h[u], h[to] + 1);
}
}
if (h[u] >= n) return;
maxH = max(maxH, h[u]);
if (!ingap[u]) {
gap[h[u]].push_back(u);
ingap[u] = 1;
}
}
void init(int t, bool f = 1) {
ingap.assign(n + 1, 0);
for (int i = 1; i <= maxH; i++) {
gap[i].clear();
}
gobalcnt = 0, maxH = 0;
queue<int> q;
h.assign(n + 1, inf);
h[t] = 0, q.push(t);
while (q.size()) {
int u = q.front();
q.pop(), maxH = h[u];
for (auto &[v, cap, flow, anti] : e[u]) {
if (h[v] == inf && e[v][anti].cap > e[v][anti].flow) {
h[v] = h[u] + 1;
q.push(v);
if (f) {
gap[h[v]].push_back(v);
ingap[v] = 1;
}
}
}
}
}
T flow(int s, int t) {
init(t, 0);
if (h[s] == inf) return maxflow;
h[s] = n;
ex[s] = INF;
ex[t] = -INF;
for (auto k = e[s].begin(); k != e[s].end(); k++) {
PushEdge(s, *k);
}
while (maxH > 0) {
if (gap[maxH].empty()) {
maxH--;
continue;
}
int u = gap[maxH].back();
gap[maxH].pop_back();
ingap[u] = 0;
PushPoint(u);
if (gobalcnt >= 10 * n) {
init(t);
}
}
ex[s] -= INF;
ex[t] += INF;
return maxflow = ex[t];
}
};dinic优化费用流
class DinicWithCost {
private:
struct Edge {
int to, cap, cost, rev;
};
vector<vector<Edge>> graph;
vector<vector<Edge>::iterator> cur;
vector<int> dist;
vector<bool> vis;
queue<int> que;
int n, S, T;
bool bfs(void) {
for (int i = 1; i <= n; i++) dist[i] = INT64_MAX, vis[i] = false, cur[i] = graph[i].begin();
que.push(S), dist[S] = 0;
while (!que.empty()) {
int p = que.front();
que.pop(), vis[p] = false;
for (auto i : graph[p])
if (i.cap && dist[i.to] > dist[p] + i.cost) {
dist[i.to] = dist[p] + i.cost;
if (!vis[i.to]) vis[i.to] = true, que.push(i.to);
}
}
return dist[T] != INT64_MAX;
}
int dfs(int p, int rest) {
if (p == T) return rest;
vis[p] = true;
int use = 0, c;
for (auto i = cur[p]; i != graph[p].end() && rest; i++) {
cur[p] = i;
if (!i->cap || dist[i->to] != dist[p] + i->cost || vis[i->to]) continue;
if (!(c = dfs(i->to, min(rest, i->cap)))) dist[i->to] = -1;
i->cap -= c, graph[i->to][i->rev].cap += c, use += c, rest -= c;
}
vis[p] = false;
return use;
}
public:
void resize(int _n) { return graph.resize((n = _n) + 1), cur.resize(n + 1), dist.resize(n + 1), vis.resize(n + 1); }
void addEdge(int from, int to, int cap, int cost) {
return graph[from].push_back(Edge{to, cap, cost, (int)graph[to].size()}),
graph[to].push_back(Edge{from, 0, -cost, (int)graph[from].size() - 1});
}
pair<int, int> maxFlow(int _S, int _T) {
S = _S, T = _T;
int flow = 0, cost = 0;
while (bfs()) {
int c = dfs(S, INT64_MAX);
flow += c, cost += dist[T] * c;
}
return {flow, cost};
}
};
DinicWithCost ans;数论
常见数列
调和级数
满足调和级数 ,可以用 $ \approx N\ln N$ 来拟合,但是会略小,误差量级在 左右。本地可以在500ms内完成 量级的预处理计算。
| N的量级 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 累加和 | 27 | 482 | 7’069 | 93‘668 | 1’166‘750 | 13‘970’034 | 162‘725’364 | 1‘857’511‘568 | 20’877‘697’634 |
下方示例为求解 到 中各个数字的因数值。
const int N = 1E5;
vector<vector<int>> dic(N + 1);
for (int i = 1; i <= N; i++) {
for (int j = i; j <= N; j += i) {
dic[j].push_back(i);
}
}素数密度与分布
| N的量级 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 素数数量 | 4 | 25 | 168 | 1‘229 | 9’592 | 78‘498 | 664’579 | 5‘761’455 | 50‘847’534 |
除此之外,对于任意两个相邻的素数 ,有 成立,更具体的说,最大的差值为 。
因数最多数字与其因数数量
| N的量级 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 因数最多数字的因数数量 | 4 | 25 | 32 | 64 | 128 | 240 | 448 |
| 因数最多的数字 | - | - | - | 7560, 9240 | 83160, 98280 | 720720, 831600, 942480, 982800, 997920 | - |
预处理勾股数
set<array<int, 3>> st;
void init(int limit) { // limit为最大边长!!!
for (int m = 2; m * m < limit; ++m) {
for (int n = 1; n < m; ++n) {
if ((m + n) & 1LL && gcd(m, n) == 1) { // 确保m和n互质且一奇一偶
int a = m * m - n * n;
int b = 2 * m * n;
int c = m * m + n * n;
if (a > b)swap(a, b); // 满足 a < b < c
if (c <= limit) st.insert({a, b, c});
// 如果需要衍生勾股数运行这个
for (int k = 2; k * c <= limit; ++k) {
int aa = k * a;
int bb = k * b;
int cc = k * c;
st.insert({aa, bb, cc});
}
}
}
}
}快速幂
常规
i64 mul(i64 a, i64 b, i64 m) { // 快速乘提速,约四倍效果
i64 r = a * b - m * i64(1.L / m * a * b);
return r - m * (r >= m) + m * (r < 0);
}
i64 pow(i64 a, i64 b, i64 m) {
i64 res = 1 % m;
for (; b; b >>= 1, a = mul(a, a, m)) {
if (b & 1) res = mul(res, a, m);
}
return res;
}质数判断
Miller-Rabin
随机化验证,非严谨计算的平均复杂度约为 。对于某些强力质数,可能会退化至约 。有常数优化版本可以再快五倍。
i64 mul(i64 a, i64 b, i64 m) { // 快速乘提速,约四倍效果
i64 r = a * b - m * i64(1.L / m * a * b);
return r - m * (r >= m) + m * (r < 0);
}
i64 pow(i64 a, i64 b, i64 m) {
i64 res = 1 % m;
for (; b; b >>= 1, a = mul(a, a, m)) {
if (b & 1) res = mul(res, a, m);
}
return res;
}
bool isprime(i64 n) {
if (n < 2 || n % 6 % 4 != 1) {
return (n | 1) == 3;
}
i64 s = __builtin_ctzll(n - 1), d = n >> s;
for (i64 a : {2, 325, 9375, 28178, 450775, 9780504, 1795265022}) {
i64 p = pow(a % n, d, n), i = s;
while (p != 1 && p != n - 1 && a % n && i--) {
p = mul(p, p, n);
}
if (p != n - 1 && i != s) return false;
}
return true;
}质因子分解
埃氏筛(bitset来筛取1E7)
void init() {
bitset<N> vis;
for (int i = 2; i <= 100000000; ++i) {
if (!vis[i]) {
prime.push_back(i);
for (long long j = (long long) i * i; j <= 100000000; j += i)vis[j] = true;
}
}
}线性筛
使用欧拉筛(线性筛),预处理时间复杂度 ,单次查询 。
vector<int> prime;
bool vis[N];
void init_prime(int n_) {
vis[1] = true;
for (int i = 2; i <= n_; ++i) {
if (!vis[i])prime.push_back(i);
for (const auto &j: prime) {
if (i * j > n_)break;
vis[i * j] = true;
if (i % j == 0)break;
}
}
}区间筛
const int N = 1e6 + 5;
bool prime[N];//[L,R]区间偏移
bool primeSqrt[N];//筛选sqrt(R)以内的素数
void init(int l, int r) {
for (int i = 2; i * i <= r; ++i)primeSqrt[i] = true;
for (int i = 0; i <= r - l; ++i)prime[i] = true;
for (int i = 2; i * i <= r; ++i) {
if (primeSqrt[i]) {
for (int j = 2 * i; j * j <= r; j += i) primeSqrt[j] = false;
for (int j = max(2ll, (l + i - 1) / i) * i; j <= r; j += i)prime[j - l] = false;
}
}
int l1, r1, l2, r2, cnt = 0, last = 0, detaMin = 1e9, detaMax = 0;
if (l==1)prime[0]= false;
for (int i = 0; i <= r - l; ++i) {
if (prime[i]) {
if (cnt) {
if (i - last > detaMax)detaMax = i - last, l2 = last, r2 = i;
if (i - last < detaMin)detaMin = i - last, l1 = last, r1 = i;
}
++cnt;
last = i;
}
}
l1 += l, r1 += l, l2 += l, r2 += l;
if (cnt < 2)cout << "There are no adjacent primes." << endl;
else cout << l1 << ',' << r1 << " are closest, " << l2 << ',' << r2 << " are most distant." << endl;
}Pollard-Rho
以单个因子 的复杂度输出数字 的全部质因数,由于需要结合素数测试,总复杂度会略高一些。如果遇到超时的情况,可能需要考虑进一步优化,例如检查题目是否强制要求枚举全部质因数等等。有常数优化版本可以再快五倍。
i64 rho(i64 n) {
if (!(n & 1)) return 2;
i64 x = 0, y = 0, prod = 1;
auto f = [&](i64 x) -> i64 {
return mul(x, x, n) + 5; // 这里的种子为 1 时能被 hack,取 5 到目前为止没有什么问题
};
for (int t = 30, z = 0; t % 64 || gcd(prod, n) == 1; ++t) {
if (x == y) x = ++z, y = f(x);
if (i64 q = mul(prod, x + n - y, n)) prod = q;
x = f(x), y = f(f(y));
}
return gcd(prod, n);
}
vector<i64> factorize(i64 x) {
vector<i64> res;
auto f = [&](auto f, i64 x) {
if (x == 1) return;
if (isprime(x)) return res.push_back(x);
i64 y = rho(x);
f(f, y), f(f, x / y);
};
f(f, x), sort(res.begin(), res.end());
return res;
}裴蜀定理
成立的充要条件是 ( 表示正整数集)。
例题:给定一个序列 ,找到一个序列 ,使得 最小。
for (int i = 0; i < n; i ++ ){
cin >> a;
if (a < 0) a = -a;
ans = gcd(ans, a);
}逆元
费马小定理解(借助快速幂)
单次计算的复杂度即为快速幂的复杂度 。限制: 必须是质数,且需要满足 与 互质。
LL inv(LL x) { return mypow(x, mod - 2, mod);}扩展欧几里得解
此方法的 没有限制,复杂度为 ,但是比快速幂法常数大一些。
int x, y;
int exgcd(int a, int b, int &x, int &y) { //扩展欧几里得算法
if (b == 0) {
x = 1, y = 0;
return a; //到达递归边界开始向上一层返回
}
int r = exgcd(b, a % b, x, y);
int temp = y; //把x y变成上一层的
y = x - (a / b) * y;
x = temp;
return r; //得到a b的最大公因数
}
LL getInv(int a, int mod) { //求a在mod下的逆元,不存在逆元返回-1
LL x, y, d = exgcd(a, mod, x, y);
return d == 1 ? (x % mod + mod) % mod : -1;
}线性预处理逆元
以 的复杂度完成 中全部逆元的计算。
int jc[N];//i! mod
int f0[N];//i在mod下逆元
int finv[N];//i!在mod下逆元
void init_inv(int _n) {
jc[0] = jc[1] = f0[0] = f0[1] = finv[0] = finv[1] = 1;
for (int i = 2; i <= _n; ++i) {
jc[i] = jc[i - 1] * i % mod;
f0[i] = (mod - mod / i) * f0[mod % i] % mod;
finv[i] = finv[i - 1] * f0[i] % mod;
}
}
int C(int n, int m) {
if (m > n || n < 0 || m < 0)return 0;
return jc[n] * finv[m] % mod * finv[n - m] % mod;
}求子序列gcd之和
void solve() {
int n;
cin >> n;
vector<int> a(n + 1, 0), g(n + 1, 0);
for (int i = 1; i <= n; ++i) cin >> a[i], g[i] = a[i];
queue<int> q;
vector<int> tmp;
int ans = 0;
for (int r = 1; r <= n; ++r) {
int last = 0;
while (!q.empty()) {
int l = q.front();
q.pop();
g[l] = __gcd(g[l], g[r]);
if (g[l] == g[last])continue;
tmp.emplace_back(l);
last = l;
}
if (g[last] != g[r]) tmp.emplace_back(r);
for (int i = 0; i + 1 < tmp.size(); ++i) {
ans += (tmp[i + 1] - tmp[i]) * g[tmp[i]];
q.emplace(tmp[i]);
}
ans += (r - tmp[tmp.size() - 1] + 1) * g[r];
q.emplace(tmp[tmp.size() - 1]);
tmp.clear();
}
cout << ans << '\n';
}扩展欧几里得 exgcd
求解形如 的不定方程的任意一组解。
int exgcd(int a, int b, int &x, int &y) {
if (!b) {
x = 1, y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= a / b * x;
return d;
}例题:求解二元一次不定方程 。
1.由裴蜀定理可知才有解
2.在有解的情况下,由可知-->a要满足大于0(便于后续求解)
由于求得的解为一个特解因此通解可以表示为
通解公式的推导:
又由于,则必为的倍数,故
3.
4.由于是裴蜀定理建立在的情况下的,而一般,故
5.由于是正整数解->取模加模再取模->
auto calc = [&](int a, int b, int c) -> int {
// ax + by = c 返回最小的正整数解xmin
// 若要求ymin --> by + ax = c即可
int x1, y1;
int d = exgcd(a, b, x1, y1);
if (c % d != 0) return -1; // 无解
else return ((x1 * c / d) % (b / d) + (b / d)) % (b / d);
};
auto clac = [&](int a, int b, int c) { // 在a<0时的计算有点问题(不建议使用)
int u = 1, v = 1;
if (a < 0) { // 负数特判,但是没用经过例题测试
a = -a;
u = -1;
}
if (b < 0) {
b = -b;
v = -1;
}
int x, y, d = exgcd(a, b, x, y), ans;
if (c % d != 0) { // 无整数解
cout << -1 << "\n";
return;
}
a /= d, b /= d, c /= d;
x *= c, y *= c; // 得到可行解
ans = (x % b + b - 1) % b + 1;
auto [A, B] = pair{u * ans, v * (c - ans * a) / b}; // x最小正整数 特解
ans = (y % a + a - 1) % a + 1;
auto [C, D] = pair{u * (c - ans * b) / a, v * ans}; // y最小正整数 特解
int num = (C - A) / b + 1; // xy均为正整数 的 解的组数
};离散对数 bsgs 与 exbsgs
以 的复杂度求解 。其中标准 算法不能计算 与 互质的情况,而 exbsgs 则可以。
namespace BSGS {
LL a, b, p;
map<LL, LL> f;
inline LL gcd(LL a, LL b) { return b > 0 ? gcd(b, a % b) : a; }
inline LL ps(LL n, LL k, int p) {
LL r = 1;
for (; k; k >>= 1) {
if (k & 1) r = r * n % p;
n = n * n % p;
}
return r;
}
void exgcd(LL a, LL b, LL &x, LL &y) {
if (!b) {
x = 1, y = 0;
} else {
exgcd(b, a % b, x, y);
LL t = x;
x = y;
y = t - a / b * y;
}
}
LL inv(LL a, LL b) {
LL x, y;
exgcd(a, b, x, y);
return (x % b + b) % b;
}
LL bsgs(LL a, LL b, LL p) {
f.clear();
int m = ceil(sqrt(p));
b %= p;
for (int i = 1; i <= m; i++) {
b = b * a % p;
f[b] = i;
}
LL tmp = ps(a, m, p);
b = 1;
for (int i = 1; i <= m; i++) {
b = b * tmp % p;
if (f.count(b) > 0) return (i * m - f[b] + p) % p;
}
return -1;
}
LL exbsgs(LL a, LL b, LL p) {
if (b == 1 || p == 1) return 0;
LL g = gcd(a, p), k = 0, na = 1;
while (g > 1) {
if (b % g != 0) return -1;
k++;
b /= g;
p /= g;
na = na * (a / g) % p;
if (na == b) return k;
g = gcd(a, p);
}
LL f = bsgs(a, b * inv(na, p) % p, p);
if (f == -1) return -1;
return f + k;
}
} // namespace BSGS
using namespace BSGS;
int main() {
IOS;
cin >> p >> a >> b;
a %= p, b %= p;
LL ans = exbsgs(a, b, p);
if (ans == -1) cout << "no solution\n";
else cout << ans << "\n";
return 0;
}欧拉函数
直接求解单个数的欧拉函数
到 中与 互质数的个数称为欧拉函数,记作 。求解欧拉函数的过程即为分解质因数的过程,复杂度 。
int phi(int n) { //求解 phi(n)
int ans = n;
for(int i = 2; i <= n / i; i ++) {
if(n % i == 0) {
ans = ans / i * (i - 1);
while(n % i == 0) n /= i;
}
}
if(n > 1) ans = ans / n * (n - 1); //特判 n 为质数的情况
return ans;
}求解 1 到 N 所有数的欧拉函数
利用上述第四条性质,我们可以快速递推出 中每个数的欧拉函数,复杂度 ,而该算法即是线性筛的算法。
const int N = 1e5 + 7;
int v[N], prime[N], phi[N];
void euler(int n) {
ms(v, 0); //最小质因子
int m = 0; //质数数量
for (int i = 2; i <= n; ++ i) {
if (v[i] == 0) { // i 是质数
v[i] = i, prime[++ m] = i;
phi[i] = i - 1;
}
//为当前的数 i 乘上一个质因子
for (int j = 1; j <= m; ++ j) {
//如 i 有比 prime[j] 更小的质因子,或超出 n ,停止
if(prime[j] > v[i] || prime[j] > n / i) break;
// prime[j] 是合数 i * prime[j] 的最小质因子
v[i * prime[j]] = prime[j];
phi[i * prime[j]] = phi[i] * (i % prime[j] ? prime[j] - 1 : prime[j]);
}
}
}
int main() {
int n; cin >> n; euler(n);
for (int i = 1; i <= n; ++ i) cout << phi[i] << endl;
return 0;
}使用莫比乌斯反演求解欧拉函数
int phi[N];
vector<int> fac[N];
void get_eulers() {
for (int i = 1; i <= N - 10; i++) {
for (int j = i; j <= N - 10; j += i) {
fac[j].push_back(i);
}
}
phi[1] = 1;
for (int i = 2; i <= N - 10; i++) {
phi[i] = i;
for (auto j : fac[i]) {
if (j == i) continue;
phi[i] -= phi[j];
}
}
}组合数
debug
提供一组测试数据: 377'389'666'165'540'953'244'592'352'291'892'721'700,模数为 时为 ; 时为 。
卢卡斯定理(模数必须为质数)
int Lucas(int n, int k int p) {
if (k == 0) return 1;
return (C(n % p, k % p, p) * Lucas(n / p, k / p, p)) % p;
}扩展卢卡斯定理(模数任意)
namespace zyt {
const int N = 1e6;
int n, m, p;
int fac(const int n, const int p, const int pk) {
if (!n)
return 1;
int ans = 1;
for (int i = 1; i < pk; i++)
if (i % p) ans = ans * i % pk;
ans = power(ans, n / pk, pk);
for (int i = 1; i <= n % pk; i++)
if (i % p) ans = ans * i % pk;
return ans * fac(n / p, p, pk) % pk;
}
int inv(const int a, const int p) {
int x, y;
exgcd(a, p, x, y);
return (x % p + p) % p;
}
int C(const int n, const int m, const int p, const int pk) {
if (n < m)
return 0;
int f1 = fac(n, p, pk), f2 = fac(m, p, pk), f3 = fac(n - m, p, pk), cnt = 0;
for (int i = n; i; i /= p)
cnt += i / p;
for (int i = m; i; i /= p)
cnt -= i / p;
for (int i = n - m; i; i /= p)
cnt -= i / p;
return f1 * inv(f2, pk) % pk * inv(f3, pk) % pk * power(p, cnt, pk) % pk;
}
int a[N], c[N];
int cnt;
inline int CRT() {
int M = 1, ans = 0;
for (int i = 0; i < cnt; i++)
M *= c[i];
for (int i = 0; i < cnt; i++)
ans = (ans + a[i] * (M / c[i]) % M * inv(M / c[i], c[i]) % M) % M;
return ans;
}
int exlucas(const int n, const int m, int p) {
int tmp = sqrt(p);
for (int i = 2; p > 1 && i <= tmp; i++) {
int tmp = 1;
while (p % i == 0) p /= i, tmp *= i;
if (tmp > 1) a[cnt] = C(n, m, i, tmp), c[cnt++] = tmp;
}
if (p > 1) a[cnt] = C(n, m, p, p), c[cnt++] = p;
return CRT();
}
int work() {
ios::sync_with_stdio(false);
cin >> n >> m >> p;
cout << exlucas(n, m, p);
return 0;
}
}质因数分解
此法适用于: 的情况。
int n,m,p,b[10000005],prime[1000005],t,min_prime[10000005];
void euler_Prime(int n){//用欧拉筛求出1~n中每个数的最小质因数的编号是多少,保存在min_prime中
for(int i=2;i<=n;i++){
if(b[i]==0){
prime[++t]=i;
min_prime[i]=t;
}
for(int j=1;j<=t&&i*prime[j]<=n;j++){
b[prime[j]*i]=1;
min_prime[prime[j]*i]=j;
if(i%prime[j]==0) break;
}
}
}
long long c(int n,int m,int p){//计算C(n,m)%p的值
euler_Prime(n);
int a[t+5];//t代表1~n中质数的个数 ,a[i]代表编号为i的质数在答案中出现的次数
for(int i=1;i<=t;i++) a[i]=0;//注意清0,一开始是随机数
for(int i=n;i>=n-m+1;i--){//处理分子
int x=i;
while (x!=1){
a[min_prime[x]]++;//注意min_prime中保存的是这个数的最小质因数的编号(1~t)
x/=prime[min_prime[x]];
}
}
for(int i=1;i<=m;i++){//处理分母
int x=i;
while (x!=1){
a[min_prime[x]]--;
x/=prime[min_prime[x]];
}
}
long long ans=1;
for(int i=1;i<=t;i++){//枚举质数的编号,看它出现了几次
while(a[i]>0){
ans=ans*prime[i]%p;
a[i]--;
}
}
return ans;
}
int main(){
cin>>n>>m;
m=min(m,n-m);//小优化
cout<<c(n,m,MOD);
}杨辉三角(精确计算)
以内 long long 可解, 以内 __int128 可解。
vector C(n + 1, vector<int>(n + 1));
C[0][0] = 1;
for (int i = 1; i <= n; i++) {
C[i][0] = 1;
for (int j = 1; j <= n; j++) {
C[i][j] = C[i - 1][j] + C[i - 1][j - 1];
}
}
cout << C[n][m] << endl;求解连续数字的正约数集合——倍数法
使用规律递推优化,时间复杂度为 ,如果不需要详细的输出集合,则直接将 vector 换为普通数组即可(时间更快) 。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 7;
vector<int> f[N];
void divide(int n) {
for (int i = 1; i <= n; ++ i)
for (int j = 1; j <= n / i; ++ j)
f[i * j].push_back(i);
for (int i = 1; i <= n; ++ i) {
for (auto it : f[i]) cout << it << " ";
cout << endl;
}
}
int main() {
int x; cin >> x; divide(x);
return 0;
}容斥原理
定义:
例题:给定一个整数 和 个不同的质数 ,请你求出 1 ∼ 中能被 中的至少一个数整除的整数有多少个。
二进制枚举解
int main(){
ios::sync_with_stdio(false);cin.tie(0);
LL n, m;
cin >> n >> m;
vector<LL> p(m);
for (int i = 0; i < m; i ++) cin >> p[i];
LL ans = 0;
for (int i = 1; i < (1 << m); i ++ ){
LL t = 1, cnt = 0;
for (int j = 0; j < m; j ++ ){
if (i >> j & 1){
cnt ++ ;
t *= p[j];
if (t > n){
t = -1;
break;
}
}
}
if (t != -1){
if (cnt & 1) ans += n / t;
else ans -= n / t;
}
}
cout << ans << "\n";
return 0;
}dfs 解
int main(){
ios::sync_with_stdio(false);cin.tie(0);
LL n, m;
cin >> n >> m;
vector <LL> p(m);
for (int i = 0; i < m; i ++ )
cin >> p[i];
LL ans = 0;
function<void(LL, LL, LL)> dfs = [&](LL x, LL s, LL odd){
if (x == m){
if (s == 1) return;
ans += odd * (n / s);
return;
}
dfs(x + 1, s, odd);
if (s <= n / p[x]) dfs(x + 1, s * p[x], -odd);
};
dfs(0, 1, -1);
cout << ans << "\n";
return 0;
}同余方程组、拓展中国剩余定理 excrt
公式: ,即 。
int n; LL ai[maxn], bi[maxn];
inline int mypow(int n, int k, int p) {
int r = 1;
for (; k; k >>= 1, n = n * n % p)
if (k & 1) r = r * n % p;
return r;
}
LL exgcd(LL a, LL b, LL &x, LL &y) {
if (b == 0) { x = 1, y = 0; return a; }
LL gcd = exgcd(b, a % b, x, y), tp = x;
x = y, y = tp - a / b * y;
return gcd;
}
LL excrt() {
LL x, y, k;
LL M = bi[1], ans = ai[1];
for (int i = 2; i <= n; ++ i) {
LL a = M, b = bi[i], c = (ai[i] - ans % b + b) % b;
LL gcd = exgcd(a, b, x, y), bg = b / gcd;
if (c % gcd != 0) return -1;
x = mul(x, c / gcd, bg);
ans += x * M;
M *= bg;
ans = (ans % M + M) % M;
}
return (ans % M + M) % M;
}
int main() {
cin >> n;
for (int i = 1; i <= n; ++ i) cin >> bi[i] >> ai[i];
cout << excrt() << endl;
return 0;
}求解连续按位异或
以 复杂度计算 。
unsigned xor_n(unsigned n) {
unsigned t = n & 3;
if (t & 1) return t / 2u ^ 1;
return t / 2u ^ n;
}i64 xor_n(i64 n) {
if (n % 4 == 1) return 1;
else if (n % 4 == 2) return n + 1;
else if (n % 4 == 3) return 0;
else return n;
}高斯消元求解线性方程组
题目大意:输入一个包含 个方程 个未知数的线性方程组,系数与常数均为实数(两位小数)。求解这个方程组。如果存在唯一解,则输出所有 个未知数的解,结果保留两位小数。如果无数解,则输出 ,如果无解,则输出 。
const int N = 110;
const double eps = 1e-8;
LL n;
double a[N][N];
LL gauss(){
LL c, r;
for (c = 0, r = 0; c < n; c ++ ){
LL t = r;
for (int i = r; i < n; i ++ ) //找到绝对值最大的行
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int j = c; j < n + 1; j ++ ) swap(a[t][j], a[r][j]); //将绝对值最大的一行换到最顶端
for (int j = n; j >= c; j -- ) a[r][j] /= a[r][c]; //将当前行首位变成 1
for (int i = r + 1; i < n; i ++ ) //将下面列消成 0
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n){
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps)
return 2;
return 1;
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0;
}
int main(){
cin >> n;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < n + 1; j ++ )
cin >> a[i][j];
LL t = gauss();
if (t == 0){
for (int i = 0; i < n; i ++ ){
if (fabs(a[i][n]) < eps) a[i][n] = abs(a[i][n]);
printf("%.2lf\n", a[i][n]);
}
}
else if (t == 1) cout << "Infinite group solutions\n";
else cout << "No solution\n";
return 0;
}康拓展开
正向展开普通解法
将一个字典序排列转换成序号。例如:12345->1,12354->2。
int f[20];
void jie_cheng(int n) { // 打出1-n的阶乘表
f[0] = f[1] = 1; // 0的阶乘为1
for (int i = 2; i <= n; i++) f[i] = f[i - 1] * i;
}
string str;
int kangtuo() {
int ans = 1; // 注意,因为 12345 是算作0开始计算的,最后结果要把12345看作是第一个
int len = str.length();
for (int i = 0; i < len; i++) {
int tmp = 0; // 用来计数的
// 计算str[i]是第几大的数,或者说计算有几个比他小的数
for (int j = i + 1; j < len; j++)
if (str[i] > str[j]) tmp++;
ans += tmp * f[len - i - 1];
}
return ans;
}
int main() {
jie_cheng(10);
string str = "52413";
cout << kangtuo() << endl;
}正向展开树状数组解
给定一个全排列,求出它是 1 ~ 所有全排列的第几个,答案对 取模。
答案就是 。 表示剩下的比 小的数字的数量,通过树状数组处理。
#include <bits/stdc++.h>
using namespace std;
#define LL long long
const int mod = 998244353, N = 1e6 + 10;
LL fact[N];
struct fwt{
LL n;
vector <LL> a;
fwt(LL n) : n(n), a(n + 1) {}
LL sum(LL x){
LL res = 0;
for (; x; x -= x & -x)
res += a[x];
return res;
}
void add(LL x, LL k){
for (; x <= n; x += x & -x)
a[x] += k;
}
LL query(LL x, LL y){
return sum(y) - sum(x - 1);
}
};
int main(){
ios::sync_with_stdio(false);cin.tie(0);
LL n;
cin >> n;
fwt a(n);
fact[0] = 1;
for (int i = 1; i <= n; i ++ ){
fact[i] = fact[i - 1] * i % mod;
a.add(i, 1);
}
LL ans = 0;
for (int i = 1; i <= n; i ++ ){
LL x;
cin >> x;
ans = (ans + a.query(1, x - 1) * fact[n - i] % mod ) % mod;
a.add(x, -1);
}
cout << (ans + 1) % mod << "\n";
return 0;
}逆向还原
string str;
int kangtuo(){
int ans = 1; //注意,因为 12345 是算作0开始计算的,最后结果要把12345看作是第一个
int len = str.length();
for(int i = 0; i < len; i++){
int tmp = 0;//用来计数的
for(int j = i + 1; j < len; j++){
if(str[i] > str[j]) tmp++;
//计算str[i]是第几大的数,或者说计算有几个比他小的数
}
ans += tmp * f[len - i - 1];
}
return ans;
}
int main(){
jie_cheng(10);
string str = "52413";
cout<<kangtuo()<<endl;
}Min25 筛
求解 的质数和,其中 。
namespace min25{
const int N = 1000000 + 10;
int prime[N], id1[N], id2[N], flag[N], ncnt, m;
LL g[N], sum[N], a[N], T;
LL n;
LL mod;
inline LL ps(LL n,LL k) {LL r=1;for(;k;k>>=1){if(k&1)r=r*n%mod;n=n*n%mod;}return r;}
void finit(){ // 最开始清0
memset(g, 0, sizeof(g));
memset(a, 0, sizeof(a));
memset(sum, 0, sizeof(sum));
memset(prime, 0, sizeof(prime));
memset(id1, 0, sizeof(id1));
memset(id2, 0, sizeof(id2));
memset(flag, 0, sizeof(flag));
ncnt = m = 0;
}
int ID(LL x) {
return x <= T ? id1[x] : id2[n / x];
}
LL calc(LL x) {
return x * (x + 1) / 2 - 1;
}
LL init(LL x) {
T = sqrt(x + 0.5);
for (int i = 2; i <= T; i++) {
if (!flag[i]) prime[++ncnt] = i, sum[ncnt] = sum[ncnt - 1] + i;
for (int j = 1; j <= ncnt && i * prime[j] <= T; j++) {
flag[i * prime[j]] = 1;
if (i % prime[j] == 0) break;
}
}
for (LL l = 1; l <= x; l = x / (x / l) + 1) {
a[++m] = x / l;
if (a[m] <= T) id1[a[m]] = m; else id2[x / a[m]] = m;
g[m] = calc(a[m]);
}
for (int i = 1; i <= ncnt; i++)
for (int j = 1; j <= m && (LL) prime[i] * prime[i] <= a[j]; j++)
g[j] = g[j] - (LL) prime[i] * (g[ID(a[j] / prime[i])] - sum[i - 1]);
}
LL solve(LL x) {
if (x <= 1) return x;
return n = x, init(n), g[ID(n)];
}
}
using namespace min25;
int main() {
// while (1) {
int tt;
scanf("%d",&tt);
while(tt--){
finit();
scanf("%lld%lld", &n, &mod);
LL ans = (n + 3) % mod * n % mod * ps(2 , mod - 2) % mod + solve(n + 1) - 4;
// cout << solve(n) << endl;
// ans = (ans + mod) % mod;
ans = (ans + mod) % mod;
printf("%lld\n", ans);
}
// }
}矩阵四则运算
封装来自 。矩阵乘法复杂度 。
const int SIZE = 2;
struct Matrix {
ll M[SIZE + 5][SIZE + 5];
void clear() { memset(M, 0, sizeof(M)); }
void reset() { //初始化
clear();
for (int i = 1; i <= SIZE; ++i) M[i][i] = 1;
}
Matrix friend operator*(const Matrix &A, const Matrix &B) {
Matrix Ans;
Ans.clear();
for (int i = 1; i <= SIZE; ++i)
for (int j = 1; j <= SIZE; ++j)
for (int k = 1; k <= SIZE; ++k)
Ans.M[i][j] = (Ans.M[i][j] + A.M[i][k] * B.M[k][j]) % mod;
return Ans;
}
Matrix friend operator+(const Matrix &A, const Matrix &B) {
Matrix Ans;
Ans.clear();
for (int i = 1; i <= SIZE; ++i)
for (int j = 1; j <= SIZE; ++j)
Ans.M[i][j] = (A.M[i][j] + B.M[i][j]) % mod;
return Ans;
}
};
inline int mypow(LL n, LL k, int p = MOD) {
LL r = 1;
for (; k; k >>= 1, n = n * n % p) {
if (k & 1) r = r * n % p;
}
return r;
}
bool ok = 1;
Matrix getinv(Matrix a) { //矩阵求逆
int n = SIZE, m = SIZE * 2;
for (int i = 1; i <= n; i++) a.M[i][i + n] = 1;
for (int i = 1; i <= n; i++) {
int pos = i;
for (int j = i + 1; j <= n; j++)
if (abs(a.M[j][i]) > abs(a.M[pos][i])) pos = j;
if (i != pos) swap(a.M[i], a.M[pos]);
if (!a.M[i][i]) {
puts("No Solution");
ok = 0;
}
ll inv = q_pow(a.M[i][i], mod - 2);
for (int j = 1; j <= n; j++)
if (j != i) {
ll mul = a.M[j][i] * inv % mod;
for (int k = i; k <= m; k++)
a.M[j][k] = ((a.M[j][k] - a.M[i][k] * mul) % mod + mod) % mod;
}
for (int j = 1; j <= m; j++) a.M[i][j] = a.M[i][j] * inv % mod;
}
Matrix res;
res.clear();
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
res.M[i][j] = a.M[i][n + j];
return res;
}矩阵快速幂
以 的复杂度计算。
const int N = 110, mod = 1e9 + 7;
LL n, k, a[N][N], b[N][N], t[N][N];
void matrixQp(LL y){
while (y){
if (y & 1){
memset(t, 0, sizeof t);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
for (int k = 1; k <= n; k ++ )
t[i][j] = ( t[i][j] + (a[i][k] * b[k][j]) % mod ) % mod;
memcpy(b, t, sizeof t);
}
y >>= 1;
memset(t, 0, sizeof t);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
for (int k = 1; k <= n; k ++ )
t[i][j] = ( t[i][j] + (a[i][k] * a[k][j]) % mod ) % mod;
memcpy(a, t, sizeof t);
}
}
int main(){
cin >> n >> k;
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ ){
cin >> b[i][j];
a[i][j] = b[i][j];
}
matrixQp(k - 1);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
cout << b[i][j] << " \n"[j == n];
return 0;
}莫比乌斯函数/反演
莫比乌斯函数定义: 。
莫比乌斯函数性质:对于任意正整数 满足 ; 。
莫比乌斯反演定义:定义: 和 是定义在非负整数集合上的两个函数,并且满足 ,可得 。
const int N = 5e4 + 10;
bool st[N];
int mu[N], prime[N], cnt, sum[N];
void getMu() {
mu[1] = 1;
for (int i = 2; i <= N - 10; i++) {
if (!st[i]) {
prime[++cnt] = i;
mu[i] = -1;
}
for (int j = 1; j <= cnt && i * prime[j] <= N - 10; j++) {
st[i * prime[j]] = true;
if (i % prime[j] == 0) {
mu[i * prime[j]] = 0;
break;
}
mu[i * prime[j]] = -mu[i];
}
}
for (int i = 1; i <= N - 10; i++) {
sum[i] = sum[i - 1] + mu[i];
}
}
void solve() {
int n, m, k; cin >> n >> m >> k;
n = n / k, m = m / k;
if (n < m) swap(n, m);
LL ans = 0;
for (int i = 1, j = 0; i <= m; i = j + 1) {
j = min(n / (n / i), m / (m / i));
ans += (LL)(sum[j] - sum[i - 1]) * (n / i) * (m / i);
}
cout << ans << "\n";
}
int main() {
getMu();
int T; cin >> T;
while (T--) solve();
}整除(数论)分块
向下取整
,根据不等式左侧,得到 。
void solve() {
LL n; cin >> n;
LL ans = 0;
for (LL i = 1, j; i <= n; i = j + 1) {
j = n / (n / i);
ans += (LL)(j - i + 1) * (n / i);
}
cout << ans << "\n";
}
int main() {
int T; cin >> T;
while (T--) solve();
}向上取整
注意特判的情况!!!
for (int l = 1, r, k; r <= n; l = r + 1) {
k = (n + l - 1) / l;
r = k == 1 ? n : (n - 1) / (k - 1);
}常见结论
球盒模型
参考链接。给定 个小球 个盒子。
- 球同,盒不同、不能空
隔板法: 个小球即一共 个空,分成 堆即 个隔板,答案为 。
- 球同,盒不同、能空
隔板法:多出 个虚空球,答案为 。
- 球同,盒同、能空
的 项的系数。动态规划,答案为
- 球同,盒同、不能空
的 项的系数。动态规划,答案为
- 球不同,盒同、不能空
第二类斯特林数 ,答案为
- 球不同,盒同、能空
第二类斯特林数之和 ,答案为 。
- 球不同,盒不同、不能空
第二类斯特林数乘上 的阶乘 ,答案为 。
- 球不同,盒不同、能空
答案为 。
i64 mypow(i64 n, i64 k) { // 复杂度是 log N
i64 r = 1;
for (; k; k >>= 1, n *= n) {
if (k & 1) r *= n;
}
return r;
}
vector<vector<i64>> comb;
void YangHuiTriangle(int n = 60) {
comb.resize(n + 1, vector<i64>(n + 1));
comb[0][0] = 1;
for (int i = 1; i <= n; i++) {
comb[i][0] = 1;
for (int j = 1; j <= n; j++) {
comb[i][j] = comb[i - 1][j] + comb[i - 1][j - 1];
}
}
}
vector<vector<i64>> S;
void Stirling2(int n = 15) {
S.resize(n + 1, vector<i64>(n + 1));
S[1][1] = 1;
for (int i = 2; i <= 15; i++) {
for (int j = 1; j <= i; j++) {
S[i][j] = S[i - 1][j - 1] + S[i - 1][j] * j;
}
}
}
vector<vector<i64>> dp;
void GeneratingFunction(int n = 15) {
dp.resize(n + 1, vector<i64>(n + 1));
for (int i = 0; i <= n; i++) {
dp[i][1] = 1;
for (int j = 2; j <= n; j++) {
dp[i][j] = dp[i][j - 1];
if (i >= j) dp[i][j] += dp[i - j][j];
}
}
}
vector<i64> fac;
void Fac(int n = 30) {
fac.resize(n + 1);
fac[0] = 1;
for (int i = 1; i <= n; i++) {
fac[i] = fac[i - 1] * i;
}
}
i64 A(int n, int m) {
if (n < 0 || m < 0 || n < m) return 0;
return fac[n] / fac[n - m];
}
i64 C(int n, int m) {
if (n < 0 || m < 0 || n < m) return 0;
return comb[n][m];
}
signed main() {
int Task = 1;
for (cin >> Task; Task; Task--) {
int op, n, m;
cin >> op >> n >> m;
i64 ans = -1;
if (op == 1) { // 球同,盒同、能空
ans = dp[n][m];
} else if (op == 2) { // 球同,盒同、至多放一个
ans = (n <= m);
} else if (op == 3) { // 球同,盒同、至少放一个
ans = (n < m ? 0 : dp[n - m][m]);
} else if (op == 4) { // 球同,盒不同、能空
ans = C(m - 1 + n, n);
} else if (op == 5) { // 球同,盒不同、至多放一个
ans = C(m, n);
} else if (op == 6) { // 球同,盒不同、至少放一个
ans = C(n - 1, m - 1);
} else if (op == 7) { // 球不同,盒同、能空
ans = accumulate(S[n].begin() + 1, S[n].begin() + m + 1, 0LL);
} else if (op == 8) { // 球不同,盒同、至多放一个
ans = (n <= m);
} else if (op == 9) { // 球不同,盒同、至少放一个
ans = S[n][m];
} else if (op == 10) { // 球不同,盒不同、能空
ans = mypow(m, n);
} else if (op == 11) { // 球不同,盒不同、至多放一个
ans = A(m, n);
} else if (op == 12) { // 球不同,盒不同、至少放一个
ans = fac[m] * S[n][m];
}
cout << ans << "\n";
}
}麦乐鸡定理
给定两个互质的数 ,定义 ,当 时,该式子恒成立。
抽屉原理(鸽巢原理)
将 个物体,划分为 组,那么有至少一组有两个(或以上)的物体。
哥德巴赫猜想
任何一个大于 的整数都可写成三个质数之和;任何一个大于 的偶数都可写成两个素数之和。
弱哥德巴赫猜想
任何一个大于7的奇数都能被表示成三个奇质数的和。(一个质数可以被多次使用)
除法、取模运算的本质
有公式: , 。
与、或、异或
| 运算 | 运算符、数学符号表示 | 解释 |
|---|---|---|
| 与 | &、and | 同1出1 |
| 或 | |、or | 有1出1 |
| 异或 | ^、、xor | 不同出1 |
一些结论:
对于给定的 和序列 ,有: 。
原理是 意味着取交集, 意味着取子集。来源 - 牛客小白月赛49C
调和级数近似公式
log(n) + 0.5772156649 + 1.0 / (2 * n)欧拉函数常见性质
中与 互质的数之和为 。$ (!!!!!!!)$
若 互质,则 。实际上,所有满足这一条件的函数统称为积性函数。
若 不互质,则
若 是积性函数,且有 ,那么 。
若 为质数,且满足 ,
- ,那么 。
- ,那么 。
。
如 ,则 ,那么 。
(欧拉反演)。
组合数学常见性质
- ;
- ;
- ;
- ;
- 。
- 二项式反演:$\left{\begin{matrix} \displaystyle f_n=\sum_{i=0}^n{n\choose i}g_i\Leftrightarrow g_n=\sum_{i=0}n(-1){n\choose i}f_i \
\displaystyle f_k=\sum_{i=k}^n{i\choose k}g_i\Leftrightarrow g_k=\sum_{i=k}n(-1){i\choose k}f_i \end{matrix}\right. $ ; - ;
- ;
- ;
- ;
- 拉格朗日恒等式: 。
- 为奇数 当且仅当
- : 含 的次数是
- : 含 的次数是 在 进制下的进位数
范德蒙德卷积公式
在数量为 的堆中选 个元素,和分别在数量为 的堆中选 个元素的方案数是相同的,即 ;
变体:
- ;
- 。
卡特兰数
是一类奇特的组合数,前几项为 。如遇到以下问题,则直接套用即可。
- 【括号匹配问题】 个左括号和 个右括号组成的合法括号序列的数量,为 。
- 【进出栈问题】 经过一个栈,形成的合法出栈序列的数量,为 。
- 【二叉树生成问题】 个节点构成的不同二叉树的数量,为 。
- 【路径数量问题】在平面直角坐标系上,每一步只能向上或向右走,从 走到 ,并且除两个端点外不接触直线 的路线数量,为 。
计算公式: , 。
狄利克雷卷积
, 。
若f g均为积性函数,对于该卷积$(f*g)(n) = \displaystyle \sum_{d|n} f(d) g(\frac{n}{d}) $称为狄利克雷卷积。
1. 是积性函数
斐波那契数列
通项公式: 。
直接结论:
- 卡西尼性质: ;
- ;
- (由上一条写两遍相减得到);
- 若存在序列 则 ;
- 齐肯多夫定理:任何正整数都可以表示成若干个不连续的斐波那契数( 开始)可以用贪心实现。
求和公式结论:
- 奇数项求和: ;
- 偶数项求和: ;
- 平方和: ;
- ;
- ;
- 。
数论结论:
- ;
- ;
- 当 为 型素数时, ;
- 当 为 型素数时, ;
- 的周期 ( 时取到等号);
- 既是斐波那契数又是平方数的有且仅有 。
曼哈顿与切比雪夫距离
曼哈顿:
切比雪夫: $d(x1,y1,x2,y2) = max(|x_1- x_2| , |y_1 - y_2|) $
曼哈顿距离 切比雪夫距离
切比雪夫距离 曼哈顿距离
摩尔投票
摩尔投票 :(n个数,每次将两个不同的数两两相消,问最少剩下多少个数?)
1.存在绝对众数则剩下的数一定是绝对众数 (绝对众数:某个数的数量严格大于其余数的总个数)(cnt > sum - cnt)
2.不存在绝对众数则与总和的奇偶有关->奇数留下一个(绝对众数),偶数恰好全消完杂
负数取模得到的是负数,如果要用 判断的话请取绝对值;
辗转相除法原式为 ,推广到 项为 ,
- 该推论在“四则运算后 ”这类题中有特殊意义,如求解 时See;
以下式子成立: 。求解上式满足条件的 的数量即为求比 小且与其互质的数的个数,即用欧拉函数求解 。
已知序列 ,定义集合 ,现在要求解 ,即为求解 ,换句话说,即为求解后缀 。
连续四个数互质的情况如下,当 为奇数时, 一定互质;而当 为偶数时, See;
由 可以推广得到 ,由此可以得到一个 的答案周期See;
对于长度为 的数列 ,将其任意均分为两个长度为 的数列 ,随后对 非递减排序、对 非递增排序,定义 ,那么答案为 数列前 大的数之和减去前 小的数之和See。
令 ,如果该式子有解,那么存在前提条件 ;进一步,此时最小的 的取值为 See。
然而,上方方程并不总是有解的,只有当变量增加到三个时,才一定有解,即:在保证上方前提条件成立的情况下,求解 ,则一定存在一组解 See。
已知序列 是由序列 、序列 、……、序列 合并而成,且合并过程中各序列内元素相对顺序不变,记 是 序列的最大前缀和,则 See 。
,对于两个数字 和 ,如果将 变为 ,同时将 变为 ,那么在本质上即将 二进制模式下的全部 移动到了 的对应的位置上 See 。
一个正整数 异或、加上另一个正整数 后奇偶性不发生变化: See 。
常见例题
题意:将 至 的每个数字分组,使得每一组的数字之和均为质数。输出每一个数字所在的组别,且要求分出的组数最少 See 。
考察哥德巴赫猜想,记全部数字之和为 ,分类讨论如下:
- 为 质数时,只需要分入同一组;
- 当 为偶数时,由猜想可知一定能分成两个质数,可以证明其中较小的那个一定小于 ,暴力枚举分组;
- 当 为质数时,特殊判断出答案;
- 其余情况一定能被分成三组,其中 单独成组, 后成为偶数,重复讨论二的过程即可。
题意:给定一个长度为 的数组,定义这个数组是 的,当且仅当可以把数组分成两个子序列,这两个子序列的元素之和相等。现在你需要删除最少的元素,使得删除后的数组不是 的。
最少删除一个元素——如果原数组存在奇数,则直接删除这个奇数即可;反之,我们发现,对数列同除以一个数不影响计算,故我们只需要找到最大的满足 成立的 ,随后将全部的 变为 ,此时一定有一个奇数(换句话说,我们可以对原数列的每一个元素不断的除以 直到出现奇数为止),删除这个奇数即可 See 。
题意:设当前有一个数字为 ,减去、加上最少的数字使得其能被 整除。
最少减去 这个很好想;最少加上 也比较好想,但是更简便的方法为加上 ,这个式子等价于前面这一坨。
题意:给定一个整数 ,用恰好 个 的幂次数之和表示它。例如: ,答案为 。
结论1: 合法当且仅当 __builtin_popcountll(n) <= k && k <= n ,显然。
结论2: ,所以我们可以将二进制位看作是数组,然后从高位向低位推,一个高位等于两个低位,直到数组之和恰好等于 ,随后依次输出即可。举例说明, ,即答案为 个 、 个 、……。
signed main() {
int n, k;
cin >> n >> k;
int cnt = __builtin_popcountll(n);
if (k < cnt || n < k) {
cout << "NO\n";
return 0;
}
cout << "YES\n";
vector<int> num;
while (n) {
num.push_back(n % 2);
n /= 2;
}
for (int i = num.size() - 1; i > 0; i--) {
int p = min(k - cnt, num[i]);
num[i] -= p;
num[i - 1] += 2 * p;
cnt += p;
}
for (int i = 0; i < num.size(); i++) {
for (int j = 1; j <= num[i]; j++) {
cout << (1LL << i) << " ";
}
}
}题意: 个取值在 之间的数之和为 的方案数
Z clac(int n, int k, int m) {
Z ans = 0;
ans += C(n, i) * C(m - i * k + n - 1, n - 1) * pow(-1, i);
}
return ans;
} 先考虑没有 的限制,那么即球盒模型: 个球放入 个盒子,球同、盒子不同、能空。使用隔板法得到公式:C(m + n - 1, n - 1) ; 下面加上取值范围后进一步考虑:假设现在 个数之和为 ,运用上述隔板法可得公式:C(m - k + n - 1, n - 1) ; 随后,选择任意一个数字,将其加上 ,这样,这个数字一定不满足条件,选法为:C(n, 1) ; 此时,至少有一个数字是不满足条件的,按照一般流程,到这里,C(m + n - 1, n - 1) - C(n, 1) * C(m - k + n - 1, n - 1) 即是答案;但是,这样的操作会导致重复的部分,所以这里要使用容斥原理将重复部分去除(关于为什么会重复,试比较概率论中的加法公式)。
几何
库实数类实现(双精度)
using Real = int;
using Point = complex<Real>;
Real cross(const Point &a, const Point &b) {
return (conj(a) * b).imag();
}
Real dot(const Point &a, const Point &b) {
return (conj(a) * b).real();
}平面几何必要初始化
字符串读入浮点数
const int Knum = 4;
int read(int k = Knum) {
string s;
cin >> s;
int num = 0;
int it = s.find('.');
if (it != -1) { // 存在小数点
num = s.size() - it - 1; // 计算小数位数
s.erase(s.begin() + it); // 删除小数点
}
for (int i = 1; i <= k - num; i++) { // 补全小数位数
s += '0';
}
return stoi(s);
}预置函数
using ld = long double;
const ld PI = acos(-1);
const ld EPS = 1e-7;
const ld INF = numeric_limits<ld>::max();
#define cc(x) cout << fixed << setprecision(x);
ld fgcd(ld x, ld y) { // 实数域gcd
return abs(y) < EPS ? abs(x) : fgcd(y, fmod(x, y));
}
template<class T, class S> bool equal(T x, S y) {
return -EPS < x - y && x - y < EPS;
}
template<class T> int sign(T x) {
if (-EPS < x && x < EPS) return 0;
return x < 0 ? -1 : 1;
}点线封装
template<class T> struct Point { // 在C++17下使用 emplace_back 绑定可能会导致CE!
T x, y;
Point(T x_ = 0, T y_ = 0) : x(x_), y(y_) {} // 初始化
template<class U> operator Point<U>() { // 自动类型匹配
return Point<U>(U(x), U(y));
}
Point &operator+=(Point p) & { return x += p.x, y += p.y, *this; }
Point &operator+=(T t) & { return x += t, y += t, *this; }
Point &operator-=(Point p) & { return x -= p.x, y -= p.y, *this; }
Point &operator-=(T t) & { return x -= t, y -= t, *this; }
Point &operator*=(T t) & { return x *= t, y *= t, *this; }
Point &operator/=(T t) & { return x /= t, y /= t, *this; }
Point operator-() const { return Point(-x, -y); }
friend Point operator+(Point a, Point b) { return a += b; }
friend Point operator+(Point a, T b) { return a += b; }
friend Point operator-(Point a, Point b) { return a -= b; }
friend Point operator-(Point a, T b) { return a -= b; }
friend Point operator*(Point a, T b) { return a *= b; }
friend Point operator*(T a, Point b) { return b *= a; }
friend Point operator/(Point a, T b) { return a /= b; }
friend bool operator<(Point a, Point b) {
return equal(a.x, b.x) ? a.y < b.y - EPS : a.x < b.x - EPS;
}
friend bool operator>(Point a, Point b) { return b < a; }
friend bool operator==(Point a, Point b) { return !(a < b) && !(b < a); }
friend bool operator!=(Point a, Point b) { return a < b || b < a; }
friend auto &operator>>(istream &is, Point &p) {
return is >> p.x >> p.y;
}
friend auto &operator<<(ostream &os, Point p) {
return os << "(" << p.x << ", " << p.y << ")";
}
};
template<class T> struct Line {
Point<T> a, b;
Line(Point<T> a_ = Point<T>(), Point<T> b_ = Point<T>()) : a(a_), b(b_) {}
template<class U> operator Line<U>() { // 自动类型匹配
return Line<U>(Point<U>(a), Point<U>(b));
}
friend auto &operator<<(ostream &os, Line l) {
return os << "<" << l.a << ", " << l.b << ">";
}
};叉乘
定义公式 。
template<class T> T cross(Point<T> a, Point<T> b) { // 叉乘
return a.x * b.y - a.y * b.x;
}
template<class T> T cross(Point<T> p1, Point<T> p2, Point<T> p0) { // 叉乘 (p1 - p0) x (p2 - p0);
return cross(p1 - p0, p2 - p0);
}点乘
定义公式 。
template<class T> T dot(Point<T> a, Point<T> b) { // 点乘
return a.x * b.x + a.y * b.y;
}
template<class T> T dot(Point<T> p1, Point<T> p2, Point<T> p0) { // 点乘 (p1 - p0) * (p2 - p0);
return dot(p1 - p0, p2 - p0);
}欧几里得距离公式
最常用的距离公式。需要注意,开根号会丢失精度,如无强制要求,先不要开根号,留到最后一步一起开。
template <class T> ld dis(T x1, T y1, T x2, T y2) {
ld val = (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2);
return sqrt(val);
}
template <class T> ld dis(Point<T> a, Point<T> b) {
return dis(a.x, a.y, b.x, b.y);
}曼哈顿距离公式
template <class T> T dis1(Point<T> p1, Point<T> p2) { // 曼哈顿距离公式
return abs(p1.x - p2.x) + abs(p1.y - p2.y);
}将向量转换为单位向量
Point<ld> standardize(Point<ld> vec) { // 转换为单位向量
return vec / sqrt(vec.x * vec.x + vec.y * vec.y);
}向量旋转
将当前向量移动至原点后顺时针旋转 ,即获取垂直于当前向量的、起点为原点的向量。在计算垂线时非常有用。例如,要想获取点 绕点 顺时针旋转 后的点,可以这样书写代码:auto ans = o + rotate(o, a); ;如果是逆时针旋转,那么只需更改符号即可:auto ans = o - rotate(o, a); 。
template<class T> Point<T> rotate(Point<T> p1, Point<T> p2) { // 旋转
Point<T> vec = p1 - p2;
return {-vec.y, vec.x};
}平面角度与弧度
弧度角度相互转换
ld toDeg(ld x) { // 弧度转角度
return x * 180 / PI;
}
ld toArc(ld x) { // 角度转弧度
return PI / 180 * x;
}正弦定理
,其中 为三角形外接圆半径;
余弦定理(已知三角形三边,求角)
。可以借此推导出三角形面积公式 。
注意,计算格式是:由 三边求 ;由 三边求 ;由 三边求 。
ld angle(ld a, ld b, ld c) { // 余弦定理
ld val = acos((a * a + b * b - c * c) / (2.0 * a * b)); // 计算弧度
return val;
}求两向量的夹角
能够计算 区间的角度。
ld angle(Point<ld> a, Point<ld> b) {
ld val = abs(cross(a, b));
return abs(atan2(val, a.x * b.x + a.y * b.y));
}向量旋转任意角度
逆时针旋转,转换公式:
Point<ld> rotate(Point<ld> p, ld rad) {
return {p.x * cos(rad) - p.y * sin(rad), p.x * sin(rad) + p.y * cos(rad)};
}点绕点旋转任意角度
逆时针旋转,转换公式:
Point<ld> rotate(Point<ld> a, Point<ld> b, ld rad) { // a点绕b点逆时针旋转任意角度
ld x = (a.x - b.x) * cos(rad) - (a.y - b.y) * sin(rad) + b.x;
ld y = (a.x - b.x) * sin(rad) + (a.y - b.y) * cos(rad) + b.y;
return {x, y};
}平面点线相关
点是否在直线上(三点是否共线)
template<class T> bool onLine(Point<T> a, Point<T> b, Point<T> c) {
return sign(cross(b, a, c)) == 0;
}
template<class T> bool onLine(Point<T> p, Line<T> l) {
return onLine(p, l.a, l.b);
}点是否在向量(直线)左侧
需要注意,向量的方向会影响答案;点在向量上时不视为在左侧。
template<class T> bool pointOnLineLeft(Pt p, Lt l) {
return cross(l.b, p, l.a) > 0;
}两点是否在直线同侧/异侧
template<class T> bool pointOnLineSide(Pt p1, Pt p2, Lt vec) {
T val = cross(p1, vec.a, vec.b) * cross(p2, vec.a, vec.b);
return sign(val) == 1;
}
template<class T> bool pointNotOnLineSide(Pt p1, Pt p2, Lt vec) {
T val = cross(p1, vec.a, vec.b) * cross(p2, vec.a, vec.b);
return sign(val) == -1;
}两直线相交交点
在使用前需要先判断直线是否平行。
Pd lineIntersection(Ld l1, Ld l2) {
ld val = cross(l2.b - l2.a, l1.a - l2.a) / cross(l2.b - l2.a, l1.a - l1.b);
return l1.a + (l1.b - l1.a) * val;
}两直线是否平行/垂直/相同
template<class T> bool lineParallel(Lt p1, Lt p2) {
return sign(cross(p1.a - p1.b, p2.a - p2.b)) == 0;
}
template<class T> bool lineVertical(Lt p1, Lt p2) {
return sign(dot(p1.a - p1.b, p2.a - p2.b)) == 0;
}
template<class T> bool same(Line<T> l1, Line<T> l2) {
return lineParallel(Line{l1.a, l2.b}, {l1.b, l2.a}) &&
lineParallel(Line{l1.a, l2.a}, {l1.b, l2.b}) && lineParallel(l1, l2);
}点到直线的最近距离与最近点
pair<Pd, ld> pointToLine(Pd p, Ld l) {
Pd ans = lineIntersection({p, p + rotate(l.a, l.b)}, l);
return {ans, dis(p, ans)};
}如果只需要计算最近距离,下方的写法可以减少书写的代码量,效果一致。
template<class T> ld disPointToLine(Pt p, Lt l) {
ld ans = cross(p, l.a, l.b);
return abs(ans) / dis(l.a, l.b); // 面积除以底边长
}点是否在线段上
template<class T> bool pointOnSegment(Pt p, Lt l) { // 端点也算作在直线上
return sign(cross(p, l.a, l.b)) == 0 && min(l.a.x, l.b.x) <= p.x && p.x <= max(l.a.x, l.b.x) &&
min(l.a.y, l.b.y) <= p.y && p.y <= max(l.a.y, l.b.y);
}
template<class T> bool pointOnSegment(Pt p, Lt l) { // 端点不算
return pointOnSegment(p, l) && min(l.a.x, l.b.x) < p.x && p.x < max(l.a.x, l.b.x) &&
min(l.a.y, l.b.y) < p.y && p.y < max(l.a.y, l.b.y);
}点到线段的最近距离与最近点
pair<Pd, ld> pointToSegment(Pd p, Ld l) {
if (sign(dot(p, l.b, l.a)) == -1) { // 特判到两端点的距离
return {l.a, dis(p, l.a)};
} else if (sign(dot(p, l.a, l.b)) == -1) {
return {l.b, dis(p, l.b)};
}
return pointToLine(p, l);
}点在直线上的投影点(垂足)
Pd project(Pd p, Ld l) { // 投影
Pd vec = l.b - l.a;
ld r = dot(vec, p - l.a) / (vec.x * vec.x + vec.y * vec.y);
return l.a + vec * r;
}线段的中垂线
template<class T> Lt midSegment(Lt l) {
Pt mid = (l.a + l.b) / 2; // 线段中点
return {mid, mid + rotate(l.a, l.b)};
}两线段是否相交及交点
该扩展版可以同时返回相交状态和交点,分为四种情况: 代表不相交; 代表普通相交; 代表重叠(交于两个点); 代表相交于端点。需要注意,部分运算可能会使用到直线求交点,此时务必保证变量类型为浮点数!
template<class T> tuple<int, Pt, Pt> segmentIntersection(Lt l1, Lt l2) {
auto [s1, e1] = l1;
auto [s2, e2] = l2;
auto A = max(s1.x, e1.x), AA = min(s1.x, e1.x);
auto B = max(s1.y, e1.y), BB = min(s1.y, e1.y);
auto C = max(s2.x, e2.x), CC = min(s2.x, e2.x);
auto D = max(s2.y, e2.y), DD = min(s2.y, e2.y);
if (A < CC || C < AA || B < DD || D < BB) {
return {0, {}, {}};
}
if (sign(cross(e1 - s1, e2 - s2)) == 0) {
if (sign(cross(s2, e1, s1)) != 0) {
return {0, {}, {}};
}
Pt p1(max(AA, CC), max(BB, DD));
Pt p2(min(A, C), min(B, D));
if (!pointOnSegment(p1, l1)) {
swap(p1.y, p2.y);
}
if (p1 == p2) {
return {3, p1, p2};
} else {
return {2, p1, p2};
}
}
auto cp1 = cross(s2 - s1, e2 - s1);
auto cp2 = cross(s2 - e1, e2 - e1);
auto cp3 = cross(s1 - s2, e1 - s2);
auto cp4 = cross(s1 - e2, e1 - e2);
if (sign(cp1 * cp2) == 1 || sign(cp3 * cp4) == 1) {
return {0, {}, {}};
}
// 使用下方函数时请使用浮点数
Pd p = lineIntersection(l1, l2);
if (sign(cp1) != 0 && sign(cp2) != 0 && sign(cp3) != 0 && sign(cp4) != 0) {
return {1, p, p};
} else {
return {3, p, p};
}
}如果不需要求交点,那么使用快速排斥+跨立实验即可,其中重叠、相交于端点均视为相交。
template<class T> bool segmentIntersection(Lt l1, Lt l2) {
auto [s1, e1] = l1;
auto [s2, e2] = l2;
auto A = max(s1.x, e1.x), AA = min(s1.x, e1.x);
auto B = max(s1.y, e1.y), BB = min(s1.y, e1.y);
auto C = max(s2.x, e2.x), CC = min(s2.x, e2.x);
auto D = max(s2.y, e2.y), DD = min(s2.y, e2.y);
return A >= CC && B >= DD && C >= AA && D >= BB &&
sign(cross(s1, s2, e1) * cross(s1, e1, e2)) == 1 &&
sign(cross(s2, s1, e2) * cross(s2, e2, e1)) == 1;
}平面圆相关(浮点数处理)
点到圆的最近点
同时返回最近点与最近距离。需要注意,当点为圆心时,这样的点有无数个,此时我们视作输入错误,直接返回圆心。
pair<Pd, ld> pointToCircle(Pd p, Pd o, ld r) {
Pd U = o, V = o;
ld d = dis(p, o);
if (sign(d) == 0) { // p 为圆心时返回圆心本身
return {o, 0};
}
ld val1 = r * abs(o.x - p.x) / d;
ld val2 = r * abs(o.y - p.y) / d * ((o.x - p.x) * (o.y - p.y) < 0 ? -1 : 1);
U.x += val1, U.y += val2;
V.x -= val1, V.y -= val2;
if (dis(U, p) < dis(V, p)) {
return {U, dis(U, p)};
} else {
return {V, dis(V, p)};
}
}根据圆心角获取圆上某点
将圆上最右侧的点以圆心为旋转中心,逆时针旋转 rad 度。
Point<ld> getPoint(Point<ld> p, ld r, ld rad) {
return {p.x + cos(rad) * r, p.y + sin(rad) * r};
}直线是否与圆相交及交点
代表不相交; 代表相切; 代表相交。
tuple<int, Pd, Pd> lineCircleCross(Ld l, Pd o, ld r) {
Pd P = project(o, l);
ld d = dis(P, o), tmp = r * r - d * d;
if (sign(tmp) == -1) {
return {0, {}, {}};
} else if (sign(tmp) == 0) {
return {1, P, {}};
}
Pd vec = standardize(l.b - l.a) * sqrt(tmp);
return {2, P + vec, P - vec};
}线段是否与圆相交及交点
代表不相交; 代表相切; 代表相交于一个点; 代表相交于两个点。
tuple<int, Pd, Pd> segmentCircleCross(Ld l, Pd o, ld r) {
auto [type, U, V] = lineCircleCross(l, o, r);
bool f1 = pointOnSegment(U, l), f2 = pointOnSegment(V, l);
if (type == 1 && f1) {
return {1, U, {}};
} else if (type == 2 && f1 && f2) {
return {3, U, V};
} else if (type == 2 && f1) {
return {2, U, {}};
} else if (type == 2 && f2) {
return {2, V, {}};
} else {
return {0, {}, {}};
}
}两圆是否相交及交点
代表内含; 代表相离; 代表相切; 代表相交。
tuple<int, Pd, Pd> circleIntersection(Pd p1, ld r1, Pd p2, ld r2) {
ld x1 = p1.x, x2 = p2.x, y1 = p1.y, y2 = p2.y, d = dis(p1, p2);
if (sign(abs(r1 - r2) - d) == 1) {
return {0, {}, {}};
} else if (sign(r1 + r2 - d) == -1) {
return {1, {}, {}};
}
ld a = r1 * (x1 - x2) * 2, b = r1 * (y1 - y2) * 2, c = r2 * r2 - r1 * r1 - d * d;
ld p = a * a + b * b, q = -a * c * 2, r = c * c - b * b;
ld cosa, sina, cosb, sinb;
if (sign(d - (r1 + r2)) == 0 || sign(d - abs(r1 - r2)) == 0) {
cosa = -q / p / 2;
sina = sqrt(1 - cosa * cosa);
Point<ld> p0 = {x1 + r1 * cosa, y1 + r1 * sina};
if (sign(dis(p0, p2) - r2)) {
p0.y = y1 - r1 * sina;
}
return {2, p0, p0};
} else {
ld delta = sqrt(q * q - p * r * 4);
cosa = (delta - q) / p / 2;
cosb = (-delta - q) / p / 2;
sina = sqrt(1 - cosa * cosa);
sinb = sqrt(1 - cosb * cosb);
Pd ans1 = {x1 + r1 * cosa, y1 + r1 * sina};
Pd ans2 = {x1 + r1 * cosb, y1 + r1 * sinb};
if (sign(dis(ans1, p1) - r2)) ans1.y = y1 - r1 * sina;
if (sign(dis(ans2, p2) - r2)) ans2.y = y1 - r1 * sinb;
if (ans1 == ans2) ans1.y = y1 - r1 * sina;
return {3, ans1, ans2};
}
}两圆相交面积
上述所言四种相交情况均可计算,之所以不使用三角形面积计算公式是因为在计算过程中会出现“负数”面积(扇形面积与三角形面积的符号关系会随圆的位置关系发生变化),故公式全部重新推导,这里采用的是扇形面积减去扇形内部的那个三角形的面积。
ld circleIntersectionArea(Pd p1, ld r1, Pd p2, ld r2) {
ld x1 = p1.x, x2 = p2.x, y1 = p1.y, y2 = p2.y, d = dis(p1, p2);
if (sign(abs(r1 - r2) - d) >= 0) {
return PI * min(r1 * r1, r2 * r2);
} else if (sign(r1 + r2 - d) == -1) {
return 0;
}
ld theta1 = angle(r1, dis(p1, p2), r2);
ld area1 = r1 * r1 * (theta1 - sin(theta1 * 2) / 2);
ld theta2 = angle(r2, dis(p1, p2), r1);
ld area2 = r2 * r2 * (theta2 - sin(theta2 * 2) / 2);
return area1 + area2;
}三点确定一圆
tuple<int, Pd, ld> getCircle(Pd A, Pd B, Pd C) {
if (onLine(A, B, C)) { // 特判三点共线
return {0, {}, 0};
}
Ld l1 = midSegment(Line{A, B});
Ld l2 = midSegment(Line{A, C});
Pd O = lineIntersection(l1, l2);
return {1, O, dis(A, O)};
}求解点到圆的切线数量与切点
pair<int, vector<Point<ld>>> tangent(Point<ld> p, Point<ld> A, ld r) {
vector<Point<ld>> ans; // 储存切点
Pd u = p - A;
ld d = sqrt(dot(u, u));
if (d < r) {
return {0, {}};
} else if (sign(d - r) == 0) { // 点在圆上
ans.push_back(u);
return {1, ans};
} else {
u /= d; // 先转为单位向量
ld ang = acos(r / d);
ans.push_back(rotateVector(u, ang) * r + A); // 记得先乘再加
ans.push_back(rotateVector(u, -ang) * r + A);
return {2, ans};
}
}求解两圆的内公、外公切线数量与切点
同时返回公切线数量以及每个圆的切点。
tuple<int, vector<Point<ld>>, vector<Point<ld>>> circlePosition(Point<ld> A, ld Ar, Point<ld> B, ld Br) {
vector<Point<ld>> a, b; // 储存切点
if (Ar < Br) {
swap(Ar, Br);
swap(A, B);
swap(a, b);
}
ld d = (A.x - B.x) * (A.x - B.x) + (A.y - B.y) * (A.y - B.y);
ld dif = Ar - Br, sum = Ar + Br;
if (d < dif * dif) { // 内含,无
return {0, {}, {}};
}
ld base = atan2(B.y - A.y, B.x - A.x);
if (d == 0 && Ar == Br) { // 完全重合,无数条外公切线
return {-1, {}, {}};
}
if (d == dif * dif) { // 内切,1条外公切线
a.push_back(getPoint(A, Ar, base));
b.push_back(getPoint(B, Br, base));
return {1, a, b};
}
ld ang = acos(dif / sqrt(d));
a.push_back(getPoint(A, Ar, base + ang)); // 保底2条外公切线
a.push_back(getPoint(A, Ar, base - ang));
b.push_back(getPoint(B, Br, base + ang));
b.push_back(getPoint(B, Br, base - ang));
if (d == sum * sum) { // 外切,多1条内公切线
a.push_back(getPoint(A, Ar, base));
b.push_back(getPoint(B, Br, base + PI));
} else if (d > sum * sum) { // 相离,多2条内公切线
ang = acos(sum / sqrt(d));
a.push_back(getPoint(A, Ar, base + ang));
a.push_back(getPoint(A, Ar, base - ang));
b.push_back(getPoint(B, Br, base + ang + PI));
b.push_back(getPoint(B, Br, base - ang + PI));
}
return {a.size(), a, b};
}平面三角形相关(浮点数处理)
三角形面积
ld area(Point<ld> a, Point<ld> b, Point<ld> c) {
return abs(cross(b, c, a)) / 2;
}三角形外心
三角形外接圆的圆心,即三角形三边垂直平分线的交点。
template<class T> Pt center1(Pt p1, Pt p2, Pt p3) { // 外心
return lineIntersection(midSegment({p1, p2}), midSegment({p2, p3}));
}三角形内心
三角形内切圆的圆心,也是三角形三个内角的角平分线的交点。其到三角形三边的距离相等。
Pd center2(Pd p1, Pd p2, Pd p3) { // 内心
#define atan2(p) atan2(p.y, p.x) // 注意先后顺序
Line<ld> U = {p1, {}}, V = {p2, {}};
ld m, n, alpha;
m = atan2((p2 - p1));
n = atan2((p3 - p1));
alpha = (m + n) / 2;
U.b = {p1.x + cos(alpha), p1.y + sin(alpha)};
m = atan2((p1 - p2));
n = atan2((p3 - p2));
alpha = (m + n) / 2;
V.b = {p2.x + cos(alpha), p2.y + sin(alpha)};
return lineIntersection(U, V);
}三角形垂心
三角形的三条高线所在直线的交点。锐角三角形的垂心在三角形内;直角三角形的垂心在直角顶点上;钝角三角形的垂心在三角形外。
Pd center3(Pd p1, Pd p2, Pd p3) { // 垂心
Ld U = {p1, p1 + rotate(p2, p3)}; // 垂线
Ld V = {p2, p2 + rotate(p1, p3)};
return lineIntersection(U, V);
}平面直线方程转换
浮点数计算直线的斜率
一般很少使用到这个函数,因为斜率的取值不可控(例如接近平行于 轴时)。需要注意,当直线平行于 轴时斜率为 inf 。
template <class T> ld slope(Pt p1, Pt p2) { // 斜率,注意 inf 的情况
return (p1.y - p2.y) / (p1.x - p2.x);
}
template <class T> ld slope(Lt l) {
return slope(l.a, l.b);
}分数精确计算直线的斜率
调用分数四则运算精确计算斜率,返回最简分数,只适用于整数计算。
template<class T> Frac<T> slopeEx(Pt p1, Pt p2) {
Frac<T> U = p1.y - p2.y;
Frac<T> V = p1.x - p2.x;
return U / V; // 调用分数精确计算
}两点式转一般式
返回由三个整数构成的方程,在输入较大时可能找不到较小的满足题意的一组整数解。可以处理平行于 轴、两点共点的情况。
template<class T> tuple<T, T, T> getfun(Lt p) {
T A = p.a.y - p.b.y, B = p.b.x - p.a.x, C = p.a.x * A + p.a.y * B;
if (A < 0) { // 符号调整
A = -A, B = -B, C = -C;
} else if (A == 0) {
if (B < 0) {
B = -B, C = -C;
} else if (B == 0 && C < 0) {
C = -C;
}
}
if (A == 0) { // 数值计算
if (B == 0) {
C = 0; // 共点特判
} else {
T g = fgcd(abs(B), abs(C));
B /= g, C /= g;
}
} else if (B == 0) {
T g = fgcd(abs(A), abs(C));
A /= g, C /= g;
} else {
T g = fgcd(fgcd(abs(A), abs(B)), abs(C));
A /= g, B /= g, C /= g;
}
return tuple{A, B, C}; // Ax + By = C
}一般式转两点式
由于整数点可能很大或者不存在,故直接采用浮点数;如果与 轴有交点则取交点。可以处理平行于 轴的情况。
Line<ld> getfun(int A, int B, int C) { // Ax + By = C
ld x1 = 0, y1 = 0, x2 = 0, y2 = 0;
if (A && B) { // 正常
if (C) {
x1 = 0, y1 = 1. * C / B;
y2 = 0, x2 = 1. * C / A;
} else { // 过原点
x1 = 1, y1 = 1. * -A / B;
x2 = 0, y2 = 0;
}
} else if (A && !B) { // 垂直
if (C) {
y1 = 0, x1 = 1. * C / A;
y2 = 1, x2 = x1;
} else {
x1 = 0, y1 = 1;
x2 = 0, y2 = 0;
}
} else if (!A && B) { // 水平
if (C) {
x1 = 0, y1 = 1. * C / B;
x2 = 1, y2 = y1;
} else {
x1 = 1, y1 = 0;
x2 = 0, y2 = 0;
}
} else { // 不合法,请特判
assert(false);
}
return {{x1, y1}, {x2, y2}};
}抛物线与 x 轴是否相交及交点
代表没有交点; 代表相切; 代表有两个交点。
tuple<int, ld, ld> getAns(ld a, ld b, ld c) {
ld delta = b * b - a * c * 4;
if (delta < 0.) {
return {0, 0, 0};
}
delta = sqrt(delta);
ld ans1 = -(delta + b) / 2 / a;
ld ans2 = (delta - b) / 2 / a;
if (ans1 > ans2) {
swap(ans1, ans2);
}
if (sign(delta) == 0) {
return {1, ans2, 0};
}
return {2, ans1, ans2};
}平面多边形
两向量构成的平面四边形有向面积
template<class T> T areaEx(Point<T> p1, Point<T> p2, Point<T> p3) {
return cross(b, c, a);
}判断四个点能否组成矩形/正方形
可以处理浮点数、共点的情况。返回分为三种情况: 代表构成正方形; 代表构成矩形; 代表其他情况。
template<class T> int isSquare(vector<Pt> x) {
sort(x.begin(), x.end());
if (equal(dis(x[0], x[1]), dis(x[2], x[3])) && sign(dis(x[0], x[1])) &&
equal(dis(x[0], x[2]), dis(x[1], x[3])) && sign(dis(x[0], x[2])) &&
lineParallel(Lt{x[0], x[1]}, Lt{x[2], x[3]}) &&
lineParallel(Lt{x[0], x[2]}, Lt{x[1], x[3]}) &&
lineVertical(Lt{x[0], x[1]}, Lt{x[0], x[2]})) {
return equal(dis(x[0], x[1]), dis(x[0], x[2])) ? 2 : 1;
}
return 0;
}点是否在任意多边形内
射线法判定, 为穿越次数,当其为奇数时即代表点在多边形内部;返回 代表点在多边形边界上。
template<class T> int pointInPolygon(Point<T> a, vector<Point<T>> p) {
int n = p.size();
for (int i = 0; i < n; i++) {
if (pointOnSegment(a, Line{p[i], p[(i + 1) % n]})) {
return 2;
}
}
int t = 0;
for (int i = 0; i < n; i++) {
auto u = p[i], v = p[(i + 1) % n];
if (u.x < a.x && v.x >= a.x && pointOnLineLeft(a, Line{v, u})) {
t ^= 1;
}
if (u.x >= a.x && v.x < a.x && pointOnLineLeft(a, Line{u, v})) {
t ^= 1;
}
}
return t == 1;
}线段是否在任意多边形内部
template<class T>
bool segmentInPolygon(Line<T> l, vector<Point<T>> p) {
// 线段与多边形边界不相交且两端点都在多边形内部
#define L(x, y) pointOnLineLeft(x, y)
int n = p.size();
if (!pointInPolygon(l.a, p)) return false;
if (!pointInPolygon(l.b, p)) return false;
for (int i = 0; i < n; i++) {
auto u = p[i];
auto v = p[(i + 1) % n];
auto w = p[(i + 2) % n];
auto [t, p1, p2] = segmentIntersection(l, Line(u, v));
if (t == 1) return false;
if (t == 0) continue;
if (t == 2) {
if (pointOnSegment(v, l) && v != l.a && v != l.b) {
if (cross(v - u, w - v) > 0) {
return false;
}
}
} else {
if (p1 != u && p1 != v) {
if (L(l.a, Line(v, u)) || L(l.b, Line(v, u))) {
return false;
}
} else if (p1 == v) {
if (l.a == v) {
if (L(u, l)) {
if (L(w, l) && L(w, Line(u, v))) {
return false;
}
} else {
if (L(w, l) || L(w, Line(u, v))) {
return false;
}
}
} else if (l.b == v) {
if (L(u, Line(l.b, l.a))) {
if (L(w, Line(l.b, l.a)) && L(w, Line(u, v))) {
return false;
}
} else {
if (L(w, Line(l.b, l.a)) || L(w, Line(u, v))) {
return false;
}
}
} else {
if (L(u, l)) {
if (L(w, Line(l.b, l.a)) || L(w, Line(u, v))) {
return false;
}
} else {
if (L(w, l) || L(w, Line(u, v))) {
return false;
}
}
}
}
}
}
return true;
}任意多边形的面积
template<class T> ld area(vector<Point<T>> P) {
int n = P.size();
ld ans = 0;
for (int i = 0; i < n; i++) {
ans += cross(P[i], P[(i + 1) % n]);
}
return ans / 2.0;
}皮克定理
绘制在方格纸上的多边形面积公式可以表示为 ,其中 表示多边形内部的点数、 表示多边形边界上的点数。一条线段上的点数为 。
任意多边形上/内的网格点个数(仅能处理整数)
皮克定理用。
int onPolygonGrid(vector<Point<int>> p) { // 多边形上
int n = p.size(), ans = 0;
for (int i = 0; i < n; i++) {
auto a = p[i], b = p[(i + 1) % n];
ans += gcd(abs(a.x - b.x), abs(a.y - b.y));
}
return ans;
}
int inPolygonGrid(vector<Point<int>> p) { // 多边形内
int n = p.size(), ans = 0;
for (int i = 0; i < n; i++) {
auto a = p[i], b = p[(i + 1) % n], c = p[(i + 2) % n];
ans += b.y * (a.x - c.x);
}
ans = abs(ans);
return (ans - onPolygonGrid(p)) / 2 + 1;
}二维凸包
获取二维静态凸包(Andrew算法)
flag 用于判定凸包边上的点、重复的顶点是否要加入到凸包中,为 时代表加入凸包(不严格);为 时不加入凸包(严格)。时间复杂度为 。
template<class T> vector<Point<T>> staticConvexHull(vector<Point<T>> A, int flag = 1) {
int n = A.size();
if (n <= 2) { // 特判
return A;
}
vector<Point<T>> ans(n * 2);
sort(A.begin(), A.end());
int now = -1;
for (int i = 0; i < n; i++) { // 维护下凸包
while (now > 0 && cross(A[i], ans[now], ans[now - 1]) <= 0) {
now--;
}
ans[++now] = A[i];
}
int pre = now;
for (int i = n - 2; i >= 0; i--) { // 维护上凸包
while (now > pre && cross(A[i], ans[now], ans[now - 1]) <= 0) {
now--;
}
ans[++now] = A[i];
}
ans.resize(now);
return ans;
}二维动态凸包
固定为 int 型,需要重新书写 Line 函数,cmp 用于判定边界情况。可以处理如下两个要求:
- 动态插入点 到当前凸包中;
- 判断点 是否在凸包上或是在内部(包括边界)。
template<class T> bool turnRight(Pt a, Pt b) {
return cross(a, b) < 0 || (cross(a, b) == 0 && dot(a, b) < 0);
}
struct Line {
static int cmp;
mutable Point<int> a, b;
friend bool operator<(Line x, Line y) {
return cmp ? x.a < y.a : turnRight(x.b, y.b);
}
friend auto &operator<<(ostream &os, Line l) {
return os << "<" << l.a << ", " << l.b << ">";
}
};
int Line::cmp = 1;
struct UpperConvexHull : set<Line> {
bool contains(const Point<int> &p) const {
auto it = lower_bound({p, 0});
if (it != end() && it->a == p) return true;
if (it != begin() && it != end() && cross(prev(it)->b, p - prev(it)->a) <= 0) {
return true;
}
return false;
}
void add(const Point<int> &p) {
if (contains(p)) return;
auto it = lower_bound({p, 0});
for (; it != end(); it = erase(it)) {
if (turnRight(it->a - p, it->b)) {
break;
}
}
for (; it != begin() && prev(it) != begin(); erase(prev(it))) {
if (turnRight(prev(prev(it))->b, p - prev(prev(it))->a)) {
break;
}
}
if (it != begin()) {
prev(it)->b = p - prev(it)->a;
}
if (it == end()) {
insert({p, {0, -1}});
} else {
insert({p, it->a - p});
}
}
};
struct ConvexHull {
UpperConvexHull up, low;
bool empty() const {
return up.empty();
}
bool contains(const Point<int> &p) const {
Line::cmp = 1;
return up.contains(p) && low.contains(-p);
}
void add(const Point<int> &p) {
Line::cmp = 1;
up.add(p);
low.add(-p);
}
bool isIntersect(int A, int B, int C) const {
Line::cmp = 0;
if (empty()) return false;
Point<int> k = {-B, A};
if (k.x < 0) k = -k;
if (k.x == 0 && k.y < 0) k.y = -k.y;
Point<int> P = up.upper_bound({{0, 0}, k})->a;
Point<int> Q = -low.upper_bound({{0, 0}, k})->a;
return sign(A * P.x + B * P.y - C) * sign(A * Q.x + B * Q.y - C) > 0;
}
friend ostream &operator<<(ostream &out, const ConvexHull &ch) {
for (const auto &line : ch.up) out << "(" << line.a.x << "," << line.a.y << ")";
cout << "/";
for (const auto &line : ch.low) out << "(" << -line.a.x << "," << -line.a.y << ")";
return out;
}
};点与凸包的位置关系
代表点在凸包外面; 代表在凸壳上; 代表在凸包内部。
template<class T> int contains(Point<T> p, vector<Point<T>> A) {
int n = A.size();
bool in = false;
for (int i = 0; i < n; i++) {
Point<T> a = A[i] - p, b = A[(i + 1) % n] - p;
if (a.y > b.y) {
swap(a, b);
}
if (a.y <= 0 && 0 < b.y && cross(a, b) < 0) {
in = !in;
}
if (cross(a, b) == 0 && dot(a, b) <= 0) {
return 1;
}
}
return in ? 2 : 0;
}闵可夫斯基和
计算两个凸包合成的大凸包。
template<class T> vector<Point<T>> mincowski(vector<Point<T>> P1, vector<Point<T>> P2) {
int n = P1.size(), m = P2.size();
vector<Point<T>> V1(n), V2(m);
for (int i = 0; i < n; i++) {
V1[i] = P1[(i + 1) % n] - P1[i];
}
for (int i = 0; i < m; i++) {
V2[i] = P2[(i + 1) % m] - P2[i];
}
vector<Point<T>> ans = {P1.front() + P2.front()};
int t = 0, i = 0, j = 0;
while (i < n && j < m) {
Point<T> val = sign(cross(V1[i], V2[j])) > 0 ? V1[i++] : V2[j++];
ans.push_back(ans.back() + val);
}
while (i < n) ans.push_back(ans.back() + V1[i++]);
while (j < m) ans.push_back(ans.back() + V2[j++]);
return ans;
}半平面交
计算多条直线左边平面部分的交集。
template<class T> vector<Point<T>> halfcut(vector<Line<T>> lines) {
sort(lines.begin(), lines.end(), [&](auto l1, auto l2) {
auto d1 = l1.b - l1.a;
auto d2 = l2.b - l2.a;
if (sign(d1) != sign(d2)) {
return sign(d1) == 1;
}
return cross(d1, d2) > 0;
});
deque<Line<T>> ls;
deque<Point<T>> ps;
for (auto l : lines) {
if (ls.empty()) {
ls.push_back(l);
continue;
}
while (!ps.empty() && !pointOnLineLeft(ps.back(), l)) {
ps.pop_back();
ls.pop_back();
}
while (!ps.empty() && !pointOnLineLeft(ps[0], l)) {
ps.pop_front();
ls.pop_front();
}
if (cross(l.b - l.a, ls.back().b - ls.back().a) == 0) {
if (dot(l.b - l.a, ls.back().b - ls.back().a) > 0) {
if (!pointOnLineLeft(ls.back().a, l)) {
assert(ls.size() == 1);
ls[0] = l;
}
continue;
}
return {};
}
ps.push_back(lineIntersection(ls.back(), l));
ls.push_back(l);
}
while (!ps.empty() && !pointOnLineLeft(ps.back(), ls[0])) {
ps.pop_back();
ls.pop_back();
}
if (ls.size() <= 2) {
return {};
}
ps.push_back(lineIntersection(ls[0], ls.back()));
return vector(ps.begin(), ps.end());
}旋转卡壳
求凸包直径
void solve() {
int n;
cin >> n;
vector<Pt> t(n);
for (int i = 0; i < n; ++i)cin >> t[i].x >> t[i].y;
if (n == 2) {
cout << disT(t[0], t[1]);
return;
}
vector<Pt> tb = staticConvexHull(t);
int len = tb.size(), cur = 1;
int res = 0;
for (int i = 0; i < len - 1; ++i) {
Lt tmp = {tb[i], tb[i + 1]};
while (pointToLine(tb[cur], tmp).second < pointToLine(tb[(cur + 1) % len], tmp).second) cur = (cur + 1) % len;
res = max({res, disT(tb[i], tb[cur]), disT(tb[i + 1], tb[cur])});
}
cout << res;
}最小覆盖圆
double sqr(double x) { return x * x; }
double dis(point a, point b) { return sqrt(sqr(a.x - b.x) + sqr(a.y - b.y)); }
bool cmp(double a, double b) { return fabs(a - b) < 1e-8; }
point geto(point a, point b, point c) {
double a1, a2, b1, b2, c1, c2;
point ans;
a1 = 2 * (b.x - a.x), b1 = 2 * (b.y - a.y),
c1 = sqr(b.x) - sqr(a.x) + sqr(b.y) - sqr(a.y);
a2 = 2 * (c.x - a.x), b2 = 2 * (c.y - a.y),
c2 = sqr(c.x) - sqr(a.x) + sqr(c.y) - sqr(a.y);
if (cmp(a1, 0)) {
ans.y = c1 / b1;
ans.x = (c2 - ans.y * b2) / a2;
} else if (cmp(b1, 0)) {
ans.x = c1 / a1;
ans.y = (c2 - ans.x * a2) / b2;
} else {
ans.x = (c2 * b1 - c1 * b2) / (a2 * b1 - a1 * b2);
ans.y = (c2 * a1 - c1 * a2) / (b2 * a1 - b1 * a2);
}
return ans;
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) scanf("%lf%lf", &p[i].x, &p[i].y);
for (int i = 1; i <= n; i++) swap(p[rand() % n + 1], p[rand() % n + 1]);
o = p[1];
for (int i = 1; i <= n; i++) {
if (dis(o, p[i]) < r || cmp(dis(o, p[i]), r)) continue;
o.x = (p[i].x + p[1].x) / 2;
o.y = (p[i].y + p[1].y) / 2;
r = dis(p[i], p[1]) / 2;
for (int j = 2; j < i; j++) {
if (dis(o, p[j]) < r || cmp(dis(o, p[j]), r)) continue;
o.x = (p[i].x + p[j].x) / 2;
o.y = (p[i].y + p[j].y) / 2;
r = dis(p[i], p[j]) / 2;
for (int k = 1; k < j; k++) {
if (dis(o, p[k]) < r || cmp(dis(o, p[k]), r)) continue;
o = geto(p[i], p[j], p[k]);
r = dis(o, p[i]);
}
}
}
printf("%.10lf\n%.10lf %.10lf", r, o.x, o.y);
return 0;
}三维几何必要初始化
点线面封装
struct Point3 {
ld x, y, z;
Point3(ld x_ = 0, ld y_ = 0, ld z_ = 0) : x(x_), y(y_), z(z_) {}
Point3 &operator+=(Point3 p) & {
return x += p.x, y += p.y, z += p.z, *this;
}
Point3 &operator-=(Point3 p) & {
return x -= p.x, y -= p.y, z -= p.z, *this;
}
Point3 &operator*=(Point3 p) & {
return x *= p.x, y *= p.y, z *= p.z, *this;
}
Point3 &operator*=(ld t) & {
return x *= t, y *= t, z *= t, *this;
}
Point3 &operator/=(ld t) & {
return x /= t, y /= t, z /= t, *this;
}
friend Point3 operator+(Point3 a, Point3 b) { return a += b; }
friend Point3 operator-(Point3 a, Point3 b) { return a -= b; }
friend Point3 operator*(Point3 a, Point3 b) { return a *= b; }
friend Point3 operator*(Point3 a, ld b) { return a *= b; }
friend Point3 operator*(ld a, Point3 b) { return b *= a; }
friend Point3 operator/(Point3 a, ld b) { return a /= b; }
friend auto &operator>>(istream &is, Point3 &p) {
return is >> p.x >> p.y >> p.z;
}
friend auto &operator<<(ostream &os, Point3 p) {
return os << "(" << p.x << ", " << p.y << ", " << p.z << ")";
}
};
struct Line3 {
Point3 a, b;
};
struct Plane {
Point3 u, v, w;
};其他函数
ld len(P3 p) { // 原点到当前点的距离计算
return sqrt(p.x * p.x + p.y * p.y + p.z * p.z);
}
P3 crossEx(P3 a, P3 b) { // 叉乘
P3 ans;
ans.x = a.y * b.z - a.z * b.y;
ans.y = a.z * b.x - a.x * b.z;
ans.z = a.x * b.y - a.y * b.x;
return ans;
}
ld cross(P3 a, P3 b) {
return len(crossEx(a, b));
}
ld dot(P3 a, P3 b) { // 点乘
return a.x * b.x + a.y * b.y + a.z * b.z;
}
P3 getVec(Plane s) { // 获取平面法向量
return crossEx(s.u - s.v, s.v - s.w);
}
ld dis(P3 a, P3 b) { // 三维欧几里得距离公式
ld val = (a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y) + (a.z - b.z) * (a.z - b.z);
return sqrt(val);
}
P3 standardize(P3 vec) { // 将三维向量转换为单位向量
return vec / len(vec);
}三维点线面相关
空间三点是否共线
其中第二个函数是专门用来判断给定的三个点能否构成平面的,因为不共线的三点才能构成平面。
bool onLine(P3 p1, P3 p2, P3 p3) { // 三点是否共线
return sign(cross(p1 - p2, p3 - p2)) == 0;
}
bool onLine(Plane s) {
return onLine(s.u, s.v, s.w);
}四点是否共面
bool onPlane(P3 p1, P3 p2, P3 p3, P3 p4) { // 四点是否共面
ld val = dot(getVec({p1, p2, p3}), p4 - p1);
return sign(val) == 0;
}空间点是否在线段上
bool pointOnSegment(P3 p, L3 l) {
return sign(cross(p - l.a, p - l.b)) == 0 && min(l.a.x, l.b.x) <= p.x &&
p.x <= max(l.a.x, l.b.x) && min(l.a.y, l.b.y) <= p.y && p.y <= max(l.a.y, l.b.y) &&
min(l.a.z, l.b.z) <= p.z && p.z <= max(l.a.z, l.b.z);
}
bool pointOnSegmentEx(P3 p, L3 l) { // pointOnSegment去除端点版
return sign(cross(p - l.a, p - l.b)) == 0 && min(l.a.x, l.b.x) < p.x &&
p.x < max(l.a.x, l.b.x) && min(l.a.y, l.b.y) < p.y && p.y < max(l.a.y, l.b.y) &&
min(l.a.z, l.b.z) < p.z && p.z < max(l.a.z, l.b.z);
}空间两点是否在线段同侧
当给定的两点与线段不共面、点在线段上时返回 。
bool pointOnSegmentSide(P3 p1, P3 p2, L3 l) {
if (!onPlane(p1, p2, l.a, l.b)) { // 特判不共面
return 0;
}
ld val = dot(crossEx(l.a - l.b, p1 - l.b), crossEx(l.a - l.b, p2 - l.b));
return sign(val) == 1;
}两点是否在平面同侧
点在平面上时返回 。
bool pointOnPlaneSide(P3 p1, P3 p2, Plane s) {
ld val = dot(getVec(s), p1 - s.u) * dot(getVec(s), p2 - s.u);
return sign(val) == 1;
}空间两直线是否平行/垂直
bool lineParallel(L3 l1, L3 l2) {
return sign(cross(l1.a - l1.b, l2.a - l2.b)) == 0;
}
bool lineVertical(L3 l1, L3 l2) {
return sign(dot(l1.a - l1.b, l2.a - l2.b)) == 0;
}两平面是否平行/垂直
bool planeParallel(Plane s1, Plane s2) {
ld val = cross(getVec(s1), getVec(s2));
return sign(val) == 0;
}
bool planeVertical(Plane s1, Plane s2) {
ld val = dot(getVec(s1), getVec(s2));
return sign(val) == 0;
}空间两直线是否是同一条
bool same(L3 l1, L3 l2) {
return lineParallel(l1, l2) && lineParallel({l1.a, l2.b}, {l1.b, l2.a});
}两平面是否是同一个
bool same(Plane s1, Plane s2) {
return onPlane(s1.u, s2.u, s2.v, s2.w) && onPlane(s1.v, s2.u, s2.v, s2.w) &&
onPlane(s1.w, s2.u, s2.v, s2.w);
}直线是否与平面平行
bool linePlaneParallel(L3 l, Plane s) {
ld val = dot(l.a - l.b, getVec(s));
return sign(val) == 0;
}空间两线段是否相交
bool segmentIntersection(L3 l1, L3 l2) { // 重叠、相交于端点均视为相交
if (!onPlane(l1.a, l1.b, l2.a, l2.b)) { // 特判不共面
return 0;
}
if (!onLine(l1.a, l1.b, l2.a) || !onLine(l1.a, l1.b, l2.b)) {
return !pointOnSegmentSide(l1.a, l1.b, l2) && !pointOnSegmentSide(l2.a, l2.b, l1);
}
return pointOnSegment(l1.a, l2) || pointOnSegment(l1.b, l2) || pointOnSegment(l2.a, l1) ||
pointOnSegment(l2.b, l2);
}
bool segmentIntersection1(L3 l1, L3 l2) { // 重叠、相交于端点不视为相交
return onPlane(l1.a, l1.b, l2.a, l2.b) && !pointOnSegmentSide(l1.a, l1.b, l2) &&
!pointOnSegmentSide(l2.a, l2.b, l1);
}空间两直线是否相交及交点
当两直线不共面、两直线平行时返回 。
pair<bool, P3> lineIntersection(L3 l1, L3 l2) {
if (!onPlane(l1.a, l1.b, l2.a, l2.b) || lineParallel(l1, l2)) {
return {0, {}};
}
auto [s1, e1] = l1;
auto [s2, e2] = l2;
ld val = 0;
if (!onPlane(l1.a, l1.b, {0, 0, 0}, {0, 0, 1})) {
val = ((s1.x - s2.x) * (s2.y - e2.y) - (s1.y - s2.y) * (s2.x - e2.x)) /
((s1.x - e1.x) * (s2.y - e2.y) - (s1.y - e1.y) * (s2.x - e2.x));
} else if (!onPlane(l1.a, l1.b, {0, 0, 0}, {0, 1, 0})) {
val = ((s1.x - s2.x) * (s2.z - e2.z) - (s1.z - s2.z) * (s2.x - e2.x)) /
((s1.x - e1.x) * (s2.z - e2.z) - (s1.z - e1.z) * (s2.x - e2.x));
} else {
val = ((s1.y - s2.y) * (s2.z - e2.z) - (s1.z - s2.z) * (s2.y - e2.y)) /
((s1.y - e1.y) * (s2.z - e2.z) - (s1.z - e1.z) * (s2.y - e2.y));
}
return {1, s1 + (e1 - s1) * val};
}直线与平面是否相交及交点
当直线与平面平行、给定的点构不成平面时返回 。
pair<bool, P3> linePlaneCross(L3 l, Plane s) {
if (linePlaneParallel(l, s)) {
return {0, {}};
}
P3 vec = getVec(s);
P3 U = vec * (s.u - l.a), V = vec * (l.b - l.a);
ld val = (U.x + U.y + U.z) / (V.x + V.y + V.z);
return {1, l.a + (l.b - l.a) * val};
}两平面是否相交及交线
当两平面平行、两平面为同一个时返回 。
pair<bool, L3> planeIntersection(Plane s1, Plane s2) {
if (planeParallel(s1, s2) || same(s1, s2)) {
return {0, {}};
}
P3 U = linePlaneParallel({s2.u, s2.v}, s1) ? linePlaneCross({s2.v, s2.w}, s1).second
: linePlaneCross({s2.u, s2.v}, s1).second;
P3 V = linePlaneParallel({s2.w, s2.u}, s1) ? linePlaneCross({s2.v, s2.w}, s1).second
: linePlaneCross({s2.w, s2.u}, s1).second;
return {1, {U, V}};
}点到直线的最近点与最近距离
pair<ld, P3> pointToLine(P3 p, L3 l) {
ld val = cross(p - l.a, l.a - l.b) / dis(l.a, l.b); // 面积除以底边长
ld val1 = dot(p - l.a, l.a - l.b) / dis(l.a, l.b);
return {val, l.a + val1 * standardize(l.a - l.b)};
}点到平面的最近点与最近距离
pair<ld, P3> pointToPlane(P3 p, Plane s) {
P3 vec = getVec(s);
ld val = dot(vec, p - s.u);
val = abs(val) / len(vec); // 面积除以底边长
return {val, p - val * standardize(vec)};
}空间两直线的最近距离与最近点对
tuple<ld, P3, P3> lineToLine(L3 l1, L3 l2) {
P3 vec = crossEx(l1.a - l1.b, l2.a - l2.b); // 计算同时垂直于两直线的向量
ld val = abs(dot(l1.a - l2.a, vec)) / len(vec);
P3 U = l1.b - l1.a, V = l2.b - l2.a;
vec = crossEx(U, V);
ld p = dot(vec, vec);
ld t1 = dot(crossEx(l2.a - l1.a, V), vec) / p;
ld t2 = dot(crossEx(l2.a - l1.a, U), vec) / p;
return {val, l1.a + (l1.b - l1.a) * t1, l2.a + (l2.b - l2.a) * t2};
}三维角度与弧度
空间两直线夹角的 cos 值
任意位置的空间两直线。
ld lineCos(L3 l1, L3 l2) {
return dot(l1.a - l1.b, l2.a - l2.b) / len(l1.a - l1.b) / len(l2.a - l2.b);
}空间两平面夹角的 cos 值
ld planeCos(Plane s1, Plane s2) {
P3 U = getVec(s1), V = getVec(s2);
return dot(U, V) / len(U) / len(V);
}直线与平面夹角的 sin 值
ld linePlaneSin(L3 l, Plane s) {
P3 vec = getVec(s);
return dot(l.a - l.b, vec) / len(l.a - l.b) / len(vec);
}空间多边形
正N棱锥体积公式
棱锥通用体积公式 ,当其恰好是棱长为 的正 棱锥时,有公式 。
ld V(ld l, int n) { // 正n棱锥体积公式
return l * l * l * n / (12 * tan(PI / n)) * sqrt(1 - 1 / (4 * sin(PI / n) * sin(PI / n)));
}四面体体积
ld V(P3 a, P3 b, P3 c, P3 d) {
return abs(dot(d - a, crossEx(b - a, c - a))) / 6;
}点是否在空间三角形上
点位于边界上时返回 。
bool pointOnTriangle(P3 p, P3 p1, P3 p2, P3 p3) {
return pointOnSegmentSide(p, p1, {p2, p3}) && pointOnSegmentSide(p, p2, {p1, p3}) &&
pointOnSegmentSide(p, p3, {p1, p2});
}线段是否与空间三角形相交及交点
只有交点在空间三角形内部时才视作相交。
pair<bool, P3> segmentOnTriangle(P3 l, P3 r, P3 p1, P3 p2, P3 p3) {
P3 x = crossEx(p2 - p1, p3 - p1);
if (sign(dot(x, r - l)) == 0) {
return {0, {}};
}
ld t = dot(x, p1 - l) / dot(x, r - l);
if (t < 0 || t - 1 > 0) { // 不在线段上
return {0, {}};
}
bool type = pointOnTriangle(l + (r - l) * t, p1, p2, p3);
if (type) {
return {1, l + (r - l) * t};
} else {
return {0, {}};
}
}空间三角形是否相交
相交线段在空间三角形内部时才视作相交。
bool triangleIntersection(vector<P3> a, vector<P3> b) {
for (int i = 0; i < 3; i++) {
if (segmentOnTriangle(b[i], b[(i + 1) % 3], a[0], a[1], a[2]).first) {
return 1;
}
if (segmentOnTriangle(a[i], a[(i + 1) % 3], b[0], b[1], b[2]).first) {
return 1;
}
}
return 0;
}常用结论
平面几何结论归档
hypot函数可以直接计算直角三角形的斜边长;边心距是指正多边形的外接圆圆心到正多边形某一边的距离,边长为 的正 角形的边心距公式为 ,外接圆半径为 的正 角形的边心距公式为 ;
三角形外接圆半径为 ,其中 为三角形面积,内切圆半径为 ;
由小正三角形拼成的大正三角形,耗费的小三角形数量即为构成一条边的小三角形数量的平方。如下图,总数量即为 See。
正 边形圆心角为 ,圆周角为 。定义正 边形上的三个顶点 和 (可以不相邻),使得 ,当 时, 可以取 到 间的任何一个整数 See。
某一点 到直线 的距离公式为 ,等价于 。
atan(y / x)函数仅用于计算第一、四象限的值,而atan2(y, x)则允许计算所有四个象限的正反切,在使用这个函数时,需要尽量保证 和 的类型为整数型,如果使用浮点数,实测会慢十倍。在平面上有奇数个点 以及一个点 ,构造 使得 关于 对称、构造 使得 关于 对称、……、构造 使得 关于 对称。那么周期为 ,即 与 共点、 与 共点 See 。
已知 和 两点及这两点的坐标,构造 使得 关于 对称,那么 的坐标为 。
海伦公式:已知三角形三边长 和 ,定义 ,则 ,在使用时需要注意越界问题,本质是铅锤定理,一般多使用叉乘计算三角形面积而不使用该公式。
棱台体积 ,其中 为上下底面积。
正棱台侧面积 ,其中 为上下底周长, 为斜高(上下底对应的平行边的距离)。
球面积 ,体积 。
正三角形面积 ,正四面体面积 。
设扇形对应的圆心角弧度为 ,则面积为 。
立体几何结论归档
- 已知向量 ,则该向量的三个方向余弦为 。其中 , 。
常用例题
将平面某点旋转任意角度
题意:给定平面上一点 ,输出将其逆时针旋转 度之后的坐标。
signed main() {
int a, b, d;
cin >> a >> b >> d;
ld l = hypot(a, b); // 库函数,求直角三角形的斜边
ld alpha = atan2(b, a) + toArc(d);
cout << l * cos(alpha) << " " << l * sin(alpha) << endl;
}平面最近点对(set解)
借助 set ,在严格 复杂度内求解,比常见的分治法稍快。
template<class T> T sqr(T x) {
return x * x;
}
using V = Point<int>;
signed main() {
int n;
cin >> n;
vector<V> in(n);
for (auto &it : in) {
cin >> it;
}
int dis = disEx(in[0], in[1]); // 设定阈值
sort(in.begin(), in.end());
set<V> S;
for (int i = 0, h = 0; i < n; i++) {
V now = {in[i].y, in[i].x};
while (dis && dis <= sqr(in[i].x - in[h].x)) { // 删除超过阈值的点
S.erase({in[h].y, in[h].x});
h++;
}
auto it = S.lower_bound(now);
for (auto k = it; k != S.end() && sqr(k->x - now.x) < dis; k++) {
dis = min(dis, disEx(*k, now));
}
if (it != S.begin()) {
for (auto k = prev(it); sqr(k->x - now.x) < dis; k--) {
dis = min(dis, disEx(*k, now));
if (k == S.begin()) break;
}
}
S.insert(now);
}
cout << sqrt(dis) << endl;
}平面若干点能构成的最大四边形的面积(简单版,暴力枚举)
题意:平面上存在若干个点,保证没有两点重合、没有三点共线,你需要从中选出四个点,使得它们构成的四边形面积是最大的,注意这里能组成的四边形可以不是凸四边形。
暴力枚举其中一条对角线后枚举剩余两个点, 。
signed main() {
int n;
cin >> n;
vector<Pi> in(n);
for (auto &it : in) {
cin >> it;
}
ld ans = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) { // 枚举对角线
ld l = 0, r = 0;
for (int k = 0; k < n; k++) { // 枚举第三点
if (k == i || k == j) continue;
if (pointOnLineLeft(in[k], {in[i], in[j]})) {
l = max(l, triangleS(in[k], in[j], in[i]));
} else {
r = max(r, triangleS(in[k], in[j], in[i]));
}
}
if (l * r != 0) { // 确保构成的是四边形
ans = max(ans, l + r);
}
}
}
cout << ans << endl;
}平面若干点能构成的最大四边形的面积(困难版,分类讨论+旋转卡壳)
题意:平面上存在若干个点,可能存在多点重合、共线的情况,你需要从中选出四个点,使得它们构成的四边形面积是最大的,注意这里能组成的四边形可以不是凸四边形、可以是退化的四边形。
当凸包大小 时,说明是退化的四边形,答案直接为 ;大小恰好为 时,说明是凹四边形,我们枚举不在凸包上的那一点,将两个三角形面积相减既可得到答案;大小恰好为 时,说明是凸四边形,使用旋转卡壳求解。
using V = Point<int>;
signed main() {
int Task = 1;
for (cin >> Task; Task; Task--) {
int n;
cin >> n;
vector<V> in_(n);
for (auto &it : in_) {
cin >> it;
}
auto in = staticConvexHull(in_, 0);
n = in.size();
int ans = 0;
if (n > 3) {
ans = rotatingCalipers(in);
} else if (n == 3) {
int area = triangleAreaEx(in[0], in[1], in[2]);
for (auto it : in_) {
if (it == in[0] || it == in[1] || it == in[2]) continue;
int Min = min({triangleAreaEx(it, in[0], in[1]), triangleAreaEx(it, in[0], in[2]), triangleAreaEx(it, in[1], in[2])});
ans = max(ans, area - Min);
}
}
cout << ans / 2;
if (ans % 2) {
cout << ".5";
}
cout << endl;
}
}线段将多边形切割为几个部分
题意:给定平面上一线段与一个任意多边形,求解线段将多边形切割为几个部分;保证线段的端点不在多边形内、多边形边上,多边形顶点不位于线段上,多边形的边不与线段重叠;多边形端点按逆时针顺序给出。下方的几个样例均合法,答案均为 。
当线段切割多边形时,本质是与多边形的边交于两个点、或者说是与多边形的两条边相交,设交点数目为 ,那么答案即为 。于是,我们只需要计算交点数量即可,先判断某一条边是否与线段相交,再判断边的两个端点是否位于线段两侧。
signed main() {
Pi s, e;
cin >> s >> e; // 读入线段
int n;
cin >> n;
vector<Pi> in(n);
for (auto &it : in) {
cin >> it; // 读入多边形端点
}
int cnt = 0;
for (int i = 0; i < n; i++) {
Pi x = in[i], y = in[(i + 1) % n];
cnt += (pointNotOnLineSide(x, y, {s, e}) && segmentIntersection(Line{x, y}, {s, e}));
}
cout << cnt / 2 + 1 << endl;
}平面若干点能否构成凸包(暴力枚举)
题意:给定平面上若干个点,判断其是否构成凸包 See 。
可以直接使用凸包模板,但是代码较长;在这里我们使用暴力枚举试点,也能以 的复杂度通过。当两个向量的叉乘 时说明其夹角大于等于 ,使用这一点即可判定。
signed main() {
int n;
cin >> n;
vector<Point<ld>> in(n);
for (auto &it : in) {
cin >> it;
}
for (int i = 0; i < n; i++) {
auto A = in[(i - 1 + n) % n];
auto B = in[i];
auto C = in[(i + 1) % n];
if (cross(A - B, C - B) > 0) {
cout << "No\n";
return 0;
}
}
cout << "Yes\n";
}凸包上的点能构成的最大三角形(暴力枚举)
可以直接使用凸包模板,但是代码较长;在这里我们使用暴力枚举试点,也能以 的复杂度通过。
另外补充一点性质:所求三角形的反互补三角形一定包含了凸包上的所有点(可以在边界)。通俗的说,构成的三角形是这个反互补三角形的中点三角形。如下图所示,点 不在 的反互补三角形内部,故 不是最大三角形; 才是。
signed main() {
int n;
cin >> n;
vector<Point<int>> in(n);
for (auto &it : in) {
cin >> it;
}
#define S(x, y, z) triangleAreaEx(in[x], in[y], in[z])
int i = 0, j = 1, k = 2;
while (true) {
int val = S(i, j, k);
if (S((i + 1) % n, j, k) > val) {
i = (i + 1) % n;
} else if (S((i - 1 + n) % n, j, k) > val) {
i = (i - 1 + n) % n;
} else if (S(i, (j + 1) % n, k) > val) {
j = (j + 1) % n;
} else if (S(i, (j - 1 + n) % n, k) > val) {
j = (j - 1 + n) % n;
} else if (S(i, j, (k + 1) % n) > val) {
k = (k + 1) % n;
} else if (S(i, j, (k - 1 + n) % n) > val) {
k = (k - 1 + n) % n;
} else {
break;
}
}
cout << i + 1 << " " << j + 1 << " " << k + 1 << endl;
}凸包上的点能构成的最大四角形的面积(旋转卡壳)
由于是凸包上的点,所以保证了四边形一定是凸四边形,时间复杂度 。
template<class T> T rotatingCalipers(vector<Point<T>> &p) {
#define S(x, y, z) triangleAreaEx(p[x], p[y], p[z])
int n = p.size();
T ans = 0;
auto nxt = [&](int i) -> int {
return i == n - 1 ? 0 : i + 1;
};
for (int i = 0; i < n; i++) {
int p1 = nxt(i), p2 = nxt(nxt(nxt(i)));
for (int j = nxt(nxt(i)); nxt(j) != i; j = nxt(j)) {
while (nxt(p1) != j && S(i, j, nxt(p1)) > S(i, j, p1)) {
p1 = nxt(p1);
}
if (p2 == j) {
p2 = nxt(p2);
}
while (nxt(p2) != i && S(i, j, nxt(p2)) > S(i, j, p2)) {
p2 = nxt(p2);
}
ans = max(ans, S(i, j, p1) + S(i, j, p2));
}
}
return ans;
#undef S
}判断一个凸包是否完全在另一个凸包内
题意:给定一个凸多边形 和一个凸多边形 ,询问 是否被 包含,分别判断严格/不严格包含。例题。
考虑严格包含,使用 点集计算出凸包 ,使用 两个点集计算出不严格凸包 ,如果包含,那么 应该与 完全相等;考虑不严格包含,在计算凸包 时严格即可。最终以 复杂度求解,且代码不算很长。
多项式
多项式封装
std::vector<int> rev;
std::vector<Z> roots{0, 1};
void dft(std::vector<Z> &a) {
int n = a.size();
if (rev.size() != n) {
int k = __builtin_ctz(n) - 1;
rev.resize(n);
for (int i = 0; i < n; i++) {
rev[i] = rev[i >> 1] >> 1 | (i & 1) << k;
}
}
for (int i = 0; i < n; i++) {
if (rev[i] < i) {
std::swap(a[i], a[rev[i]]);
}
}
if (roots.size() < n) {
int k = __builtin_ctz(roots.size());
roots.resize(n);
while ((1 << k) < n) {
Z e = power(Z(3), (P - 1) >> (k + 1));
for (int i = 1 << (k - 1); i < (1 << k); i++) {
roots[2 * i] = roots[i];
roots[2 * i + 1] = roots[i] * e;
}
k++;
}
}
for (int k = 1; k < n; k *= 2) {
for (int i = 0; i < n; i += 2 * k) {
for (int j = 0; j < k; j++) {
Z u = a[i + j];
Z v = a[i + j + k] * roots[k + j];
a[i + j] = u + v;
a[i + j + k] = u - v;
}
}
}
}
void idft(std::vector<Z> &a) {
int n = a.size();
std::reverse(a.begin() + 1, a.end());
dft(a);
Z inv = (1 - P) / n;
for (int i = 0; i < n; i++) {
a[i] *= inv;
}
}
struct Poly {
std::vector<Z> a;
Poly() {}
explicit Poly(int size, std::function<Z(int)> f = [](int) { return 0; }) : a(size) {
for (int i = 0; i < size; i++) {
a[i] = f(i);
}
}
Poly(const std::vector<Z> &a) : a(a) {}
Poly(const std::initializer_list<Z> &a) : a(a) {}
int size() const {
return a.size();
}
void resize(int n) {
a.resize(n);
}
Z operator[](int idx) const {
if (idx < size()) {
return a[idx];
} else {
return 0;
}
}
Z &operator[](int idx) {
return a[idx];
}
Poly mulxk(int k) const {
auto b = a;
b.insert(b.begin(), k, 0);
return Poly(b);
}
Poly modxk(int k) const {
k = std::min(k, size());
return Poly(std::vector<Z>(a.begin(), a.begin() + k));
}
Poly divxk(int k) const {
if (size() <= k) {
return Poly();
}
return Poly(std::vector<Z>(a.begin() + k, a.end()));
}
friend Poly operator+(const Poly &a, const Poly &b) {
std::vector<Z> res(std::max(a.size(), b.size()));
for (int i = 0; i < roots.size(); i++) {
res[i] = a[i] + b[i];
}
return Poly(res);
}
friend Poly operator-(const Poly &a, const Poly &b) {
std::vector<Z> res(std::max(a.size(), b.size()));
for (int i = 0; i < roots.size(); i++) {
res[i] = a[i] - b[i];
}
return Poly(res);
}
friend Poly operator-(const Poly &a) {
std::vector<Z> res(a.size());
for (int i = 0; i < roots.size(); i++) {
res[i] = -a[i];
}
return Poly(res);
}
friend Poly operator*(Poly a, Poly b) {
if (a.size() == 0 || b.size() == 0) {
return Poly();
}
if (a.size() < b.size()) {
std::swap(a, b);
}
if (b.size() < 128) {
Poly c(a.size() + b.size() - 1);
for (int i = 0; i < a.size(); i++) {
for (int j = 0; j < b.size(); j++) {
c[i + j] += a[i] * b[j];
}
}
return c;
}
int sz = 1, tot = a.size() + b.size() - 1;
while (sz < tot) {
sz *= 2;
}
a.a.resize(sz);
b.a.resize(sz);
dft(a.a);
dft(b.a);
for (int i = 0; i < sz; ++i) {
a.a[i] = a[i] * b[i];
}
idft(a.a);
a.resize(tot);
return a;
}
friend Poly operator*(Z a, Poly b) {
for (int i = 0; i < roots.size(); i++) {
b[i] *= a;
}
return b;
}
friend Poly operator*(Poly a, Z b) {
for (int i = 0; i < roots.size(); i++) {
a[i] *= b;
}
return a;
}
Poly &operator+=(Poly b) {
return (*this) = (*this) + b;
}
Poly &operator-=(Poly b) {
return (*this) = (*this) - b;
}
Poly &operator*=(Poly b) {
return (*this) = (*this) * b;
}
Poly &operator*=(Z b) {
return (*this) = (*this) * b;
}
Poly deriv() const {
if (a.empty()) {
return Poly();
}
std::vector<Z> res(size() - 1);
for (int i = 0; i < size() - 1; ++i) {
res[i] = (i + 1) * a[i + 1];
}
return Poly(res);
}
Poly integr() const {
std::vector<Z> res(size() + 1);
for (int i = 0; i < size(); ++i) {
res[i + 1] = a[i] / (i + 1);
}
return Poly(res);
}
Poly inv(int m) const {
Poly x{a[0].inv()};
int k = 1;
while (k < m) {
k *= 2;
x = (x * (Poly{2} - modxk(k) * x)).modxk(k);
}
return x.modxk(m);
}
Poly log(int m) const {
return (deriv() * inv(m)).integr().modxk(m);
}
Poly exp(int m) const {
Poly x{1};
int k = 1;
while (k < m) {
k *= 2;
x = (x * (Poly{1} - x.log(k) + modxk(k))).modxk(k);
}
return x.modxk(m);
}
Poly pow(int k, int m) const {
int i = 0;
while (i < size() && a[i].val() == 0) {
i++;
}
if (i == size() || 1LL * i * k >= m) {
return Poly(std::vector<Z>(m));
}
Z v = a[i];
auto f = divxk(i) * v.inv();
return (f.log(m - i * k) * k).exp(m - i * k).mulxk(i * k) * power(v, k);
}
Poly sqrt(int m) const {
Poly x{1};
int k = 1;
while (k < m) {
k *= 2;
x = (x + (modxk(k) * x.inv(k)).modxk(k)) * ((P + 1) / 2);
}
return x.modxk(m);
}
Poly mulT(Poly b) const {
if (b.size() == 0) {
return Poly();
}
int n = b.size();
std::reverse(b.a.begin(), b.a.end());
return ((*this) * b).divxk(n - 1);
}
std::vector<Z> eval(std::vector<Z> x) const {
if (size() == 0) {
return std::vector<Z>(x.size(), 0);
}
const int n = std::max((int) roots.size(), size());
std::vector<Poly> q(4 * n);
std::vector<Z> ans(x.size());
x.resize(n);
std::function<void(int, int, int)> build = [&](int p, int l, int r) {
if (r - l == 1) {
q[p] = Poly{1, -x[l]};
} else {
int m = (l + r) / 2;
build(2 * p, l, m);
build(2 * p + 1, m, r);
q[p] = q[2 * p] * q[2 * p + 1];
}
};
build(1, 0, n);
std::function<void(int, int, int, const Poly &)> work = [&](int p, int l, int r, const Poly &num) {
if (r - l == 1) {
if (l < ans.size()) {
ans[l] = num[0];
}
} else {
int m = (l + r) / 2;
work(2 * p, l, m, num.mulT(q[2 * p + 1]).modxk(m - l));
work(2 * p + 1, m, r, num.mulT(q[2 * p]).modxk(r - m));
}
};
work(1, 0, n, mulT(q[1].inv(n)));
return ans;
}
};Berlekamp-Massey 算法(杜教筛)
求解数列的最短线性递推式,最坏复杂度为 ,其中 为数列长度, 为它的最短递推式的阶数。
template<int P = 998244353> Poly<P> berlekampMassey(const Poly<P> &s) {
Poly<P> c;
Poly<P> oldC;
int f = -1;
for (int i = 0; i < s.size(); i++) {
auto delta = s[i];
for (int j = 1; j <= c.size(); j++) {
delta -= c[j - 1] * s[i - j];
}
if (delta == 0) {
continue;
}
if (f == -1) {
c.resize(i + 1);
f = i;
} else {
auto d = oldC;
d *= -1;
d.insert(d.begin(), 1);
MInt<P> df1 = 0;
for (int j = 1; j <= d.size(); j++) {
df1 += d[j - 1] * s[f + 1 - j];
}
assert(df1 != 0);
auto coef = delta / df1;
d *= coef;
Poly<P> zeros(i - f - 1);
zeros.insert(zeros.end(), d.begin(), d.end());
d = zeros;
auto temp = c;
c += d;
if (i - temp.size() > f - oldC.size()) {
oldC = temp;
f = i;
}
}
}
c *= -1;
c.insert(c.begin(), 1);
return c;
}Linear-Recurrence 算法
template<int P = 998244353> MInt<P> linearRecurrence(Poly<P> p, Poly<P> q, i64 n) {
int m = q.size() - 1;
while (n > 0) {
auto newq = q;
for (int i = 1; i <= m; i += 2) {
newq[i] *= -1;
}
auto newp = p * newq;
newq = q * newq;
for (int i = 0; i < m; i++) {
p[i] = newp[i * 2 + n % 2];
}
for (int i = 0; i <= m; i++) {
q[i] = newq[i * 2];
}
n /= 2;
}
return p[0] / q[0];
}快速傅里叶变换 FFT
。
constexpr static double PI = std::numbers::pi;
struct Complex {
double x, y;
Complex(double _x = 0.0, double _y = 0.0) {
x = _x;
y = _y;
}
Complex operator-(const Complex &rhs) const {
return Complex(x - rhs.x, y - rhs.y);
}
Complex operator+(const Complex &rhs) const {
return Complex(x + rhs.x, y + rhs.y);
}
Complex operator*(const Complex &rhs) const {
return Complex(x * rhs.x - y * rhs.y, x * rhs.y + y * rhs.x);
}
};
void change(vector<Complex> &a, int n) {
// 二选一!!!!
// O(n)
vector<int> rev(n + 1);
for (int i = 0; i < n; ++i) {
rev[i] = rev[i >> 1] >> 1;
if (i & 1) rev[i] |= n >> 1; // 如果最后一位是 1,则翻转成 len/2
}
for (int i = 0; i < n; ++i) if (i < rev[i]) swap(a[i], a[rev[i]]); // 保证每对数只翻转一次
// O(nlogn)
// for (int i = 1, j = n / 2; i < n - 1; i++) {
// if (i < j) swap(a[i], a[j]);
// int k = n / 2;
// while (j >= k) {
// j -= k;
// k /= 2;
// }
// if (j < k) j += k;
// }
}
void fft(vector<Complex> &a, int n, int opt) {
change(a, n);
for (int h = 2; h <= n; h *= 2) {
Complex wn(cos(2 * PI / h), sin(opt * 2 * PI / h));
for (int j = 0; j < n; j += h) {
Complex w(1, 0);
for (int k = j; k < j + h / 2; k++, w = w * wn) {
Complex u = a[k], t = w * a[k + h / 2];
a[k] = u + t;
a[k + h / 2] = u - t;
}
}
}
}快速数论变换 NTT
。
void ntt(vector<Z> &a, int len, int opt) {
change(a, len);
for (int h = 2; h <= len; h <<= 1) {
Z gn = mypow(opt == 1 ? G : invG, (mod - 1) / h);
for (int j = 0; j < len; j += h) {
Z g = 1;
for (int k = j; k < j + h / 2; ++k, g = g * gn) {
Z u = a[k], t = g * a[k + h / 2];
a[k] = u + t;
a[k + h / 2] = u - t;
}
}
}
}
Z inv = mypow(Z(len), mod - 2);
for (int i = 0; i <= n + m; ++i) cout << a[i] * inv << ' ';NTT 质数
| (最小原根) | |||
|---|---|---|---|
拉格朗日插值
个点可以唯一确定一个最高为 次的多项式。普通情况: 。
struct Lagrange {
int n;
vector<Z> x, y, fac, invfac;
Lagrange(int n) {
this->n = n;
x.resize(n + 3);
y.resize(n + 3);
fac.resize(n + 3);
invfac.resize(n + 3);
init(n);
}
void init(int n) {
iota(x.begin(), x.end(), 0);
for (int i = 1; i <= n + 2; i++) {
Z t;
y[i] = y[i - 1] + t.power(i, n);
}
fac[0] = 1;
for (int i = 1; i <= n + 2; i++) {
fac[i] = fac[i - 1] * i;
}
invfac[n + 2] = fac[n + 2].inv();
for (int i = n + 1; i >= 0; i--) {
invfac[i] = invfac[i + 1] * (i + 1);
}
}
Z solve(LL k) {
if (k <= n + 2) {
return y[k];
}
vector<Z> sub(n + 3);
for (int i = 1; i <= n + 2; i++) {
sub[i] = k - x[i];
}
vector<Z> mul(n + 3);
mul[0] = 1;
for (int i = 1; i <= n + 2; i++) {
mul[i] = mul[i - 1] * sub[i];
}
Z ans = 0;
for (int i = 1; i <= n + 2; i++) {
ans = ans + y[i] * mul[n + 2] * sub[i].inv() * pow(-1, n + 2 - i) * invfac[i - 1] *
invfac[n + 2 - i];
}
return ans;
}
};myNTT
struct Poly {
vector<Z> a;
Poly() {}
explicit Poly(int size, function<Z(int)> f = [](int) { return 0; }) : a(size) {
for (int i = 0; i < size; i++) a[i] = f(i);
}
Poly(const vector<Z> &a) : a(a) {}
Poly(const initializer_list<Z> &a) : a(a) {}
int size() const {
return a.size();
}
void resize(int n) {
a.resize(n);
}
Z operator[](int idx) const {
if (idx < size()) return a[idx];
else return 0;
}
Z &operator[](int idx) {
return a[idx];
}
friend Poly operator+(const Poly &a, const Poly &b) {
Poly res(max(a.size(), b.size()));
for (int i = 0; i < res.size(); i++) {
if (i < a.size())res[i] = a[i];
if (i < b.size())res[i] += b[i];
}
return res;
}
friend Poly operator-(const Poly &a, const Poly &b) {
Poly res(max(a.size(), b.size()));
for (int i = 0; i < res.size(); i++) {
if (i < a.size()) res[i] = a[i];
if (i < b.size()) res[i] -= b[i];
}
return res;
}
friend Poly operator-(const Poly &a) {
vector<Z> res(a.size());
for (int i = 0; i < a.size(); i++) res[i] = -a[i];
return Poly(res);
}
friend Poly operator*(Poly a, Poly b) {
if (a.size() == 0 || b.size() == 0) return Poly();
if (a.size() < b.size()) swap(a, b);
if (b.size() < 128) { // 小范围暴力卷积可以优化常数
Poly c(a.size() + b.size() - 1);
for (int i = 0; i < a.size(); i++)
for (int j = 0; j < b.size(); j++)
c[i + j] += a[i] * b[j];
return c;
}
int sz = 1, tot = a.size() + b.size() - 1;
while (sz < tot) sz <<= 1;
a.resize(sz), b.resize(sz);
dft(a.a), dft(b.a);
for (int i = 0; i < sz; ++i) a[i] = a[i] * b[i];
idft(a.a);
a.resize(tot);
return a;
}
friend Poly operator*(Z a, Poly b) {
for (int i = 0; i < b.size(); i++) b[i] *= a;
return b;
}
friend Poly operator*(Poly a, Z b) {
for (int i = 0; i < a.size(); i++) a[i] *= b;
return a;
}
Poly &operator+=(Poly b) {
return (*this) = (*this) + b;
}
Poly &operator-=(Poly b) {
return (*this) = (*this) - b;
}
Poly &operator*=(Poly b) {
return (*this) = (*this) * b;
}
Poly &operator*=(Z b) {
return (*this) = (*this) * b;
}
Poly mulxk(int k) const { // 乘x^k
auto b = a;
b.insert(b.begin(), k, 0);
return Poly(b);
}
Poly modxk(int k) const { // 取模x^k
k = min(k, size()); // x^0 ... x^{k-1}
return Poly(vector<Z>(a.begin(), a.begin() + k));
}
Poly divxk(int k) const { // 除x^k
if (size() <= k) return Poly();
return Poly(vector<Z>(a.begin() + k, a.end()));
}
Poly deriv() const { // 求导
if (a.empty()) return Poly();
vector<Z> res(size() - 1);
for (int i = 0; i < size() - 1; ++i) res[i] = (i + 1) * a[i + 1];
return Poly(res);
}
Poly integr() const { // 积分
vector<Z> res(size() + 1);
for (int i = 0; i < size(); ++i) res[i + 1] = a[i] / (i + 1);
return Poly(res);
}
Poly inv(int m) const { // 求逆 O(nlogn)
Poly x{a[0].inv()};
int k = 1;
while (k < m) {
k <<= 1;
x = (x * (Poly{2} - modxk(k) * x)).modxk(k);
}
return x.modxk(m);
}
Poly sqrt(int m) const { // 开根号 O(nlogn)
Poly x{1}; // 对于a0 != 1应求其二次剩余
int k = 1;
Z inv2 = Z(1) / 2;
while (k < m) {
k <<= 1;
x = (x + (modxk(k) * x.inv(k)).modxk(k)) * inv2;
}
return x.modxk(m);
}
Poly log(int m) const { // 取ln O(nlogn)
return (deriv() * inv(m)).integr().modxk(m);
}
Poly exp(int m) const { // 取指数 O(nlogn)
Poly x{1};
int k = 1;
while (k < m) {
k <<= 1;
x = (x * (Poly{1} - x.log(k) + modxk(k))).modxk(k);
}
return x.modxk(m);
}
Poly pow(int k, int m) const { // 多项式快速幂,k次,取m位
int i = 0;
while (i < size() && a[i].val() == 0) i++;
if (i == size() || 1LL * i * k >= m) return Poly(vector<Z>(m));
Z v = a[i];
Poly f = divxk(i) * v.inv();
return (f.log(m - i * k) * k).exp(m - i * k).mulxk(i * k) * power(v, k);
// return (log(m) * k).exp(m);
}
};常用结论
杂
- 求 ,即 ,反转后卷积。
- NTT中,
qpow(G,(mod-1)/n))。 - 遇到 可以转换为 。(单位根卷积)
- 广义二项式定理 。
普通生成函数 / OGF
- 普通生成函数: ;
- ;
- 取对数后 即 (polymul_special);
- ;
- ;
- (借用导数,);
- (二项式定理);
- (归纳法证明);
- (F 为斐波那契数列,列方程 );
- (H 为卡特兰数);
- 前缀和 ;
- 五边形数定理: 。
指数生成函数 / EGF
- 指数生成函数: ;
- 普通生成函数转换为指数生成函数:系数乘以 ;
- ;
- 长度为 的循环置换数为 ,长度为 n 的置换数为 (注意是指数生成函数)
- 个点的生成树个数是 ,n 个点的生成森林个数是 ;
- 个点的无向连通图个数是 ,n 个点的无向图个数是 ;
- 长度为 的循环置换数是 ,长度为 n 的错排数是 。
数据结构
并查集(全功能)
struct DSU {
vector<int> fa, p, e, f;
DSU(int n) {
fa.resize(n + 1);
iota(fa.begin(), fa.end(), 0);
p.resize(n + 1, 1);
e.resize(n + 1);
f.resize(n + 1);
}
int get(int x) {
while (x != fa[x]) {
x = fa[x] = fa[fa[x]];
}
return x;
}
bool merge(int x, int y) { // 设x是y的祖先
if (x == y) f[get(x)] = 1;
x = get(x), y = get(y);
e[x]++;
if (x == y) return false;
if (x < y) swap(x, y); // 将编号小的合并到大的上
fa[y] = x;
f[x] |= f[y], p[x] += p[y], e[x] += e[y];
return true;
}
bool same(int x, int y) {
return get(x) == get(y);
}
bool F(int x) { // 判断连通块内是否存在自环
return f[get(x)];
}
int size(int x) { // 输出连通块中点的数量
return p[get(x)];
}
int E(int x) { // 输出连通块中边的数量
return e[get(x)];
}
};可回溯并查集
struct DSU {
std::vector<int> siz;
std::vector<int> f;
std::vector<std::array<int, 2>> his;
DSU(int n) : siz(n + 1, 1), f(n + 1) {
std::iota(f.begin(), f.end(), 0);
}
int find(int x) {
while (f[x] != x) {
x = f[x];
}
return x;
}
bool merge(int x, int y) {
x = find(x);
y = find(y);
if (x == y) {
return false;
}
if (siz[x] < siz[y]) {
std::swap(x, y);
}
his.push_back({x, y});
siz[x] += siz[y];
f[y] = x;
return true;
}
int time() {
return his.size();
}
void revert(int tm) {
while (his.size() > tm) {
auto [x, y] = his.back();
his.pop_back();
f[y] = y;
siz[x] -= siz[y];
}
}
};树状数组
半动态区间和(单点修改)
struct BIT {
vector<i64> w;
int n;
BIT(int n) : n(n), w(n + 1) {}
void add(int x, i64 v) {
for (; x <= n; x += x & -x) {
w[x] += v;
}
}
i64 rangeAsk(int l, int r) { // 差分实现区间和查询
auto ask = [&](int x) {
i64 ans = 0;
for (; x; x -= x & -x) {
ans += w[x];
}
return ans;
};
return ask(r) - ask(l - 1);
}
};动态区间和(区间修改)
struct BIT {
vector<int> a, b;
int n;
BIT(int n) : n(n), a(n + 1), b(n + 1) {}
void rangeAdd(int l, int r, int val) { // 区间修改
auto add = [&](int pos, int val) {
for (int i = pos; i <= n; i += i & -i) {
a[i] += val;
b[i] += pos * val;
}
};
add(l, val), add(r + 1, -val);
}
int rangeSum(int l, int r) { // 区间和查询
auto sum = [&](int x) {
int ans = 0;
for (int i = x; i; i -= i & -i) {
ans += (x + 1) * a[i] - b[i];
}
return ans;
};
return sum(r) - sum(l - 1);
}
};静态区间最值(单点修改)
struct BIT {
vector<i64> w;
int n;
BIT(int n) : n(n), w(2 * n + 1) {}
void modify(int pos, i64 val) {
for (w[pos += n] = val; pos > 1; pos /= 2) {
w[pos / 2] = max(w[pos], w[pos ^ 1]);
}
}
i64 rangeMax(int l, int r) {
r++; // 使用开区间实现
i64 res = -1e18;
for (l += n, r += n; l < r; l /= 2, r /= 2) {
if (l % 2) res = max(res, w[l++]);
if (r % 2) res = max(res, w[--r]);
}
return res;
}
};逆序对扩展
性质:交换序列的任意两元素,序列的逆序数的奇偶性必定发生改变。
struct BIT {
int n;
vector<int> w, chk; // chk 为传入的待处理数组
BIT(auto &in) : n(in.size() - 1), w(in.size()), chk(in) {}
void add(int x, i64 v) {...}
i64 rangeAsk(int l, int r) {...}
i64 get() {
vector<array<int, 2>> alls;
for (int i = 1; i <= n; i++) {
alls.push_back({chk[i], i});
}
sort(alls.begin(), alls.end());
i64 ans = 0;
for (auto [val, idx] : alls) {
ans += ask(idx + 1, n);
add(idx, 1);
}
return ans;
}
};前驱后继扩展(常规+第 k 小值查询+元素排名查询+元素前驱后继查询)
注意,被查询的值都应该小于等于 ,否则会越界;如果离散化不可使用,则需要使用平衡树替代。
struct BIT {
int n;
vector<int> w;
BIT(int n) : n(n), w(n + 1) {}
void add(int x, int v) {
for (; x <= n; x += x & -x) {
w[x] += v;
}
}
int kth(int x) { // 查找第 k 小的值
int ans = 0;
for (int i = __lg(n); i >= 0; i--) {
int val = ans + (1 << i);
if (val < n && w[val] < x) {
x -= w[val];
ans = val;
}
}
return ans + 1;
}
int get(int x) { // 查找 x 的排名
int ans = 1;
for (x--; x; x -= x & -x) {
ans += w[x];
}
return ans;
}
int pre(int x) { return kth(get(x) - 1); } // 查找 x 的前驱
int suf(int x) { return kth(get(x + 1)); } // 查找 x 的后继
};
const int N = 10000000; // 可以用于在线处理平衡二叉树的全部要求
signed main() {
BIT bit(N + 1); // 在线处理不能够离散化,一定要开到比最大值更大
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
int op, x;
cin >> op >> x;
if (op == 1) bit.add(x, 1); // 插入 x
else if (op == 2) bit.add(x, -1); // 删除任意一个 x
else if (op == 3) cout << bit.get(x) << "\n"; // 查询 x 的排名
else if (op == 4) cout << bit.kth(x) << "\n"; // 查询排名为 x 的数
else if (op == 5) cout << bit.pre(x) << "\n"; // 求小于 x 的最大值(前驱)
else if (op == 6) cout << bit.suf(x) << "\n"; // 求大于 x 的最小值(后继)
}
}二维树状数组
半动态矩阵和(单点修改)
**封装一:该版本不能同时进行区间修改+区间求和。**空间占用为 、建树复杂度为 、单次查询复杂度为 。
template<class T> struct BIT_2D {
int n, m;
vector<vector<T>> w;
BIT_2D(int n, int m) : n(n), m(m) {
w.resize(n + 1, vector<T>(m + 1));
}
void pointAdd(int x, int y, T k) {
for (int i = x; i <= n; i += i & -i) {
for (int j = y; j <= m; j += j & -j) {
w[i][j] += k;
}
}
}
void matrixAdd(int x, int y, int X, int Y, T k) { // 区块修改:二维差分
X++, Y++;
pointAdd(x, y, k), pointAdd(X, y, -k);
pointAdd(X, Y, k), pointAdd(x, Y, -k);
}
T pointSum(int x, int y) {
T ans = T();
for (int i = x; i; i -= i & -i) {
for (int j = y; j; j -= j & -j) {
ans += w[i][j];
}
}
return ans;
}
T matrixSum(int x, int y, int X, int Y) { // 区块查询:二维前缀和
x--, y--;
return pointSum(X, Y) - pointSum(x, Y) - pointSum(X, y) + pointSum(x, y);
}
};动态矩阵和(区间修改)
**封装二:仅支持区间修改+区间求和。**但是时空复杂度均比上一个版本多 倍。
template<class T> struct BIT_2D {
int n, m;
vector<vector<T>> b1, b2, b3, b4;
BIT_2D(int n, int m) : n(n), m(m) {
b1.resize(n + 1, vector<T>(m + 1));
b2.resize(n + 1, vector<T>(m + 1));
b3.resize(n + 1, vector<T>(m + 1));
b4.resize(n + 1, vector<T>(m + 1));
}
void matrixAdd(int x, int y, int X, int Y, T k) { // 区块修改:二维差分
X++, Y++;
auto add = [&](int x, int y, T k) {
for (int i = x; i <= n; i += i & -i) {
for (int j = y; j <= m; j += j & -j) {
b1[i][j] += k;
b2[i][j] += k * (x - 1);
b3[i][j] += k * (y - 1);
b4[i][j] += k * (x - 1) * (y - 1);
}
}
};
add(x, y, k), add(X, y, -k);
add(X, Y, k), add(x, Y, -k);
}
T matrixSum(int x, int y, int X, int Y) { // 区块查询:二维前缀和
x--, y--;
auto ask = [&](int x, int y) {
T ans = T();
for (int i = x; i; i -= i & -i) {
for (int j = y; j; j -= j & -j) {
ans += x * y * b1[i][j];
ans -= y * b2[i][j];
ans -= x * b3[i][j];
ans += b4[i][j];
}
}
return ans;
};
return ask(X, Y) - ask(x, Y) - ask(X, y) + ask(x, y);
}
};线段树
单点修改区间查询
template<class Node>
struct SegmentTree {
#define mid ((l+r)/2)
#define u2 (u<<1)
#define u21 (u<<1|1)
int n;
std::vector<Node> node;
SegmentTree() : n(0) {}
SegmentTree(int n_, Node v_ = Node()) {
init(n_, v_);
}
template<class T>
SegmentTree(std::vector<T> init_) {
init(init_);
}
void init(int n_, Node v_ = Node()) {
init(std::vector(n_, v_));
}
template<class T>
void init(std::vector<T> init_) {
n = init_.size() - 1;
node.assign(4 << std::__lg(n + 1), Node());
auto build = [&](auto build, int u, int l, int r) -> void {
if (r == l)return void(node[u] = init_[l]);
build(build, u2, l, mid), build(build, u21, mid + 1, r);
up(u);
};
build(build, 1, 1, n);
}
void up(int u) {
node[u] = node[u2] + node[u21];
}
void modify(int u, int l, int r, int x, const Node &v) { // l r为线段树区间
if (r == l)return void(node[u] = v);
if (x <= mid) modify(u2, l, mid, x, v);
else modify(u21, mid + 1, r, x, v);
up(u);
}
void modify(int x, const Node &v) {
modify(1, 1, n, x, v);
}
Node ask(int u, int l, int r, int x, int y) { // x y为询问区间,l r为线段树区间
if (l > y || r < x)return Node();
if (x <= l && r <= y)return node[u];
if (y <= mid) return ask(u2, l, mid, x, y);
else if (mid < x) return ask(u21, mid + 1, r, x, y);
else return ask(u2, l, mid, x, y) + ask(u21, mid + 1, r, x, y);
}
Node ask(int l, int r) {
return ask(1, 1, n, l, r);
}
#undef mid
#undef u2
#undef u21
};区间修改区间查询
template<class Node, class Tag>
struct LazySegmentTree {
#define mid ((l+r)>>1)
#define u2 (u<<1)
#define u21 (u<<1|1)
int n;
std::vector<Node> node;
std::vector<Tag> tag;
LazySegmentTree() : n(0) {}
LazySegmentTree(int n_, Node v_ = Node()) {
init(n_, v_);
}
template<class T>
LazySegmentTree(std::vector<T> init_) {
init(init_);
}
void init(int n_, Node v_ = Node()) {
init(std::vector(n_ + 1, v_));
}
template<class T>
void init(std::vector<T> init_) {
n = init_.size() - 1;
node.assign(4 << std::__lg(n), Node());
tag.assign(4 << std::__lg(n), Tag());
auto build = [&](auto build, int u, int l, int r) -> void {
if (r == l) return void(node[u] = init_[l]);
build(build, u2, l, mid), build(build, u21, mid + 1, r);
up(u);
};
build(build, 1, 1, n);
}
void up(int u) {
node[u] = node[u2] + node[u21];
}
void apply(int u, const Tag &v) { // 懒标记
node[u].apply(v);
tag[u].apply(v);
}
void down(int u) { //下放懒标记
apply(u2, tag[u]), apply(u21, tag[u]);
tag[u] = Tag(); // u的标记置空
}
void modify(int u, int l, int r, int x, const Node &v) { // 单点修改 x
if (r == l) return void(node[u] = v);
down(u);
if (x <= mid) modify(u2, l, mid, x, v);
else modify(u21, mid + 1, r, x, v);
up(u);
}
void modify(int x, const Node &v) { // 单点修改 x
modify(1, 1, n, x, v);
}
Node ask(int u, int l, int r, int x, int y) { // 区间询问 x y
if (l > y || r < x) return Node();
if (x <= l && r <= y) return node[u];
down(u);
if (y <= mid)return ask(u2, l, mid, x, y);
else if (mid < x) return ask(u21, mid + 1, r, x, y);
else return ask(u2, l, mid, x, y) + ask(u21, mid + 1, r, x, y);
}
Node ask(int x, int y) {
return ask(1, 1, n, x, y);
}
void modify(int u, int l, int r, int x, int y, const Tag &v) { // 区间修改 x y
if (l > y || r < x) return;
if (x <= l && r <= y) return void(apply(u, v));
down(u);
modify(u2, l, mid, x, y, v), modify(u21, mid + 1, r, x, y, v);
up(u);
}
void modify(int x, int y, const Tag &v) { // 区间修改 x y
modify(1, 1, n, x, y, v);
}
#undef mid
#undef u2
#undef u21
};区间加法修改、区间最小值查询
template<class T> struct Segt {
struct node {
int l, r;
T w, rmq, lazy;
};
vector<T> w;
vector<node> t;
Segt() {}
Segt(int n) { init(n); }
Segt(vector<int> in) {
int n = in.size() - 1;
w.resize(n + 1);
for (int i = 1; i <= n; i++) {
w[i] = in[i];
}
init(in.size() - 1);
}
#define GL (k << 1)
#define GR (k << 1 | 1)
void init(int n) {
w.resize(n + 1);
t.resize(n * 4 + 1);
auto build = [&](auto self, int l, int r, int k = 1) {
if (l == r) {
t[k] = {l, r, w[l], w[l], -1}; // 如果有赋值为 0 的操作,则懒标记必须要 -1
return;
}
t[k] = {l, r, 0, 0, -1};
int mid = (l + r) / 2;
self(self, l, mid, GL);
self(self, mid + 1, r, GR);
pushup(k);
};
build(build, 1, n);
}
void pushdown(node &p, T lazy) { /* 【在此更新下递函数】 */
p.w += (p.r - p.l + 1) * lazy;
p.rmq += lazy;
p.lazy += lazy;
}
void pushdown(int k) {
if (t[k].lazy == -1) return;
pushdown(t[GL], t[k].lazy);
pushdown(t[GR], t[k].lazy);
t[k].lazy = -1;
}
void pushup(int k) {
auto pushup = [&](node &p, node &l, node &r) { /* 【在此更新上传函数】 */
p.w = l.w + r.w;
p.rmq = min(l.rmq, r.rmq); // RMQ -> min/max
};
pushup(t[k], t[GL], t[GR]);
}
void modify(int l, int r, T val, int k = 1) { // 区间修改
if (l <= t[k].l && t[k].r <= r) {
pushdown(t[k], val);
return;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) modify(l, r, val, GL);
if (mid < r) modify(l, r, val, GR);
pushup(k);
}
T rmq(int l, int r, int k = 1) { // 区间询问最小值
if (l <= t[k].l && t[k].r <= r) {
return t[k].rmq;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
T ans = numeric_limits<T>::max(); // RMQ -> 为 max 时需要修改为 ::lowest()
if (l <= mid) ans = min(ans, rmq(l, r, GL)); // RMQ -> min/max
if (mid < r) ans = min(ans, rmq(l, r, GR)); // RMQ -> min/max
return ans;
}
T ask(int l, int r, int k = 1) { // 区间询问
if (l <= t[k].l && t[k].r <= r) {
return t[k].w;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
T ans = 0;
if (l <= mid) ans += ask(l, r, GL);
if (mid < r) ans += ask(l, r, GR);
return ans;
}
void debug(int k = 1) {
cout << "[" << t[k].l << ", " << t[k].r << "]: ";
cout << "w = " << t[k].w << ", ";
cout << "Min = " << t[k].rmq << ", ";
cout << "lazy = " << t[k].lazy << ", ";
cout << endl;
if (t[k].l == t[k].r) return;
debug(GL), debug(GR);
}
};同时需要处理区间加法与乘法修改
template <class T> struct Segt_ {
struct node {
int l, r;
T w, add, mul = 1; // 注意初始赋值
};
vector<T> w;
vector<node> t;
Segt_(int n) {
w.resize(n + 1);
t.resize((n << 2) + 1);
build(1, n);
}
Segt_(vector<int> in) {
int n = in.size() - 1;
w.resize(n + 1);
for (int i = 1; i <= n; i++) {
w[i] = in[i];
}
t.resize((n << 2) + 1);
build(1, n);
}
void pushdown(node &p, T add, T mul) { // 在此更新下递函数
p.w = p.w * mul + (p.r - p.l + 1) * add;
p.add = p.add * mul + add;
p.mul *= mul;
}
void pushup(node &p, node &l, node &r) { // 在此更新上传函数
p.w = l.w + r.w;
}
#define GL (k << 1)
#define GR (k << 1 | 1)
void pushdown(int k) { // 不需要动
pushdown(t[GL], t[k].add, t[k].mul);
pushdown(t[GR], t[k].add, t[k].mul);
t[k].add = 0, t[k].mul = 1;
}
void pushup(int k) { // 不需要动
pushup(t[k], t[GL], t[GR]);
}
void build(int l, int r, int k = 1) {
if (l == r) {
t[k] = {l, r, w[l]};
return;
}
t[k] = {l, r};
int mid = (l + r) / 2;
build(l, mid, GL);
build(mid + 1, r, GR);
pushup(k);
}
void modify(int l, int r, T val, int k = 1) { // 区间修改
if (l <= t[k].l && t[k].r <= r) {
t[k].w += (t[k].r - t[k].l + 1) * val;
t[k].add += val;
return;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) modify(l, r, val, GL);
if (mid < r) modify(l, r, val, GR);
pushup(k);
}
void modify2(int l, int r, T val, int k = 1) { // 区间修改
if (l <= t[k].l && t[k].r <= r) {
t[k].w *= val;
t[k].add *= val;
t[k].mul *= val;
return;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) modify2(l, r, val, GL);
if (mid < r) modify2(l, r, val, GR);
pushup(k);
}
T ask(int l, int r, int k = 1) { // 区间询问,不合并
if (l <= t[k].l && t[k].r <= r) {
return t[k].w;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
T ans = 0;
if (l <= mid) ans += ask(l, r, GL);
if (mid < r) ans += ask(l, r, GR);
return ans;
}
void debug(int k = 1) {
cout << "[" << t[k].l << ", " << t[k].r << "]: ";
cout << "w = " << t[k].w << ", ";
cout << "add = " << t[k].add << ", ";
cout << "mul = " << t[k].mul << ", ";
cout << endl;
if (t[k].l == t[k].r) return;
debug(GL), debug(GR);
}
};区间赋值/推平
如果存在推平为 的操作,那么需要将 lazy 初始赋值为 。
void pushdown(node &p, T lazy) { /* 【在此更新下递函数】 */
p.w = (p.r - p.l + 1) * lazy;
p.lazy = lazy;
}
void modify(int l, int r, T val, int k = 1) {
if (l <= t[k].l && t[k].r <= r) {
t[k].w = val;
t[k].lazy = val;
return;
}
// 剩余部分不变
}区间取模
原题需要进行“单点赋值+区间取模+区间求和” See 。该操作不需要懒标记。
需要额外维护一个区间最大值,当模数大于区间最大值时剪枝,否则进行单点取模。由于单点 时 ,故单点取模至 最劣只需要 次 。
void modifyMod(int l, int r, T val, int k = 1) {
if (l <= t[k].l && t[k].r <= r) {
if (t[k].rmq < val) return; // 重要剪枝
}
if (t[k].l == t[k].r) {
t[k].w %= val;
t[k].rmq %= val;
return;
}
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) modifyMod(l, r, val, GL);
if (mid < r) modifyMod(l, r, val, GR);
pushup(k);
}区间异或修改
原题需要维护”区间异或修改+区间求和“ See 。
struct Segt { // #define GL (k << 1) // #define GR (k << 1 | 1)
struct node {
int l, r;
int w[N], lazy; // 注意这里为了方便计算,w 只需要存位
};
vector<int> base;
vector<node> t;
Segt(vector<int> in) : base(in) {
int n = in.size() - 1;
t.resize(n * 4 + 1);
auto build = [&](auto self, int l, int r, int k = 1) {
t[k] = {l, r}; // 前置赋值
if (l == r) {
for (int i = 0; i < N; i++) {
t[k].w[i] = base[l] >> i & 1;
}
return;
}
int mid = (l + r) / 2;
self(self, l, mid, GL);
self(self, mid + 1, r, GR);
pushup(k);
};
build(build, 1, n);
}
void pushdown(node &p, int lazy) { /* 【在此更新下递函数】 */
int len = p.r - p.l + 1;
for (int i = 0; i < N; i++) {
if (lazy >> i & 1) { // 即 p.w = (p.r - p.l + 1) - p.w;
p.w[i] = len - p.w[i];
}
}
p.lazy ^= lazy;
}
void pushdown(int k) { // 【不需要动】
if (t[k].lazy == 0) return;
pushdown(t[GL], t[k].lazy);
pushdown(t[GR], t[k].lazy);
t[k].lazy = 0;
}
void pushup(int k) {
auto pushup = [&](node &p, node &l, node &r) { /* 【在此更新上传函数】 */
for (int i = 0; i < N; i++) {
p.w[i] = l.w[i] + r.w[i]; // 即 p.w = l.w + r.w;
}
};
pushup(t[k], t[GL], t[GR]);
}
void modify(int l, int r, int val, int k = 1) { // 区间修改
if (l <= t[k].l && t[k].r <= r) {
pushdown(t[k], val);
return;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) modify(l, r, val, GL);
if (mid < r) modify(l, r, val, GR);
pushup(k);
}
i64 ask(int l, int r, int k = 1) { // 区间求和
if (l <= t[k].l && t[k].r <= r) {
i64 ans = 0;
for (int i = 0; i < N; i++) {
ans += t[k].w[i] * (1LL << i);
}
return ans;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
i64 ans = 0;
if (l <= mid) ans += ask(l, r, GL);
if (mid < r) ans += ask(l, r, GR);
return ans;
}
};拆位运算
原题同上。使用若干棵线段树维护每一位的值,区间异或转变为区间翻转。
template<class T> struct Segt_ { // GL 为 (k << 1),GR 为 (k << 1 | 1)
struct node {
int l, r;
T w;
bool lazy; // 注意懒标记用布尔型足以
};
vector<T> w;
vector<node> t;
Segt_() {}
void init(vector<int> in) {
int n = in.size() - 1;
w.resize(n * 4 + 1);
for (int i = 0; i <= n; i++) { w[i] = in[i]; }
t.resize(n * 4 + 1);
build(1, n);
}
void pushdown(node &p, bool lazy = 1) { // 【在此更新下递函数】
p.w = (p.r - p.l + 1) - p.w;
p.lazy ^= lazy;
}
void pushup(node &p, node &l, node &r) { // 【在此更新上传函数】
p.w = l.w + r.w;
}
void pushdown(int k) { // 【不需要动】
if (t[k].lazy == 0) return;
pushdown(t[GL]), pushdown(t[GR]); // 注意这里不再需要传入第二个参数
t[k].lazy = 0;
}
void pushup(int k) { pushup(t[k], t[GL], t[GR]); } // 【不需要动】
void build(int l, int r, int k = 1) {
if (l == r) {
t[k] = {l, r, w[l], 0}; // 注意懒标记初始为 0
return;
}
t[k] = {l, r};
int mid = (l + r) / 2;
build(l, mid, GL);
build(mid + 1, r, GR);
pushup(k);
}
void reverse(int l, int r, int k = 1) { // 区间翻转
if (l <= t[k].l && t[k].r <= r) {
pushdown(t[k], 1);
return;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
if (l <= mid) reverse(l, r, GL);
if (mid < r) reverse(l, r, GR);
pushup(k);
}
T ask(int l, int r, int k = 1) { // 区间求和
if (l <= t[k].l && t[k].r <= r) {
return t[k].w;
}
pushdown(k);
int mid = (t[k].l + t[k].r) / 2;
T ans = 0;
if (l <= mid) ans += ask(l, r, GL);
if (mid < r) ans += ask(l, r, GR);
return ans;
}
};
signed main() {
int n; cin >> n;
vector in(20, vector<int>(n + 1));
Segt_<i64> segt[20]; // 拆位建线段树
for (int i = 1, x; i <= n; i++) { cin >> x;
for (int bit = 0; bit < 20; bit++) {
in[bit][i] = x >> bit & 1;
}
}
for (int i = 0; i < 20; i++) {
segt[i].init(in[i]);
}
int m, op;
for (cin >> m; m; m--) { cin >> op;
if (op == 1) {
int l, r; i64 ans = 0; cin >> l >> r;
for (int i = 0; i < 20; i++) {
ans += segt[i].ask(l, r) * (1LL << i);
}
cout << ans << "\n";
} else {
int l, r, val; cin >> l >> r >> val;
for (int i = 0; i < 20; i++) {
if (val >> i & 1) { segt[i].reverse(l, r); }
}
}
}
}坐标压缩与离散化
简单版本
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
auto get = [&](int x) {
return lower_bound(alls.begin(), alls.end(), x) - alls.begin();
};封装
template <typename T> struct Compress_ {
int n, shift = 0; // shift 用于标记下标偏移量
vector<T> alls;
Compress_() {}
Compress_(auto in) : alls(in) {
init();
}
void add(T x) {
alls.emplace_back(x);
}
template <typename... Args> void add(T x, Args... args) {
add(x), add(args...);
}
void init() {
alls.emplace_back(numeric_limits<T>::max());
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
this->n = alls.size();
}
int size() {
return n;
}
int operator[](T x) { // 返回 x 元素的新下标
return upper_bound(alls.begin(), alls.end(), x) - alls.begin() + shift;
}
T Get(int x) { // 根据新下标返回原来元素
assert(x - shift < n);
return x - shift < n ? alls[x - shift] : -1;
}
bool count(T x) { // 查找元素 x 是否存在
return binary_search(alls.begin(), alls.end(), x);
}
friend auto &operator<< (ostream &o, const auto &j) {
cout << "{";
for (auto it : j.alls) {
o << it << " ";
}
return o << "}";
}
};
using Compress = Compress_<int>;分块
struct Block {
int n, blo, tot;
vector<int> L, R, bel;
Block() : n(0) {}
Block(int n_) {
this->n = n_;
init(n);
}
void init(int n_) {
blo = sqrt(n_); // 块的大小
tot = (n_ + blo - 1) / blo; // 块数
L.resize(tot + 1), R.resize(tot + 1); // 第i个块的起始点与结束点
bel.resize(n_ + 1); // a_i所属的块
for (int i = 1; i <= tot; ++i) L[i] = R[i - 1] + 1, R[i] = i * blo;
R[tot] = n_;
for (int i = 1; i <= n_; ++i) bel[i] = (i - 1) / blo + 1;
}
};轻重链剖分/树链剖分
将线段树处理的部分分离,方便修改。支持链上查询/修改、子树查询/修改,建树时间复杂度 ,单次查询时间复杂度 。
struct HLD {
int n, idx;
vector<vector<int>> ver;
vector<int> siz, dep;
vector<int> top, son, parent;
vector<int> in, id, val;
Segt segt;
HLD(int n) {
this->n = n;
ver.resize(n + 1);
siz.resize(n + 1);
dep.resize(n + 1);
top.resize(n + 1);
son.resize(n + 1);
parent.resize(n + 1);
idx = 0;
in.resize(n + 1);
id.resize(n + 1);
val.resize(n + 1);
}
void add(int x, int y) { // 建立双向边
ver[x].push_back(y);
ver[y].push_back(x);
}
void dfs1(int x) {
siz[x] = 1;
dep[x] = dep[parent[x]] + 1;
for (auto y : ver[x]) {
if (y == parent[x]) continue;
parent[y] = x;
dfs1(y);
siz[x] += siz[y];
if (siz[y] > siz[son[x]]) {
son[x] = y;
}
}
}
void dfs2(int x, int up) {
id[x] = ++idx;
val[idx] = in[x]; // 建立编号
top[x] = up;
if (son[x]) dfs2(son[x], up);
for (auto y : ver[x]) {
if (y == parent[x] || y == son[x]) continue;
dfs2(y, y);
}
}
void modify(int l, int r, int val) { // 链上修改
while (top[l] != top[r]) {
if (dep[top[l]] < dep[top[r]]) {
swap(l, r);
}
segt.modify(id[top[l]], id[l], val);
l = parent[top[l]];
}
if (dep[l] > dep[r]) {
swap(l, r);
}
segt.modify(id[l], id[r], val);
}
void modify(int root, int val) { // 子树修改
segt.modify(id[root], id[root] + siz[root] - 1, val);
}
int ask(int l, int r) { // 链上查询
int ans = 0;
while (top[l] != top[r]) {
if (dep[top[l]] < dep[top[r]]) {
swap(l, r);
}
ans += segt.ask(id[top[l]], id[l]);
l = parent[top[l]];
}
if (dep[l] > dep[r]) {
swap(l, r);
}
return ans + segt.ask(id[l], id[r]);
}
int ask(int root) { // 子树查询
return segt.ask(id[root], id[root] + siz[root] - 1);
}
void work(auto in, int root = 1) { // 在此初始化
assert(in.size() == n + 1);
this->in = in;
dfs1(root);
dfs2(root, root);
segt.init(val); // 建立线段树
}
void work(int root = 1) { // 在此初始化
dfs1(root);
dfs2(root, root);
segt.init(val); // 建立线段树
}
};动态直径
一颗有根树
改变的是第几条边的值
struct Dynamic_Diameter{
int n;
vector<vector<pair<int,int>>> e;
vector<int> a,b,val; int g;
vector<int> dfn,dep;int cnt;
vector<int> l,r,f;
struct NODE{
int ans,mx,mn,lm,rm,lazy;
};
vector<NODE> t;
Dynamic_Diameter(int n){
this->n = n;
cnt = 0;g = 0;
e.resize(n + 1);
a.resize(n + 1);
b.resize(n + 1);
dfn.resize(2*n+1);
val.resize(n + 1);
dep.resize(n + 1);
l.resize(n + 1);
r.resize(n + 1);
f.resize(n + 1);
t.resize(8*n + 1);
}
void addEdge(int u,int v,int c){
a[++g] = u;b[g] = v;val[g] = c;
e[u].push_back({v,c});
e[v].push_back({u,c});
}
void dfs(int u,int fa){
dfn[++cnt] = u;
l[u] = r[u] = cnt;
for(auto [v,dis]:e[u]){
if(v == fa)continue;
f[v] = u;
dep[v] = dep[u] + dis;
dfs(v,u);
dfn[++cnt] = u;
r[u] = cnt;
}
}
void upd(int p){
t[p].ans = max({t[p << 1].ans,t[p << 1 | 1].ans,t[p << 1].rm+t[p << 1 | 1].mx,t[p << 1].mx+t[p << 1 | 1].lm});
t[p].mx = max(t[p << 1].mx,t[p << 1 | 1].mx);
t[p].mn = min(t[p << 1].mn,t[p << 1 | 1].mn);
t[p].lm = max({t[p << 1].lm,t[p << 1 | 1].lm,t[p << 1 | 1].mx-t[p << 1].mn*2});
t[p].rm = max({t[p << 1].rm,t[p << 1 | 1].rm,t[p << 1].mx-t[p << 1|1].mn*2});
}
void spd(int p){
int lazy = t[p].lazy;
t[p << 1].mx += lazy;t[p << 1 | 1].mx += lazy;
t[p << 1].mn += lazy;t[p << 1 | 1].mn += lazy;
t[p << 1].lm -= lazy;t[p << 1 | 1].lm -= lazy;
t[p << 1].rm -= lazy;t[p << 1 | 1].rm -= lazy;
t[p << 1].lazy += lazy;t[p << 1 | 1].lazy += lazy;
t[p].lazy = 0;
}
void add(int ql,int qr,int num,int p,int l,int r){
if(ql <= l && r <= qr){
t[p].lm -= num;t[p].rm -= num;
t[p].mx += num;t[p].mn += num;
t[p].lazy += num;
return;
}else if(r < ql || l > qr)return;
spd(p);
int mid = (l+r)>>1;
add(ql,qr,num,p<<1,l,mid);
add(ql,qr,num,p<<1|1,mid+1,r);
upd(p);
}
void build(int p,int l,int r){
if(l == r){
t[p].mx = t[p].mn = dep[dfn[l]];
t[p].lm = t[p].rm = -dep[dfn[l]];
return;
}
int mid = (l+r)>>1;
build(p << 1,l,mid);
build(p << 1|1,mid+1,r);
upd(p);
}
void init(int root = 1){
dfs(root,0);
build(1,1,cnt);
}
void modify(int p,int num){
int delta = num - val[p];
if(f[b[p]] == a[p])add(l[b[p]],r[b[p]],delta,1,1,cnt);
if(f[a[p]] == b[p])add(l[a[p]],r[a[p]],delta,1,1,cnt);
val[p] = num;
}
int answer(){
return t[1].ans;
}
};LCT
0 x y代表询问从 到 的路径上的点的权值的 和。保证 到 是联通的。1 x y代表连接 到 ,若 到 已经联通则无需连接。2 x y代表删除边 ,不保证边 存在。3 x y代表将点 上的权值变成 。
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
#ifndef __VectorBuffer
#define __VectorBuffer
namespace __VectorBuffer {
template<typename T>
struct VectorBuffer {
static vector<T> buf;
static vector<int> gc;
static int gen() {
if (!gc.empty()) {
int r = gc.back();
gc.pop_back();
buf[r] = T();
return r;
}
buf.push_back(T());
return int(buf.size()) - 1;
}
static void remove(int pos) { gc.push_back(pos); }
static int size() { return buf.size(); }
static T *ptr(int pos) { return buf.data() + pos; }
};
template<typename T> vector<T> VectorBuffer<T>::buf(1, T());
template<typename T> vector<int> VectorBuffer<T>::gc(0);
};
using __VectorBuffer::VectorBuffer;
#endif
template<class T>
struct LineCutTree {
struct Node {
T x;
int lc, rc, rev, fa;
Node() : x(T()), lc(0), rc(0), rev(0), fa(0) {}
int &p(int x) {
if (x == 0) return lc;
return rc;
}
Node *lchild() const { return ptr(lc); }
Node *rchild() const { return ptr(rc); }
void pushup() { x.pushup(&(ptr(lc)->x), &(ptr(rc)->x)); }
void pushdown() {
if (rev) {
ptr(lc)->rev ^= 1;
ptr(rc)->rev ^= 1;
rev ^= 1;
swap(lc, rc);
}
x.pushdown(&(ptr(lc)->x), &(ptr(rc)->x));
}
};
using Buf = VectorBuffer<Node>;
static Node *ptr(int pos) {
return Buf::ptr(pos);
}
vector<int> idx;
LineCutTree(const int n) : idx(n + 1) { for (int i = 1; i <= n; i++) idx[i] = Buf::gen(); }
bool is_root(int x) {
int y = ptr(x)->fa;
return ptr(y)->lc != x && ptr(y)->rc != x;
}
void pushup(int x) { ptr(x)->pushup(); }
void pushdown(int x) { ptr(x)->pushdown(); }
void rotate(int x) {
int y = ptr(x)->fa, z = ptr(y)->fa;
int l = (ptr(y)->lc != x), r = l ^ 1;
if (!is_root(y)) {
if (ptr(z)->lc == y) ptr(z)->lc = x;
else ptr(z)->rc = x;
}
ptr(x)->fa = z;
ptr(y)->fa = x;
ptr(ptr(x)->p(r))->fa = y;
ptr(y)->p(l) = ptr(x)->p(r);
ptr(x)->p(r) = y;
pushup(y);
pushup(x);
}
stack<int> st;
void splay(int x) {
st.push(x);
for (int i = x; !is_root(i); i = ptr(i)->fa) st.push(ptr(i)->fa);
while (!st.empty()) {
pushdown(st.top());
st.pop();
}
while (!is_root(x)) {
int y = ptr(x)->fa, z = ptr(y)->fa;
if (!is_root(y)) {
if ((ptr(y)->lc == x) ^ (ptr(z)->lc == y)) rotate(x);
else rotate(y);
}
rotate(x);
}
}
void access(int x) {
for (int i = 0; x; i = x, x = ptr(x)->fa) {
splay(x);
ptr(x)->rc = i;
pushup(x);
}
}
void make_root(int x) {
access(x);
splay(x);
ptr(x)->rev ^= 1;
}
void split(int x, int y) {
make_root(x);
access(y);
splay(y);
}
int find_root(int x) {
access(x);
splay(x);
while (ptr(x)->lc) x = ptr(x)->lc;
splay(x);
return x;
};
void cut(int x, int y) {
make_root(x);
if (find_root(y) != x) return;
if (ptr(y)->fa == x && ptr(y)->lc == 0) {
ptr(x)->rc = ptr(y)->fa = 0;
pushup(x);
}
}
void link(int x, int y) {
make_root(x);
if (find_root(y) != x) ptr(x)->fa = y;
}
T &operator[](int pos) {
return ptr(pos)->x;
}
};
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
struct Node {
int val, sum;
void pushup(Node *x, Node *y) { sum = (x->sum) ^ (y->sum) ^ val; }
void pushdown(Node *x, Node *y) {}
};
int n, m;
cin >> n >> m;
LineCutTree<Node> lct(n);
for (int i = 1; i <= n; i++) {
int x;
cin >> x;
lct[i] = {x, x};
}
while (m--) {
int op, x, y;
cin >> op >> x >> y;
if (op == 0) {
lct.split(x, y);
cout << lct[y].sum << "\n";
}
if (op == 1) lct.link(x, y);
if (op == 2) lct.cut(x, y);
if (op == 3) {
lct.splay(x);
lct[x].val = y;
lct.pushup(x);
}
}
return 0;
}strong LCT
给你一棵 个节点的有根树,点带权,有 次操作,分为十二种:
0 x y表示将 的子树中所有点权都改为 ;1 x表示把树根换为 节点;2 x y z表示把 到 简单路径上所有点权改为 ;3 x表示询问 的子树中最小权值;4 x表示询问 的子树中最大权值;5 x y表示将 的子树中所有点权都增加 ;6 x y z表示将 到 简单路径上所有点权加上 ;7 x y表示询问 到 简单路径上的最小权值;8 x y表示询问 到 简单路径上的最大权值;9 x y表示把 的父亲换为 ,若 在 的子树里则忽略此操作;10 x y表示询问 到 简单路径上的点权和;11 x表示询问 的子树中点权和。
#include<cstdio>
#define int ll
template<class type>inline const void swap(type &a,type &b)
{
const type c(a);a=b;b=c;
}
template<class type>inline const type min(const type &a,const type &b)
{
return a<b?a:b;
}
template<class type>inline const type max(const type &a,const type &b)
{
return a>b?a:b;
}
template<class type>inline const void read(type &in)
{
in=0;char ch(getchar());bool f(0);
while (ch<48||ch>57){if (ch=='-')f=1;ch=getchar();}
while (ch>47&&ch<58)in=(in<<3)+(in<<1)+(ch&15),ch=getchar();
if (f)in=-in;
}
typedef long long ll;
const int N(1e5+10);
int cnt;
namespace Self_Adjusting_Top_Trees{
const bool compress(0),rake(1);
const int inf(2147483647);
struct tree{
bool rev;
tree *son[3],*fa;
static tree *null;
int path_size,subtree_size;
int path_add,subtree_add,path_cov,subtree_cov;
int val,subtree_sum,path_sum,subtree_min,path_min,subtree_max,path_max;
void *operator new(size_t size);
void *operator new[](size_t size);
void operator delete(void *ptr);
inline tree():rev(0),val(0),subtree_size(0),path_size(0),path_add(0),subtree_add(0),path_sum(0),subtree_sum(0),path_min(inf),subtree_min(inf),path_cov(0),subtree_cov(0),subtree_max(-inf),path_max(-inf){
static bool init(0);
if (!init){
init=1;
null=new tree;
null->son[0]=null->son[1]=null->son[2]=null->fa=null;
}
son[0]=son[1]=son[2]=fa=null;
}
inline const int id(){
return fa->son[1]==this;
}
inline const void set(tree *p,const int &f){
son[f]=p;p->fa=this;
}
inline const bool isroot(){
return fa->son[0]!=this&&fa->son[1]!=this;
}
inline const void reverse(){
if (this==null)return;swap(son[0],son[1]);rev^=1;
}
template<const bool type>inline const void pushup(){}
template<const bool type>inline const void pushdown(){}
template<const bool type>inline const void rotate(){
fa->pushdown<type>();pushdown<type>();
const bool f(id());
tree *fa(this->fa);
if (fa->fa!=null)fa->fa->son[fa->fa->son[2]==fa?2:fa->id()]=this;
this->fa=fa->fa;
fa->set(son[!f],f);set(fa,!f);
fa->pushup<type>();pushup<type>();
}
template<const bool type>inline const void splay(tree *goal=null){
for (pushdown<type>();fa!=goal&&!isroot();rotate<type>())
if (fa->fa!=goal&&!fa->isroot())
fa->fa->pushdown<type>(),
(fa->id()^id()?this:fa)->rotate<type>();
}
template<const bool type,const bool d>inline const void splay_m(){
tree *p(this);
while (p->pushdown<type>(),p->son[d]!=null)p=p->son[d];
p->splay<type>(fa);
}
inline const void path_plus(const int &w){
if (this==null)return;
val+=w;path_sum+=path_size*w;path_min+=w;path_max+=w;path_add+=w;
}
inline const void path_cover(const int &w){
if (this==null)return;
val=w;path_sum=path_size*w;path_min=path_max=path_cov=w;path_add=0;
}
inline const void subtree_plus(const int &w){
if (this==null)return;
subtree_sum+=subtree_size*w;subtree_min+=w;subtree_max+=w;subtree_add+=w;
}
inline const void subtree_cover(const int &w){
if (this==null)return;
subtree_sum=subtree_size*w;subtree_min=subtree_max=subtree_cov=w;subtree_add=0;
}
}*root,*node0,*tree::null;
#define null tree::null
template<>inline const void tree::pushup<compress>(){
path_size=son[0]->path_size+1+son[1]->path_size;
subtree_size=son[0]->subtree_size+son[1]->subtree_size+son[2]->subtree_size;
path_sum=son[0]->path_sum+val+son[1]->path_sum;
path_min=min(val,min(son[0]->path_min,son[1]->path_min));
path_max=max(val,max(son[0]->path_max,son[1]->path_max));
subtree_sum=son[0]->subtree_sum+son[1]->subtree_sum+son[2]->subtree_sum;
subtree_min=min(son[2]->subtree_min,min(son[0]->subtree_min,son[1]->subtree_min));
subtree_max=max(son[2]->subtree_max,max(son[0]->subtree_max,son[1]->subtree_max));
}
template<>inline const void tree::pushup<rake>(){
subtree_size=son[0]->subtree_size+son[1]->subtree_size+son[2]->path_size+son[2]->subtree_size;
subtree_sum=son[0]->subtree_sum+son[1]->subtree_sum+son[2]->path_sum+son[2]->subtree_sum;
subtree_min=min(min(son[0]->subtree_min,son[1]->subtree_min),min(son[2]->path_min,son[2]->subtree_min));
subtree_max=max(max(son[0]->subtree_max,son[1]->subtree_max),max(son[2]->path_max,son[2]->subtree_max));
}
template<>inline const void tree::pushdown<compress>(){
if (rev)son[0]->reverse(),son[1]->reverse(),rev=0;
if (path_cov)son[0]->path_cover(path_cov),son[1]->path_cover(path_cov),path_cov=0;
if (path_add)son[0]->path_plus(path_add),son[1]->path_plus(path_add),path_add=0;
if (subtree_cov)son[0]->subtree_cover(subtree_cov),son[1]->subtree_cover(subtree_cov),son[2]->subtree_cover(subtree_cov),subtree_cov=0;
if (subtree_add)son[0]->subtree_plus(subtree_add),son[1]->subtree_plus(subtree_add),son[2]->subtree_plus(subtree_add),subtree_add=0;
}
template<>inline const void tree::pushdown<rake>(){
if (subtree_cov)
son[0]->subtree_cover(subtree_cov),son[1]->subtree_cover(subtree_cov),
son[2]->subtree_cover(subtree_cov),son[2]->path_cover(subtree_cov),subtree_cov=0;
if (subtree_add)
son[0]->subtree_plus(subtree_add),son[1]->subtree_plus(subtree_add),
son[2]->subtree_plus(subtree_add),son[2]->path_plus(subtree_add),subtree_add=0;
}
const int maxn(N<<1);
char memory_pool[maxn*sizeof(tree)],*tail(memory_pool+sizeof(memory_pool));
void *recycle[maxn],**top(recycle);
inline void *tree::operator new(size_t size){return top!=recycle?*--top:tail-=size;}
inline void *tree::operator new[](size_t size){return tail-=size;}
inline void tree::operator delete(void *ptr){*top++=ptr;}
inline tree *node(const int &x){return node0+x;}
inline const void splice(tree *p){
p->splay<rake>();
(p=p->fa)->splay<compress>();
tree *q(p->son[2]);
q->pushdown<rake>();
if (p->son[1]!=null)
swap(p->son[1]->fa,q->son[2]->fa),
swap(p->son[1],q->son[2]);
else{
p->set(q->son[2],1);
if (q->son[0]!=null)
q->son[0]->splay_m<rake,1>(),
q->son[0]->set(q->son[1],1),
p->son[2]=q->son[0];
else
q->son[1]->pushdown<rake>(),
p->son[2]=q->son[1];
delete q;q=p->son[2];q->fa=p;
}
q->pushup<rake>();p->pushup<compress>();
p->son[1]->rotate<compress>();
}
inline const void access(tree *p){
p->splay<compress>();
if (p->son[1]!=null){
tree *q(new tree);
q->set(p->son[2],0);
q->set(p->son[1],2);
q->pushup<rake>();
p->son[1]=null;
p->set(q,2);
p->pushup<compress>();
}
while (p->fa!=null)splice(p->fa);
}
inline const void evert(tree *p){
access(p);p->reverse();
}
inline const void expose(tree *p,tree *q){
evert(p);access(q);
}
inline tree *findroot(tree *p){
for (access(p);p->son[0]!=null;p->pushdown<compress>())p=p->son[0];
p->splay<compress>();
return p;
}
inline const void link(tree *p,tree *q){
access(p);evert(q);p->set(q,1);p->pushup<compress>();
}
inline tree *cut(tree *p){
access(p);
tree *fa(p->son[0]);
for (;fa->son[1]!=null;fa=fa->son[1])fa->pushdown<compress>();
p->son[0]=p->son[0]->fa=null;
p->pushup<compress>();
return fa;
}
inline const void cover(tree *p,const int &v){
access(p);
p->son[2]->subtree_cover(v);
p->val=v;p->pushup<compress>();
}
inline const void makeroot(tree *p){
evert(root=p);
}
inline const void cover(tree *p,tree *q,const int &v){
expose(p,q);q->path_cover(v);evert(root);
}
void check(tree *p,bool f){
if (p==null)return;
if (f)p->pushdown<rake>();else p->pushdown<compress>();
check(p->son[0],f);
check(p->son[1],f);
check(p->son[2],f^1);
if (f)p->pushup<rake>();else p->pushup<compress>();
//printf("id:%d val:%I64d path_min:%I64d subtree_min:%I64d path_add:%I64d subtree_add:%I64d path_cov:%I64d subtree_cov:%I64d son0:%d son1:%d son2:%d fa:%d\n",p-node0,p->val,p->path_min,p->subtree_min,p->path_add,p->subtree_add,p->path_cov,p->subtree_cov,p->son[0]-node0,p->son[1]-node0,p->son[2]-node0,p->fa-node0);
}
inline const int query_min(tree *p){
access(p);
if (cnt==25707)check(p->son[2],1);
if (cnt==3501||cnt==18259||cnt==24529||cnt==42618||cnt==46769)check(p->son[2],1);
return min(p->val,p->son[2]->subtree_min);
}
inline const int query_max(tree *p){
access(p);
if (cnt==11366||cnt==15122||cnt==21077||cnt==34272||cnt==44637||cnt==49272)check(p->son[2],1);
return max(p->val,p->son[2]->subtree_max);
}
inline const void add(tree *p,const int &v){
access(p);
p->son[2]->subtree_plus(v);
p->val+=v;p->pushup<compress>();
}
inline const int query_min(tree *p,tree *q){
expose(p,q);
const int mn(q->path_min);
evert(root);
return mn;
}
inline const int query_max(tree *p,tree *q){
expose(p,q);
const int mx(q->path_max);
evert(root);
return mx;
}
inline const void add(tree *p,tree *q,const int &v){
expose(p,q);q->path_plus(v);evert(root);
}
inline const void changefa(tree *p,tree *q){
if (p==q||p==root)return;
tree *fa(cut(p));
if (findroot(p)==findroot(q))link(p,fa);
else link(p,q);
evert(root);
}
inline const int query_sum(tree *p,tree *q){
expose(p,q);
const int sum(q->path_sum);
evert(root);
return sum;
}
inline const int query_sum(tree *p){
access(p);return p->son[2]->subtree_sum+p->val;
}
}using namespace Self_Adjusting_Top_Trees;
int n,m,x[N],y[N];
signed main(){
read(n);read(m);
node0=new tree[n+1];
for (int i(1);i<n;i++)read(x[i]),read(y[i]);
for (int i(1);i<=n;i++)read(node(i)->val),node(i)->pushup<compress>();
for (int i(1);i<n;i++)link(node(x[i]),node(y[i]));
int rt;read(rt);makeroot(node(rt));
for (int opt,u,v,w;m--;){
read(opt),read(u);
cnt+=opt==3||opt==4||opt==7||opt==8||opt==10||opt==11;
switch (opt){
case 0:read(w);cover(node(u),w);break;
case 1:makeroot(node(u));break;
case 2:read(v);read(w);cover(node(u),node(v),w);break;
case 3:printf("%d\n",query_min(node(u)));break;
case 4:printf("%d\n",query_max(node(u)));break;
case 5:read(w);add(node(u),w);break;
case 6:read(v);read(w);add(node(u),node(v),w);break;
case 7:read(v);printf("%d\n",query_min(node(u),node(v)));break;
case 8:read(v);printf("%d\n",query_max(node(u),node(v)));break;
case 9:read(v);changefa(node(u),node(v));break;
case 10:read(v);printf("%d\n",query_sum(node(u),node(v)));break;
case 11:printf("%d\n",query_sum(node(u)));break;
}
}
return 0;
}虚树
const int N = 1e5+10;
int dfin[N];
int dfou[N];
int dfn = 0;
int pot[N*2];
int fl[N];
map<int,vector<int>> mp;
bool cmp(int x,int y){
int a = x > 0?dfin[x]:dfou[-x];
int b = y > 0?dfin[y]:dfou[-y];
return a < b;
}
struct HLD {
int n, idx;
vector<vector<int>> ver;
vector<int> siz, dep;
vector<int> top, son, parent;
void dfs1(int x) {
siz[x] = 1;
dep[x] = dep[parent[x]] + 1;
dfin[x] = ++dfn; // !!!!!!!!!!!!!!!
for (auto y : ver[x]) {
if (y == parent[x]) continue;
parent[y] = x;
dfs1(y);
siz[x] += siz[y];
if (siz[y] > siz[son[x]]) {
son[x] = y;
}
}
dfou[x] = ++dfn; // !!!!!!!!!!!!!!
}
vector<int> init_root(int root = 1) { // 在此初始化根节点
dfs1(root);
dfs2(root, root);
return dep; // !!!!!!
}
}; // 其余的初始化构造器,dfs2照抄HLD
void solve(){
int n;cin>>n;
HLD ans(n+1);
for(int i = 1;i<=n;i++){
int x;cin>>x;
mp[x].push_back(i);
}
for(int i = 1;i<n;i++){
int x,y;cin>>x>>y;
ans.addEdge(x,y);
}
vector<int> dep = ans.init_root();
int tot = 0;
for(auto [a,b]:mp){
int pos = 0;
for(auto x:b) {
pot[++pos] = x;
fl[x] = 1;
}
sort(pot+1,pot+1+pos,cmp);
int g = pos;
for(int i = 1;i<g;i++) {
int lca = ans.lca(pot[i],pot[i+1]);
if(!fl[lca])pot[++pos] = lca;
fl[lca] = 1;
}
g = pos;
for(int i = 1;i<=g;i++)pot[++pos] = -pot[i];
sort(pot+1,pot+1+pos,cmp);
stack<int> s;
for(int i = 1;i<=pos;i++){
if(pot[i] > 0) {
s.push(pot[i]);
fl[pot[i]] = 0;
}
else{
int x = s.top();s.pop();
if(s.empty())break;
int fa = s.top();
tot += dep[x]-dep[fa];
}
}
tot++;
}
cout<<tot<<endl;
}小波矩阵树:高效静态区间第 K 大查询
手写 bitset 压位,以 的时间复杂度和 的空间建树后,实现单次 复杂度的区间第 大值询问。已经过偏移,请使用 。
#define __count(x) __builtin_popcountll(x)
struct Wavelet {
vector<int> val, sum;
vector<u64> bit;
int t, n;
int getSum(int i) {
return sum[i >> 6] + __count(bit[i >> 6] & ((1ULL << (i & 63)) - 1));
}
Wavelet(vector<int> v) : val(v), n(v.size()) {
sort(val.begin(), val.end());
val.erase(unique(val.begin(), val.end()), val.end());
int n_ = val.size();
t = __lg(2 * n_ - 1);
bit.resize((t * n + 64) >> 6);
sum.resize(bit.size());
vector<int> cnt(n_ + 1);
for (int &x : v) {
x = lower_bound(val.begin(), val.end(), x) - val.begin();
cnt[x + 1]++;
}
for (int i = 1; i < n_; ++i) {
cnt[i] += cnt[i - 1];
}
for (int j = 0; j < t; ++j) {
for (int i : v) {
int tmp = i >> (t - 1 - j);
int pos = (tmp >> 1) << (t - j);
auto setBit = [&](int i, u64 v) {
bit[i >> 6] |= (v << (i & 63));
};
setBit(j * n + cnt[pos], tmp & 1);
cnt[pos]++;
}
for (int i : v) {
cnt[(i >> (t - j)) << (t - j)]--;
}
}
for (int i = 1; i < sum.size(); ++i) {
sum[i] = sum[i - 1] + __count(bit[i - 1]);
}
}
int small(int l, int r, int k) {
r++, k--;
for (int j = 0, x = 0, y = n, res = 0;; ++j) {
if (j == t) return val[res];
int A = getSum(n * j + x), B = getSum(n * j + l);
int C = getSum(n * j + r), D = getSum(n * j + y);
int ab_zeros = r - l - C + B;
if (ab_zeros > k) {
res = res << 1;
y -= D - A;
l -= B - A;
r -= C - A;
} else {
res = (res << 1) | 1;
k -= ab_zeros;
x += y - x - D + A;
l += y - l - D + B;
r += y - r - D + C;
}
}
}
int large(int l, int r, int k) {
return small(l, r, r - l - k);
}
};普通莫队
以 的复杂度完成 次询问的离线查询,其中每个分块的大小取 ,也可以使用 n / min<int>(n, sqrt(q)) 、 ceil((double)n / (int)sqrt(n)) 或者 sqrt(n) 划分。
signed main() {
int n;
cin >> n;
vector<int> w(n + 1);
for (int i = 1; i <= n; i++) {
cin >> w[i];
}
int q;
cin >> q;
vector<array<int, 3>> query(q + 1);
for (int i = 1; i <= q; i++) {
int l, r;
cin >> l >> r;
query[i] = {l, r, i};
}
int Knum = n / min<int>(n, sqrt(q)); // 计算块长
vector<int> K(n + 1);
for (int i = 1; i <= n; i++) { // 固定块长
K[i] = (i - 1) / Knum + 1;
}
sort(query.begin() + 1, query.end(), [&](auto x, auto y) {
if (K[x[0]] != K[y[0]]) return x[0] < y[0];
if (K[x[0]] & 1) return x[1] < y[1];
return x[1] > y[1];
});
int l = 1, r = 0, val = 0;
vector<int> ans(q + 1);
for (int i = 1; i <= q; i++) {
auto [ql, qr, id] = query[i];
auto add = [&](int x) -> void {};
auto del = [&](int x) -> void {};
while (l > ql) add(w[--l]);
while (r < qr) add(w[++r]);
while (l < ql) del(w[l++]);
while (r > qr) del(w[r--]);
ans[id] = val;
}
for (int i = 1; i <= q; i++) {
cout << ans[i] << endl;
}
}需要注意的是,在普通莫队中,K 数组的作用是根据左边界的值进行排序,当询问次数很少时(),可以直接合并到 query 数组中。
vector<array<int, 4>> query(q);
for (int i = 1; i <= q; i++) {
int l, r;
cin >> l >> r;
query[i] = {l, r, i, (l - 1) / Knum + 1}; // 合并
}
sort(query.begin() + 1, query.end(), [&](auto x, auto y) {
if (x[3] != y[3]) return x[3] < y[3];
if (x[3] & 1) return x[1] < y[1];
return x[1] > y[1];
});分数运算类
定义了分数的四则运算,如果需要处理浮点数,那么需要将函数中的 gcd 运算替换为 fgcd 。
template<class T> struct Frac {
T x, y;
Frac() : Frac(0, 1) {}
Frac(T x_) : Frac(x_, 1) {}
Frac(T x_, T y_) : x(x_), y(y_) {
if (y < 0) {
y = -y;
x = -x;
}
}
constexpr double val() const {
return 1. * x / y;
}
constexpr Frac norm() const { // 调整符号、转化为最简形式
T p = gcd(x, y);
return {x / p, y / p};
}
friend constexpr auto &operator<<(ostream &o, const Frac &j) {
T p = gcd(j.x, j.y);
if (j.y == p) {
return o << j.x / p;
} else {
return o << j.x / p << "/" << j.y / p;
}
}
constexpr Frac &operator/=(const Frac &i) {
x *= i.y;
y *= i.x;
if (y < 0) {
x = -x;
y = -y;
}
return *this;
}
constexpr Frac &operator+=(const Frac &i) { return x = x * i.y + y * i.x, y *= i.y, *this; }
constexpr Frac &operator-=(const Frac &i) { return x = x * i.y - y * i.x, y *= i.y, *this; }
constexpr Frac &operator*=(const Frac &i) { return x *= i.x, y *= i.y, *this; }
friend constexpr Frac operator+(const Frac i, const Frac j) { return i += j; }
friend constexpr Frac operator-(const Frac i, const Frac j) { return i -= j; }
friend constexpr Frac operator*(const Frac i, const Frac j) { return i *= j; }
friend constexpr Frac operator/(const Frac i, const Frac j) { return i /= j; }
friend constexpr Frac operator-(const Frac i) { return Frac(-i.x, i.y); }
friend constexpr bool operator<(const Frac i, const Frac j) { return i.x * j.y < i.y * j.x; }
friend constexpr bool operator>(const Frac i, const Frac j) { return i.x * j.y > i.y * j.x; }
friend constexpr bool operator==(const Frac i, const Frac j) { return i.x * j.y == i.y * j.x; }
friend constexpr bool operator!=(const Frac i, const Frac j) { return i.x * j.y != i.y * j.x; }
};主席树(可持久化线段树)
以 的时间复杂度建树、查询、修改。
struct PresidentTree {
struct node {
int l, r;
int cnt;
};
int cntNodes{}, n{};
vector<int> root;
vector<node> tr;
PresidentTree(int n) {
cntNodes = 0;
this->n = n;
root.resize(n << 7 | 1, 0);
tr.resize(n << 7 | 1);
build(root[0], 1, n);
}
void build(int &u, int l, int r) { //建空树
u = ++cntNodes; //动态开点
if (l == r) return;
int mid = (l + r) >> 1;
build(tr[u].l, l, mid);
build(tr[u].r, mid + 1, r);
}
void modify(int &u, int v, int l, int r, int x) {
u = ++cntNodes;
tr[u] = tr[v];
tr[u].cnt++;
if (l == r) return;
int mid = (l + r) / 2;
if (x <= mid) modify(tr[u].l, tr[v].l, l, mid, x);
else modify(tr[u].r, tr[v].r, mid + 1, r, x);
}
void modify(int cur, int pre, int x) {
modify(root[cur], root[pre], 1, n, x);
}
int kth(int u, int v, int l, int r, int k) {
if (l == r) return l;
int res = tr[tr[v].l].cnt - tr[tr[u].l].cnt;
int mid = (l + r) / 2;
if (k <= res) return kth(tr[u].l, tr[v].l, l, mid, k);
else return kth(tr[u].r, tr[v].r, mid + 1, r, k - res);
}
int kth(int l, int r, int k) { // [l,r]第k大
if (l > r)return 0;
return kth(root[l - 1], root[r], 1, n, k);
}
int ask(int u, int v, int l, int r, int k) {
if (l == r) return tr[v].cnt - tr[u].cnt;
int mid = (l + r) / 2;
int ans = 0;
if (k <= mid) ans += ask(tr[u].l, tr[v].l, l, mid, k);
else {
ans += tr[tr[v].l].cnt - tr[tr[u].l].cnt;
ans += ask(tr[u].r, tr[v].r, mid + 1, r, k);
}
return ans;
}
int ask(int l, int r, int k) { //[l,r]大于等于k的个数
if (l > r)return 0;
return ask(root[l - 1], root[r], 1, n, k);
}
};KD Tree
在第 维上的单次查询复杂度最坏为 。
struct KDT {
constexpr static int N = 1e5 + 10, K = 2;
double alpha = 0.725;
struct node {
int info[K];
int mn[K], mx[K];
} tr[N];
int ls[N], rs[N], siz[N], id[N], d[N];
int idx, rt, cur;
int ans;
KDT() {
rt = 0;
cur = 0;
memset(ls, 0, sizeof ls);
memset(rs, 0, sizeof rs);
memset(d, 0, sizeof d);
}
void apply(int p, int son) {
if (son) {
for (int i = 0; i < K; i++) {
tr[p].mn[i] = min(tr[p].mn[i], tr[son].mn[i]);
tr[p].mx[i] = max(tr[p].mx[i], tr[son].mx[i]);
}
siz[p] += siz[son];
}
}
void maintain(int p) {
for (int i = 0; i < K; i++) {
tr[p].mn[i] = tr[p].info[i];
tr[p].mx[i] = tr[p].info[i];
}
siz[p] = 1;
apply(p, ls[p]);
apply(p, rs[p]);
}
int build(int l, int r) {
if (l > r) return 0;
vector<double> avg(K);
for (int i = 0; i < K; i++) {
for (int j = l; j <= r; j++) {
avg[i] += tr[id[j]].info[i];
}
avg[i] /= (r - l + 1);
}
vector<double> var(K);
for (int i = 0; i < K; i++) {
for (int j = l; j <= r; j++) {
var[i] += (tr[id[j]].info[i] - avg[i]) * (tr[id[j]].info[i] - avg[i]);
}
}
int mid = (l + r) / 2;
int x = max_element(var.begin(), var.end()) - var.begin();
nth_element(id + l, id + mid, id + r + 1, [&](int a, int b) {
return tr[a].info[x] < tr[b].info[x];
});
d[id[mid]] = x;
ls[id[mid]] = build(l, mid - 1);
rs[id[mid]] = build(mid + 1, r);
maintain(id[mid]);
return id[mid];
}
void print(int p) {
if (!p) return;
print(ls[p]);
id[++idx] = p;
print(rs[p]);
}
void rebuild(int &p) {
idx = 0;
print(p);
p = build(1, idx);
}
bool bad(int p) {
return alpha * siz[p] <= max(siz[ls[p]], siz[rs[p]]);
}
void insert(int &p, int cur) {
if (!p) {
p = cur;
maintain(p);
return;
}
if (tr[p].info[d[p]] > tr[cur].info[d[p]]) insert(ls[p], cur);
else insert(rs[p], cur);
maintain(p);
if (bad(p)) rebuild(p);
}
void insert(vector<int> &a) {
cur++;
for (int i = 0; i < K; i++) {
tr[cur].info[i] = a[i];
}
insert(rt, cur);
}
bool out(int p, vector<int> &a) {
for (int i = 0; i < K; i++) {
if (a[i] < tr[p].mn[i]) {
return true;
}
}
return false;
}
bool in(int p, vector<int> &a) {
for (int i = 0; i < K; i++) {
if (a[i] < tr[p].info[i]) {
return false;
}
}
return true;
}
bool all(int p, vector<int> &a) {
for (int i = 0; i < K; i++) {
if (a[i] < tr[p].mx[i]) {
return false;
}
}
return true;
}
void query(int p, vector<int> &a) {
if (!p) return;
if (out(p, a)) return;
if (all(p, a)) {
ans += siz[p];
return;
}
if (in(p, a)) ans++;
query(ls[p], a);
query(rs[p], a);
}
int query(vector<int> &a) {
ans = 0;
query(rt, a);
return ans;
}
};ST 表
用于解决区间可重复贡献问题,需要满足 (如区间最大值: 、区间 : 等),但是不支持修改操作。 预处理, 查询。
struct ST {
const int n, k;
vector<int> in1, in2;
vector<vector<int>> Max, Min;
ST(int n) : n(n), in1(n + 1), in2(n + 1), k(__lg(n)) {
Max.resize(k + 1, vector<int>(n + 1));
Min.resize(k + 1, vector<int>(n + 1));
}
void init() {
for (int i = 1; i <= n; i++) {
Max[0][i] = in1[i];
Min[0][i] = in2[i];
}
for (int i = 0, t = 1; i < k; i++, t <<= 1) {
const int T = n - (t << 1) + 1;
for (int j = 1; j <= T; j++) {
Max[i + 1][j] = max(Max[i][j], Max[i][j + t]);
Min[i + 1][j] = min(Min[i][j], Min[i][j + t]);
}
}
}
int getMax(int l, int r) {
if (l > r) {
swap(l, r);
}
int k = __lg(r - l + 1);
return max(Max[k][l], Max[k][r - (1 << k) + 1]);
}
int getMin(int l, int r) {
if (l > r) {
swap(l, r);
}
int k = __lg(r - l + 1);
return min(Min[k][l], Min[k][r - (1 << k) + 1]);
}
};基于状压的线性 RMQ 算法
严格 预处理, 查询。
template<class T, class Cmp = less<T>> struct RMQ {
const Cmp cmp = Cmp();
static constexpr unsigned B = 64;
using u64 = unsigned long long;
int n;
vector<vector<T>> a;
vector<T> pre, suf, ini;
vector<u64> stk;
RMQ() {}
RMQ(const vector<T> &v) {
init(v);
}
void init(const vector<T> &v) {
n = v.size();
pre = suf = ini = v;
stk.resize(n);
if (!n) {
return;
}
const int M = (n - 1) / B + 1;
const int lg = __lg(M);
a.assign(lg + 1, vector<T>(M));
for (int i = 0; i < M; i++) {
a[0][i] = v[i * B];
for (int j = 1; j < B && i * B + j < n; j++) {
a[0][i] = min(a[0][i], v[i * B + j], cmp);
}
}
for (int i = 1; i < n; i++) {
if (i % B) {
pre[i] = min(pre[i], pre[i - 1], cmp);
}
}
for (int i = n - 2; i >= 0; i--) {
if (i % B != B - 1) {
suf[i] = min(suf[i], suf[i + 1], cmp);
}
}
for (int j = 0; j < lg; j++) {
for (int i = 0; i + (2 << j) <= M; i++) {
a[j + 1][i] = min(a[j][i], a[j][i + (1 << j)], cmp);
}
}
for (int i = 0; i < M; i++) {
const int l = i * B;
const int r = min(1U * n, l + B);
u64 s = 0;
for (int j = l; j < r; j++) {
while (s && cmp(v[j], v[__lg(s) + l])) {
s ^= 1ULL << __lg(s);
}
s |= 1ULL << (j - l);
stk[j] = s;
}
}
}
T operator()(int l, int r) {
if (l / B != (r - 1) / B) {
T ans = min(suf[l], pre[r - 1], cmp);
l = l / B + 1;
r = r / B;
if (l < r) {
int k = __lg(r - l);
ans = min({ans, a[k][l], a[k][r - (1 << k)]}, cmp);
}
return ans;
} else {
int x = B * (l / B);
return ini[__builtin_ctzll(stk[r - 1] >> (l - x)) + l];
}
}
};pbds 扩展库实现平衡二叉树
记得加上相应的头文件,同时需要注意定义时的参数,一般只需要修改第三个参数:即定义的是大根堆还是小根堆。
附常见成员函数:
empty() / size() insert(x) // 插入元素x erase(x) // 删除元素/迭代器x order_of_key(x) // 返回元素x的排名 find_by_order(x) // 返回排名为x的元素迭代器 lower_bound(x) / upper_bound(x) // 返回迭代器 join(Tree) // 将Tree树的全部元素并入当前的树 split(x, Tree) // 将大于x的元素放入Tree树
#include <ext/pb_ds/assoc_container.hpp>
using namespace __gnu_pbds;
using V = pair<int, int>;
tree<V, null_type, less<V>, rb_tree_tag, tree_order_statistics_node_update> ver;
map<int, int> dic;
int n; cin >> n;
for (int i = 1, op, x; i <= n; i++) {
cin >> op >> x;
if (op == 1) { // 插入一个元素x,允许重复
ver.insert({x, ++dic[x]});
} else if (op == 2) { // 删除元素x,若有重复,则任意删除一个
ver.erase({x, dic[x]--});
} else if (op == 3) { // 查询元素x的排名(排名定义为比当前数小的数的个数+1)
cout << ver.order_of_key({x, 1}) + 1 << endl;
} else if (op == 4) { // 查询排名为x的元素
cout << ver.find_by_order(--x)->first << endl;
} else if (op == 5) { // 查询元素x的前驱
int idx = ver.order_of_key({x, 1}) - 1; // 无论x存不存在,idx都代表x的位置,需要-1
cout << ver.find_by_order(idx)->first << endl;
} else if (op == 6) { // 查询元素x的后继
int idx = ver.order_of_key( {x, dic[x]}); // 如果x不存在,那么idx就是x的后继
if (ver.find({x, 1}) != ver.end()) idx++; // 如果x存在,那么idx是x的位置,需要+1
cout << ver.find_by_order(idx)->first << endl;
}
}pbds食用手册
#include<ext/pb_ds/assoc_container.hpp>
#include<ext/pb_ds/tree_policy.hpp>
using namespace __gnu_pbds; //把这一整段放置上方
tree<int, null_type, less<int>, rb_tree_tag, tree_order_statistics_node_update> bbt;
bbt.insert((k << 20) + i); // 向树中插入k 因为树中value不能重复 所以进行位运算+i当作另一个键值
bbt.erase(bbt.lower_bound(k << 20)); // 假设树中存在多个k 则删除掉一个k 注意如果没有k的话 会删除第一个比k大的数字
printf("%d\n", bbt.order_of_key(k << 20) + 1); // 查询 k数字 位于第几位
ans = *bbt.find_by_order(k - 1), printf("%lld\n", ans >> 20); // 查询位于 第x位 的数字
ans = *--bbt.lower_bound(k << 20), printf("%lld\n", ans >> 20); // 查询小于 k 且最大的数字
ans = *bbt.upper_bound((k << 20) + n), printf("%lld\n", ans >> 20); // 查询大于 k 且最小的数字vector 模拟实现平衡二叉树
#define ALL(x) x.begin(), x.end()
#define pre lower_bound
#define suf upper_bound
int n; cin >> n;
vector<int> ver;
for (int i = 1, op, x; i <= n; i++) {
cin >> op >> x;
if (op == 1) ver.insert(pre(ALL(ver), x), x);
if (op == 2) ver.erase(pre(ALL(ver), x));
if (op == 3) cout << pre(ALL(ver), x) - ver.begin() + 1 << endl;
if (op == 4) cout << ver[x - 1] << endl;
if (op == 5) cout << ver[pre(ALL(ver), x) - ver.begin() - 1] << endl;
if (op == 6) cout << ver[suf(ALL(ver), x) - ver.begin()] << endl;
}线性基
struct linear_basis {
int Base[63]{}, n{};
int simple_base[63]{};
bool check(int val) { // 判断 val 是否能被异或得到
for (int i = 62; i >= 0; i--) {
if (val & (1ll << i)) {
if (!Base[i]) return false;
val ^= Base[i];
}
}
return true;
}
int get_max() {
int res = 0;
for (int i = 62; i >= 0; --i) res = max(res, res ^ Base[i]);
return res;
}
int get_min() {
int cnt = 0;
int res = inf;
for (int i = 62; i >= 0; --i) if (Base[i]) ++cnt, res = Base[i];
if (cnt < n) return 0;
else return res;
// cnt 为线性基的个数 n为插入的元素个数
}
int getKth(int k) { //第k小
int res = 0, cnt = 0;
for (const int &i: Base) if (i) simple_base[cnt++] = i;
if (n != cnt) --k;
if (k >= (1LL << cnt)) return -1;
for (int i = 0; i < cnt; ++i)
if (k >> i & 1) res ^= simple_base[i];
return res;
}
void operator+=(int x) {
++n;
for (int i = 62; i >= 0; --i) {
if (!(x & (1LL << i)))continue;
if (Base[i])x ^= Base[i];
else {
Base[i] = x;
break;
}
}
}
int &operator[](int x) {
return Base[x];
}
friend linear_basis operator+(linear_basis &x, linear_basis &y) {
linear_basis z = x;
for (int i = 62; i >= 0; --i)if (y[i]) z += y[i];
z.n = x.n + y.n;
return z;
}
};带删堆
template<typename T> struct heap//大根堆
{
priority_queue<T> p,q;
void push(const T &x)
{
if (!q.empty()&&q.top()==x)
{
q.pop();
while (!q.empty()&&q.top()==p.top()) p.pop(),q.pop();
} else p.push(x);
}
void pop()
{
p.pop();
while (!q.empty()&&p.top()==q.top()) p.pop(),q.pop();
}
void pop(const T &x)
{
if (p.top()==x)
{
p.pop();
while (!q.empty()&&p.top()==q.top()) p.pop(),q.pop();
} else q.push(x);
}
T top() {return p.top();}
bool empty() {return p.empty();}
};维护中位数
template<class T>
struct Mid {
priority_queue<T> a;
priority_queue<T, vector<T>, greater<T>> b;
void add(T x) {
if (a.empty())a.emplace(x);
else {
T mid = a.top();
if (x >= mid)b.emplace(x);
else a.emplace(x);
balance();
}
}
void balance() {
int deta = a.size() - b.size();
if (deta > 1) {
auto it = a.top();
a.pop();
b.emplace(it);
}
if (deta < 0) {
auto it = b.top();
b.pop();
a.emplace(it);
}
}
T ask() {
return a.top();
}
};求n条直线在同一个x下的最小值和最大值
struct Line {
mutable int k, m, p;
bool operator<(const Line &o) const { return k < o.k; }
bool operator<(int x) const { return p < x; }
};
struct LineContainer : multiset<Line, less<>> { // 求MAX
// (for doubles, use inf = 1/.0, div(a,b) = a/b)
static const int inf = LLONG_MAX;
int div(int a, int b) { // floored division
return a / b - ((a ^ b) < 0 && a % b);
}
bool isect(iterator x, iterator y) {
if (y == end()) return x->p = inf, 0;
if (x->k == y->k) x->p = x->m > y->m ? inf : -inf;
else x->p = div(y->m - x->m, x->k - y->k);
return x->p >= y->p;
}
void add(int k, int m) {
auto z = insert({k, m, 0}), y = z++, x = y;
while (isect(y, z)) z = erase(z);
if (x != begin() && isect(--x, y)) isect(x, y = erase(y));
while ((y = x) != begin() && (--x)->p >= y->p)
isect(x, erase(y));
}
int query(int x) {
assert(!empty());
auto l = *lower_bound(x);
return l.k * x + l.m;
}
};
struct LineContainerMIN : multiset<Line, less<>> { // 求MIN
// (for doubles, use inf = 1/.0, div(a,b) = a/b)
static const int inf = LLONG_MAX;
int div(int a, int b) { // floored division
return a / b - ((a ^ b) < 0 && a % b);
}
bool isect(iterator x, iterator y) {
if (y == end()) return x->p = inf, 0;
if (x->k == y->k) x->p = x->m > y->m ? inf : -inf;
else x->p = div(y->m - x->m, x->k - y->k);
return x->p >= y->p;
}
void add(int k, int m) {
k *= -1;
m *= -1;
auto z = insert({k, m, 0}), y = z++, x = y;
while (isect(y, z)) z = erase(z);
if (x != begin() && isect(--x, y)) isect(x, y = erase(y));
while ((y = x) != begin() && (--x)->p >= y->p)
isect(x, erase(y));
}
int query(int x) {
assert(!empty());
auto l = *lower_bound(x);
return -(l.k * x + l.m);
}
};珂朵莉树 (OD Tree)
区间赋值的数据结构都可以骗分,在数据随机的情况下,复杂度可以保证,时间复杂度: 。
struct ODT {
struct node {
int l, r;
mutable LL v;
node(int l, int r = -1, LL v = 0) : l(l), r(r), v(v) {}
bool operator<(const node &o) const {
return l < o.l;
}
};
set<node> s;
ODT() {
s.clear();
}
auto split(int pos) {
auto it = s.lower_bound(node(pos));
if (it != s.end() && it->l == pos) return it;
it--;
int l = it->l, r = it->r;
LL v = it->v;
s.erase(it);
s.insert(node(l, pos - 1, v));
return s.insert(node(pos, r, v)).first;
}
void assign(int l, int r, LL x) {
auto itr = split(r + 1), itl = split(l);
s.erase(itl, itr);
s.insert(node(l, r, x));
}
void add(int l, int r, LL x) {
auto itr = split(r + 1), itl = split(l);
for (auto it = itl; it != itr; it++) {
it->v += x;
}
}
LL kth(int l, int r, int k) {
vector<pair<LL, int>> a;
auto itr = split(r + 1), itl = split(l);
for (auto it = itl; it != itr; it++) {
a.push_back(pair<LL, int>(it->v, it->r - it->l + 1));
}
sort(a.begin(), a.end());
for (auto [val, len] : a) {
k -= len;
if (k <= 0) return val;
}
}
LL power(LL a, int b, int mod) {
a %= mod;
LL res = 1;
for (; b; b /= 2, a = a * a % mod) {
if (b % 2) {
res = res * a % mod;
}
}
return res;
}
LL powersum(int l, int r, int x, int mod) {
auto itr = split(r + 1), itl = split(l);
LL ans = 0;
for (auto it = itl; it != itr; it++) {
ans = (ans + power(it->v, x, mod) * (it->r - it->l + 1) % mod) % mod;
}
return ans;
}
};取模运算类
集成了常见的取模四则运算,运算速度与手动取模相差无几,效率极高。
using i64 = long long;
template<class T> constexpr T mypow(T n, i64 k) {
T r = 1;
for (; k; k /= 2, n *= n) {
if (k % 2) {
r *= n;
}
}
return r;
}
template<class T> constexpr T power(int n) {
return mypow(T(2), n);
}
template<const int &MOD> struct Zmod {
int x;
Zmod(signed x = 0) : x(norm(x % MOD)) {}
Zmod(i64 x) : x(norm(x % MOD)) {}
constexpr int norm(int x) const noexcept {
if (x < 0) [[unlikely]] {
x += MOD;
}
if (x >= MOD) [[unlikely]] {
x -= MOD;
}
return x;
}
explicit operator int() const {
return x;
}
constexpr int val() const {
return x;
}
constexpr Zmod operator-() const {
Zmod val = norm(MOD - x);
return val;
}
constexpr Zmod inv() const {
assert(x != 0);
return mypow(*this, MOD - 2);
}
friend constexpr auto &operator>>(istream &in, Zmod &j) {
int v;
in >> v;
j = Zmod(v);
return in;
}
friend constexpr auto &operator<<(ostream &o, const Zmod &j) {
return o << j.val();
}
constexpr Zmod &operator++() {
x = norm(x + 1);
return *this;
}
constexpr Zmod &operator--() {
x = norm(x - 1);
return *this;
}
constexpr Zmod operator++(signed) {
Zmod res = *this;
++*this;
return res;
}
constexpr Zmod operator--(signed) {
Zmod res = *this;
--*this;
return res;
}
constexpr Zmod &operator+=(const Zmod &i) {
x = norm(x + i.x);
return *this;
}
constexpr Zmod &operator-=(const Zmod &i) {
x = norm(x - i.x);
return *this;
}
constexpr Zmod &operator*=(const Zmod &i) {
x = i64(x) * i.x % MOD;
return *this;
}
constexpr Zmod &operator/=(const Zmod &i) {
return *this *= i.inv();
}
constexpr Zmod &operator%=(const int &i) {
return x %= i, *this;
}
friend constexpr Zmod operator+(const Zmod i, const Zmod j) {
return Zmod(i) += j;
}
friend constexpr Zmod operator-(const Zmod i, const Zmod j) {
return Zmod(i) -= j;
}
friend constexpr Zmod operator*(const Zmod i, const Zmod j) {
return Zmod(i) *= j;
}
friend constexpr Zmod operator/(const Zmod i, const Zmod j) {
return Zmod(i) /= j;
}
friend constexpr Zmod operator%(const Zmod i, const int j) {
return Zmod(i) %= j;
}
friend constexpr bool operator==(const Zmod i, const Zmod j) {
return i.val() == j.val();
}
friend constexpr bool operator!=(const Zmod i, const Zmod j) {
return i.val() != j.val();
}
friend constexpr bool operator<(const Zmod i, const Zmod j) {
return i.val() < j.val();
}
friend constexpr bool operator>(const Zmod i, const Zmod j) {
return i.val() > j.val();
}
};
const int MOD = ...;
using Z = Zmod<MOD>;大整数类(高精度计算)
const int base = 1000000000;
const int base_digits = 9; // 分解为九个数位一个数字
struct bigint {
vector<int> a;
int sign;
bigint() : sign(1) {}
bigint operator-() const {
bigint res = *this;
res.sign = -sign;
return res;
}
bigint(long long v) {
*this = v;
}
bigint(const string &s) {
read(s);
}
void operator=(const bigint &v) {
sign = v.sign;
a = v.a;
}
void operator=(long long v) {
a.clear();
sign = 1;
if (v < 0) sign = -1, v = -v;
for (; v > 0; v = v / base) {
a.push_back(v % base);
}
}
// 基础加减乘除
bigint operator+(const bigint &v) const {
if (sign == v.sign) {
bigint res = v;
for (int i = 0, carry = 0; i < (int)max(a.size(), v.a.size()) || carry; ++i) {
if (i == (int)res.a.size()) {
res.a.push_back(0);
}
res.a[i] += carry + (i < (int)a.size() ? a[i] : 0);
carry = res.a[i] >= base;
if (carry) {
res.a[i] -= base;
}
}
return res;
}
return *this - (-v);
}
bigint operator-(const bigint &v) const {
if (sign == v.sign) {
if (abs() >= v.abs()) {
bigint res = *this;
for (int i = 0, carry = 0; i < (int)v.a.size() || carry; ++i) {
res.a[i] -= carry + (i < (int)v.a.size() ? v.a[i] : 0);
carry = res.a[i] < 0;
if (carry) {
res.a[i] += base;
}
}
res.trim();
return res;
}
return -(v - *this);
}
return *this + (-v);
}
void operator*=(int v) {
check(v);
for (int i = 0, carry = 0; i < (int)a.size() || carry; ++i) {
if (i == (int)a.size()) {
a.push_back(0);
}
long long cur = a[i] * (long long)v + carry;
carry = (int)(cur / base);
a[i] = (int)(cur % base);
}
trim();
}
void operator/=(int v) {
check(v);
for (int i = (int)a.size() - 1, rem = 0; i >= 0; --i) {
long long cur = a[i] + rem * (long long)base;
a[i] = (int)(cur / v);
rem = (int)(cur % v);
}
trim();
}
int operator%(int v) const {
if (v < 0) {
v = -v;
}
int m = 0;
for (int i = a.size() - 1; i >= 0; --i) {
m = (a[i] + m * (long long)base) % v;
}
return m * sign;
}
void operator+=(const bigint &v) {
*this = *this + v;
}
void operator-=(const bigint &v) {
*this = *this - v;
}
bigint operator*(int v) const {
bigint res = *this;
res *= v;
return res;
}
bigint operator/(int v) const {
bigint res = *this;
res /= v;
return res;
}
void operator%=(const int &v) {
*this = *this % v;
}
bool operator<(const bigint &v) const {
if (sign != v.sign) return sign < v.sign;
if (a.size() != v.a.size()) return a.size() * sign < v.a.size() * v.sign;
for (int i = a.size() - 1; i >= 0; i--)
if (a[i] != v.a[i]) return a[i] * sign < v.a[i] * sign;
return false;
}
bool operator>(const bigint &v) const {
return v < *this;
}
bool operator<=(const bigint &v) const {
return !(v < *this);
}
bool operator>=(const bigint &v) const {
return !(*this < v);
}
bool operator==(const bigint &v) const {
return !(*this < v) && !(v < *this);
}
bool operator!=(const bigint &v) const {
return *this < v || v < *this;
}
bigint abs() const {
bigint res = *this;
res.sign *= res.sign;
return res;
}
void check(int v) { // 检查输入的是否为负数
if (v < 0) {
sign = -sign;
v = -v;
}
}
void trim() { // 去除前导零
while (!a.empty() && !a.back()) a.pop_back();
if (a.empty()) sign = 1;
}
bool isZero() const { // 判断是否等于零
return a.empty() || (a.size() == 1 && !a[0]);
}
friend bigint gcd(const bigint &a, const bigint &b) {
return b.isZero() ? a : gcd(b, a % b);
}
friend bigint lcm(const bigint &a, const bigint &b) {
return a / gcd(a, b) * b;
}
void read(const string &s) {
sign = 1;
a.clear();
int pos = 0;
while (pos < (int)s.size() && (s[pos] == '-' || s[pos] == '+')) {
if (s[pos] == '-') sign = -sign;
++pos;
}
for (int i = s.size() - 1; i >= pos; i -= base_digits) {
int x = 0;
for (int j = max(pos, i - base_digits + 1); j <= i; j++) x = x * 10 + s[j] - '0';
a.push_back(x);
}
trim();
}
friend istream &operator>>(istream &stream, bigint &v) {
string s;
stream >> s;
v.read(s);
return stream;
}
friend ostream &operator<<(ostream &stream, const bigint &v) {
if (v.sign == -1) stream << '-';
stream << (v.a.empty() ? 0 : v.a.back());
for (int i = (int)v.a.size() - 2; i >= 0; --i)
stream << setw(base_digits) << setfill('0') << v.a[i];
return stream;
}
/* 大整数乘除大整数部分 */
typedef vector<long long> vll;
bigint operator*(const bigint &v) const { // 大整数乘大整数
vector<int> a6 = convert_base(this->a, base_digits, 6);
vector<int> b6 = convert_base(v.a, base_digits, 6);
vll a(a6.begin(), a6.end());
vll b(b6.begin(), b6.end());
while (a.size() < b.size()) a.push_back(0);
while (b.size() < a.size()) b.push_back(0);
while (a.size() & (a.size() - 1)) a.push_back(0), b.push_back(0);
vll c = karatsubaMultiply(a, b);
bigint res;
res.sign = sign * v.sign;
for (int i = 0, carry = 0; i < (int)c.size(); i++) {
long long cur = c[i] + carry;
res.a.push_back((int)(cur % 1000000));
carry = (int)(cur / 1000000);
}
res.a = convert_base(res.a, 6, base_digits);
res.trim();
return res;
}
friend pair<bigint, bigint> divmod(const bigint &a1,
const bigint &b1) { // 大整数除大整数,同时返回答案与余数
int norm = base / (b1.a.back() + 1);
bigint a = a1.abs() * norm;
bigint b = b1.abs() * norm;
bigint q, r;
q.a.resize(a.a.size());
for (int i = a.a.size() - 1; i >= 0; i--) {
r *= base;
r += a.a[i];
int s1 = r.a.size() <= b.a.size() ? 0 : r.a[b.a.size()];
int s2 = r.a.size() <= b.a.size() - 1 ? 0 : r.a[b.a.size() - 1];
int d = ((long long)base * s1 + s2) / b.a.back();
r -= b * d;
while (r < 0) r += b, --d;
q.a[i] = d;
}
q.sign = a1.sign * b1.sign;
r.sign = a1.sign;
q.trim();
r.trim();
return make_pair(q, r / norm);
}
static vector<int> convert_base(const vector<int> &a, int old_digits, int new_digits) {
vector<long long> p(max(old_digits, new_digits) + 1);
p[0] = 1;
for (int i = 1; i < (int)p.size(); i++) p[i] = p[i - 1] * 10;
vector<int> res;
long long cur = 0;
int cur_digits = 0;
for (int i = 0; i < (int)a.size(); i++) {
cur += a[i] * p[cur_digits];
cur_digits += old_digits;
while (cur_digits >= new_digits) {
res.push_back((int)(cur % p[new_digits]));
cur /= p[new_digits];
cur_digits -= new_digits;
}
}
res.push_back((int)cur);
while (!res.empty() && !res.back()) res.pop_back();
return res;
}
static vll karatsubaMultiply(const vll &a, const vll &b) {
int n = a.size();
vll res(n + n);
if (n <= 32) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
res[i + j] += a[i] * b[j];
}
}
return res;
}
int k = n >> 1;
vll a1(a.begin(), a.begin() + k);
vll a2(a.begin() + k, a.end());
vll b1(b.begin(), b.begin() + k);
vll b2(b.begin() + k, b.end());
vll a1b1 = karatsubaMultiply(a1, b1);
vll a2b2 = karatsubaMultiply(a2, b2);
for (int i = 0; i < k; i++) a2[i] += a1[i];
for (int i = 0; i < k; i++) b2[i] += b1[i];
vll r = karatsubaMultiply(a2, b2);
for (int i = 0; i < (int)a1b1.size(); i++) r[i] -= a1b1[i];
for (int i = 0; i < (int)a2b2.size(); i++) r[i] -= a2b2[i];
for (int i = 0; i < (int)r.size(); i++) res[i + k] += r[i];
for (int i = 0; i < (int)a1b1.size(); i++) res[i] += a1b1[i];
for (int i = 0; i < (int)a2b2.size(); i++) res[i + n] += a2b2[i];
return res;
}
void operator*=(const bigint &v) {
*this = *this * v;
}
bigint operator/(const bigint &v) const {
return divmod(*this, v).first;
}
void operator/=(const bigint &v) {
*this = *this / v;
}
bigint operator%(const bigint &v) const {
return divmod(*this, v).second;
}
void operator%=(const bigint &v) {
*this = *this % v;
}
};常见结论
题意:(区间移位问题)要求将整个序列左移/右移若干个位置,例如,原序列为 ,右移 位后变为 。
区间的端点只是一个数字,即使被改变了,通过一定的转换也能够还原,所以我们可以 解决这一问题。为了方便计算,我们规定下标从 开始,即整个线段的区间为 ,随后,使用一个偏移量 shift 记录。使用 shift = (shift + x) % n; 更新偏移量;此后的区间查询/修改前,再将坐标偏移回去即可,下方代码使用区间修改作为示例。
cin >> l >> r >> x;
l--; // 坐标修改为 0 开始
r--;
l = (l + shift) % n; // 偏移
r = (r + shift) % n;
if (l > r) { // 区间分离则分别操作
segt.modify(l, n - 1, x);
segt.modify(0, r, x);
} else {
segt.modify(l, r, x);
}常见例题
题意:(带修莫队 - 维护队列)要求能够处理以下操作:
'Q' l r:询问区间 有几个颜色;'R' idx w:将下标 的颜色修改为 。
输入格式为:第一行 和 分别代表区间长度和操作数量;第二行 个整数 代表初始颜色;随后 行为具体操作。
const int N = 1e6 + 7;
signed main() {
int n, q;
cin >> n >> q;
vector<int> w(n + 1);
for (int i = 1; i <= n; i++) {
cin >> w[i];
}
vector<array<int, 4>> query = {{}}; // {左区间, 右区间, 累计修改次数, 下标}
vector<array<int, 2>> modify = {{}}; // {修改的值, 修改的元素下标}
for (int i = 1; i <= q; i++) {
char op;
cin >> op;
if (op == 'Q') {
int l, r;
cin >> l >> r;
query.push_back({l, r, (int)modify.size() - 1, (int)query.size()});
} else {
int idx, w;
cin >> idx >> w;
modify.push_back({w, idx});
}
}
int Knum = 2154; // 计算块长 pow(n, 0.6666)
vector<int> K(n + 1);
for (int i = 1; i <= n; i++) { // 固定块长
K[i] = (i - 1) / Knum + 1;
}
sort(query.begin() + 1, query.end(), [&](auto x, auto y) {
if (K[x[0]] != K[y[0]]) return x[0] < y[0];
if (K[x[1]] != K[y[1]]) return x[1] < y[1];
return x[3] < y[3];
});
int l = 1, r = 0, val = 0;
int t = 0; // 累计修改次数
vector<int> ans(query.size()), cnt(N);
for (int i = 1; i < query.size(); i++) {
auto [ql, qr, qt, id] = query[i];
auto add = [&](int x) -> void {
if (cnt[x] == 0) ++ val;
++ cnt[x];
};
auto del = [&](int x) -> void {
-- cnt[x];
if (cnt[x] == 0) -- val;
};
auto time = [&](int x, int l, int r) -> void {
if (l <= modify[x][1] && modify[x][1] <= r) { //当修改的位置在询问期间内部时才会改变num的值
del(w[modify[x][1]]);
add(modify[x][0]);
}
swap(w[modify[x][1]], modify[x][0]); //直接交换修改数组的值与原始值,减少额外的数组开销,且方便复原
};
while (l > ql) add(w[--l]);
while (r < qr) add(w[++r]);
while (l < ql) del(w[l++]);
while (r > qr) del(w[r--]);
while (t < qt) time(++t, ql, qr);
while (t > qt) time(t--, ql, qr);
ans[id] = val;
}
for (int i = 1; i < ans.size(); i++) {
cout << ans[i] << endl;
}
}动态规划
01背包
有 件物品和一个容量为 的背包,第 件物品的体积为 ,价值为 ,求解将哪些物品装入背包中使总价值最大。
for (int i = 1; i <= n; i++) //当前装第 i 件物品
for (int j = W; j >= w[i]; j--) //背包容量为 j
dp[j] = max(dp[j], dp[j - w[i]] + v[i]); //判断背包容量为j的情况下能是实现总价值最大是多少完全背包
有 件物品和一个容量为 的背包,第 件物品的体积为 ,价值为 ,每件物品有无限个,求解将哪些物品装入背包中使总价值最大。
for (int i = 1; i <= n; i++)
for (int j = w[i]; j <= W; j++)
dp[j] = max(dp[j], dp[j - w[i]] + v[i]);多重背包
有 种物品和一个容量为 的背包,第 种物品的体积为 ,价值为 ,数量为 ,求解将哪些物品装入背包中使总价值最大。
思路:
对于每一种物品,都有 种取法,我们可以将其转化为01背包问题
for (int i = 1; i <= n; i++){
for (int j = W; j >= 0; j--)
for (int k = 0; k <= s[i]; k++){
if (j - k * w[i] < 0) break;
dp[j] = max(dp[j], dp[j - k * w[i]] + k * v[i]);
}上述方法的时间复杂度为 。
for (int i = 1; i <= n; i++){
scanf("%lld%lld%lld", &x, &y, &s); //x 为体积, y 为价值, s 为数量
t = 1;
while (s >= t){
w[++num] = x * t;
v[num] = y * t;
s -= t;
t *= 2;
}
w[++num] = x * s;
v[num] = y * s;
}
for (int i = 1; i <= num; i++)
for (int j = W; j >= w[i]; j--)
dp[j] = max(dp[j], dp[j - w[i]] + v[i]);尽管采用了 二进制优化,时间复杂度还是太高,采用 单调队列优化,将时间复杂度优化至
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
int n, W, w, v, s, f[N], g[N], q[N];
int main(){
ios::sync_with_stdio(false);cin.tie(0);
cin >> n >> W;
for (int i = 0; i < n; i ++ ){
memcpy ( g, f, sizeof f);
cin >> w >> v >> s;
for (int j = 0; j < w; j ++ ){
int head = 0, tail = -1;
for (int k = j; k <= W; k += w){
if ( head <= tail && k - s * w > q[head] ) head ++ ;//保证队列长度 <= s
while ( head <= tail && g[q[tail]] - (q[tail] - j) / w * v <= g[k] - (k - j) / w * v ) tail -- ;//保证队列单调递减
q[ ++ tail] = k;
f[k] = g[q[head]] + (k - q[head]) / w * v;
}
}
}
cout << f[W] << "\n";
return 0;
}分组背包
有 组物品,一个容量为 的背包,每组物品有若干,同一组的物品最多选一个,第 组第 件物品的体积为 ,价值为 ,求解将哪些物品装入背包,可使物品总体积不超过背包容量,且使总价值最大。
思路:
考虑每组中的某件物品选不选,可以选的话,去下一组选下一个,否则在这组继续寻找可以选的物品,当这组遍历完后,去下一组寻找。
#include <bits/stdc++.h>
using namespace std;
const int N = 110;
int n, W, s[N], w[N][N], v[N][N], dp[N];
int main(){
cin >> n >> W;
for (int i = 1; i <= n; i++){
scanf("%d", &s[i]);
for (int j = 1; j <= s[i]; j++)
scanf("%d %d", &w[i][j], &v[i][j]);
}
for (int i = 1; i <= n; i++)
for (int j = W; j >= 0; j--)
for (int k = 1; k <= s[i]; k++)
if (j - w[i][k] >= 0)
dp[j] = max(dp[j], dp[j - w[i][k]] + v[i][k]);
cout << dp[W] << "\n";
return 0;
}有依赖的背包
有 个物品和一个容量为 的背包,物品之间有依赖关系,且之间的依赖关系组成一颗 树 的形状,如果选择一个物品,则必须选择它的 父节点,第 件物品的体积是 ,价值为 ,依赖的父节点的编号为 ,若 等于 -1,则为 根节点。求将哪些物品装入背包中,使总体积不超过总容量,且总价值最大。
思路:
定义 为以第 个节点为根,容量为 的背包的最大价值。那么结果就是 ,为了知道根节点的最大价值,得通过其子节点来更新。所以采用递归的方式。
对于每一个点,先将这个节点装入背包,然后找到剩余容量可以实现的最大价值,最后更新父节点的最大价值即可。
#include <bits/stdc++.h>
using namespace std;
const int N = 110;
int n, W, w[N], v[N], p, f[N][N], root;
vector <int> g[N];
void dfs(int u){
for (int i = w[u]; i <= W; i ++ )
f[u][i] = v[u];
for (auto v : g[u]){
dfs(v);
for (int j = W; j >= w[u]; j -- )
for (int k = 0; k <= j - w[u]; k ++ )
f[u][j] = max(f[u][j], f[u][j - k] + f[v][k]);
}
}
int main(){
cin >> n >> W;
for (int i = 1; i <= n; i ++ ){
cin >> w[i] >> v[i] >> p;
if (p == -1) root = i;
else g[p].push_back(i);
}
dfs(root);
cout << f[root][W] << "\n";
return 0;
}背包问题求方案数
有 件物品和一个容量为 的背包,每件物品只能用一次,第 件物品的重量为 ,价值为 ,求解将哪些物品放入背包使总重量不超过背包容量,且总价值最大,输出 最优选法的方案数,答案可能很大,输出答案模 的结果。
思路:
开一个储存方案数的数组 , 表示容量为 时的 方案数,先将 的每一个值都初始化为 1,因为 不装任何东西就是一种方案,如果装入这件物品使总的价值 更大,那么装入后的方案数 等于 装之前的方案数,如果装入后总价值 相等,那么方案数就是 二者之和
#include <bits/stdc++.h>
using namespace std;
#define LL long long
const int mod = 1e9 + 7, N = 1010;
LL n, W, cnt[N], f[N], w, v;
int main(){
cin >> n >> W;
for (int i = 0; i <= W; i ++ )
cnt[i] = 1;
for (int i = 0; i < n; i ++ ){
cin >> w >> v;
for (int j = W; j >= w; j -- )
if (f[j] < f[j - w] + v){
f[j] = f[j - w] + v;
cnt[j] = cnt[j - w];
}
else if (f[j] == f[j - w] + v){
cnt[j] = (cnt[j] + cnt[j - w]) % mod;
}
}
cout << cnt[W] << "\n";
return 0;
}背包问题求具体方案
signed main() {
int Task = 1;
for (cin >> Task; Task; Task--) {
int n, m;
cin >> n >> m;
vector<int> w(n + 1), v(n + 1);
vector<vector<int>> dp(n + 2, vector<int>(m + 2));
for (int i = 1; i <= n; i++) {
cin >> w[i] >> v[i];
}
for (int i = n; i >= 1; i--) {
for (int j = 0; j <= m; j++) {
dp[i][j] = dp[i + 1][j];
if (j >= w[i]) {
dp[i][j] = max(dp[i][j], dp[i + 1][j - w[i]] + v[i]);
}
}
}
vector<int> ans;
for (int i = 1; i <= n; i++) {
if (m - w[i] >= 0 && dp[i][m] == dp[i + 1][m - w[i]] + v[i]) {
ans.push_back(i);
// cout << i << " ";
m -= w[i];
}
}
cout << ans.size() << "\n";
for (auto i : ans) {
cout << i << " ";
}
cout << "\n";
}
}数位 DP
/* pos 表示当前枚举到第几位
sum 表示 d 出现的次数
limit 为 1 表示枚举的数字有限制
zero 为 1 表示有前导 0
d 表示要计算出现次数的数 */
const int N = 15;
LL dp[N][N];
int num[N];
LL dfs(int pos, LL sum, int limit, int zero, int d) {
if (pos == 0) return sum;
if (!limit && !zero && dp[pos][sum] != -1) return dp[pos][sum];
LL ans = 0;
int up = (limit ? num[pos] : 9);
for (int i = 0; i <= up; i++) {
ans += dfs(pos - 1, sum + ((!zero || i) && (i == d)), limit && (i == num[pos]),
zero && (i == 0), d);
}
if (!limit && !zero) dp[pos][sum] = ans;
return ans;
}
LL solve(LL x, int d) {
memset(dp, -1, sizeof dp);
int len = 0;
while (x) {
num[++len] = x % 10;
x /= 10;
}
return dfs(len, 0, 1, 1, d);
}状压 DP
**题意:**在 的棋盘里面放 个国王,使他们互不攻击,共有多少种摆放方案。国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子。
#include <bits/stdc++.h>
using namespace std;
#define LL long long
const int N = 15, M = 150, K = 1500;
LL n, k;
LL cnt[K]; //每个状态的二进制中 1 的数量
LL tot; //合法状态的数量
LL st[K]; //合法的状态
LL dp[N][M][K]; //第 i 行,放置了 j 个国王,状态为 k 的方案数
int main(){
ios::sync_with_stdio(false);cin.tie(0);
cin >> n >> k;
for (int s = 0; s < (1 << n); s ++ ){ //找出合法状态
LL sum = 0, t = s;
while(t){ //计算 1 的数量
sum += (t & 1);
t >>= 1;
}
cnt[s] = sum;
if ( (( (s << 1) | (s >> 1) ) & s) == 0 ){ //判断合法性
st[ ++ tot] = s;
}
}
dp[0][0][0] = 1;
for (int i = 1; i <= n + 1; i ++ ){
for (int j1 = 1; j1 <= tot; j1 ++ ){ //当前的状态
LL s1 = st[j1];
for (int j2 = 1; j2 <= tot; j2 ++ ){ //上一行的状态
LL s2 = st[j2];
if ( ( (s2 | (s2 << 1) | (s2 >> 1)) & s1 ) == 0 ){
for (int j = 0; j <= k; j ++ ){
if (j - cnt[s1] >= 0)
dp[i][j][s1] += dp[i - 1][j - cnt[s1]][s2];
}
}
}
}
}
cout << dp[n + 1][k][0] << "\n";
return 0;
}常用例题
题意:在一篇文章(包含大小写英文字母、数字、和空白字符(制表/空格/回车))中寻找 (任意一个字母的大小写都行)的子序列出现了多少次,输出结果对 的余数。
字符串 DP ,构建一个二维 DP 数组, 的 表示文章中的第几个字符, 表示寻找的字符串的第几个字符,当字符串中的字符和文章中的字符相同时,即找到符合条件的字符, dp[i][j] = dp[i - 1][j] + dp[i - 1][j - 1] ,因为字符串中的每个字符不会对后面的结果产生影响,所以 DP 方程可以优化成一维的, 由于字符串中有重复的字符,所以比较时应该从后往前。
#include <bits/stdc++.h>
using namespace std;
#define LL long long
const int mod = 1e9 + 7;
char c, s[20] = "!helloworld";
LL dp[20];
int main(){
dp[0] = 1;
while ((c = getchar()) != EOF)
for (int i = 10; i >= 1; i--)
if (c == s[i] || c == s[i] - 32)
dp[i] = (dp[i] + dp[i - 1]) % mod;
cout << dp[10] << "\n";
return 0;
}题意:(最长括号匹配)给一个只包含‘(’,‘)’,‘[’,‘]’的非空字符串,“()”和“[]”是匹配的,寻找字符串中最长的括号匹配的子串,若有两串长度相同,输出靠前的一串。
设给定的字符串为 ,可以定义数组 表示以 结尾的字符串里最长的括号匹配的字符。显然,从 到 的字符串是括号匹配的,当找到一个字符是‘)’或‘]’时,再去判断第 的字符和第 位的字符是否匹配,如果是,那么 dp[i] = dp[i - 1] + 2 + dp[i - 2 - dp[i - 1]] 。
#include <bits/stdc++.h>
using namespace std;
const int maxn = 1e6 + 10;
string s;
int len, dp[maxn], ans, id;
int main(){
cin >> s;
len = s.length();
for (int i = 1; i < len; i++){
if ((s[i] == ')' && s[i - 1 - dp[i - 1]] == '(' ) || (s[i] == ']' && s[i - 1 - dp[i - 1]] == '[')){
dp[i] = dp[i - 1] + 2 + dp[i - 2 - dp[i - 1]];
if (dp[i] > ans) {
ans = dp[i]; //记录长度
id = i; //记录位置
}
}
}
for (int i = id - ans + 1; i <= id; i++)
cout << s[i];
cout << "\n";
return 0;
}题意:去掉区间内包含“4”和“62”的数字,输出剩余的数字个数
int T,n,m,len,a[20];//a数组用于判断每一位能取到的最大值
ll l,r,dp[20][15];
ll dfs(int pos,int pre,int limit){//记搜
//pos搜到的位置,pre前一位数
//limit判断是否有最高位限制
if(pos>len) return 1;//剪枝
if(dp[pos][pre]!=-1 && !limit) return dp[pos][pre];//记录当前值
ll ret=0;//暂时记录当前方案数
int res=limit?a[len-pos+1]:9;//res当前位能取到的最大值
for(int i=0;i<=res;i++)
if(!(i==4 || (pre==6 && i==2)))
ret+=dfs(pos+1,i,i==res&&limit);
if(!limit) dp[pos][pre]=ret;//当前状态方案数记录
return ret;
}
ll part(ll x){//把数按位拆分
len=0;
while(x) a[++len]=x%10,x/=10;
memset(dp,-1,sizeof dp);//初始化-1(因为有可能某些情况下的方案数是0)
return dfs(1,0,1);//进入记搜
}
int main(){
cin>>n;
while(n--){
cin>>l>>r;
if(l==0 && r==0)break;
if(l) printf("%lld\n",part(r)-part(l-1));//[l,r](l!=0)
else printf("%lld\n",part(r)-part(l));//从0开始要特判
}
}题意:求序列 本质不同的子序列个数
dp[1] = 1, last[a[1]] = 1;
for (int i = 2; i <= n; ++i) {
if (!last[a[i]]) dp[i] = (dp[i - 1] * 2 % mod + 1) % mod;
else dp[i] = (dp[i - 1] * 2 % mod - dp[last[a[i]] - 1] + mod) % mod; //有重复要减去
last[a[i]] = i;
}串
子串与子序列
| 中文名称 | 常见英文名称 | 解释 |
|---|---|---|
| 子串 | 连续的选择一段字符(可以全选、可以不选)组成的新字符串 | |
| 子序列 | 从左到右取出若干个字符(可以不取、可以全取、可以不连续)组成的新字符串 |
字符串模式匹配算法 KMP
应用:
- 在字符串中查找子串;
- 最小周期:字符串长度-整个字符串的 ;
- 最小循环节:区别于周期,当字符串长度 时,等于最小周期,否则为 。
以最坏 的时间计算 在 中出现的全部位置。
auto kmp = [&](string s, string t) {
int n = s.size(), m = t.size();
vector<int> kmp(m + 1), ans;
s = "@" + s;
t = "@" + t;
for (int i = 2, j = 0; i <= m; i++) {
while (j && t[i] != t[j + 1]) {
j = kmp[j];
}
j += t[i] == t[j + 1];
kmp[i] = j;
}
for (int i = 1, j = 0; i <= n; i++) {
while (j && s[i] != t[j + 1]) {
j = kmp[j];
}
if (s[i] == t[j + 1] && ++j == m) {
ans.push_back(i - m + 1); // t 在 s 中出现的位置
j = kmp[j];
}
}
return ans;
};Z函数(扩展 KMP)
获取字符串 和 (即以 开头的后缀)的最长公共前缀(LCP)的长度,总复杂度 。
vector<int> zFunction(string s) {
int n = s.size();
vector<int> z(n);
z[0] = n;
for (int i = 1, j = 1; i < n; i++) {
z[i] = max(0, min(j + z[j] - i, z[i - j]));
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) {
z[i]++;
}
if (i + z[i] > j + z[j]) {
j = i;
}
}
return z;
}最长公共子序列 LCS
求解两个串的最长公共子序列的长度。
小数据解
针对 以内的数据。
const int N = 1e3 + 10;
char a[N], b[N];
int n, m, f[N][N];
void solve(){
cin >> n >> m >> a + 1 >> b + 1;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++){
f[i][j] = max(f[i - 1][j], f[i][j - 1]);
if (a[i] == b[j]) f[i][j] = max(f[i][j], f[i - 1][j - 1] + 1);
}
cout << f[n][m] << "\n";
}
int main(){
solve();
return 0;
}大数据解
针对 以内的数据。
const int INF = 0x7fffffff;
int n, a[maxn], b[maxn], f[maxn], p[maxn];
int main(){
cin >> n;
for (int i = 1; i <= n; i++){
scanf("%d", &a[i]);
p[a[i]] = i; //将第二个序列中的元素映射到第一个中
}
for (int i = 1; i <= n; i++){
scanf("%d", &b[i]);
f[i] = INF;
}
int len = 0;
f[0] = 0;
for (int i = 1; i <= n; i++){
if (p[b[i]] > f[len]) f[++len] = p[b[i]];
else {
int l = 0, r = len;
while (l < r){
int mid = (l + r) >> 1;
if (f[mid] > p[b[i]]) r = mid;
else l = mid + 1;
}
f[l] = min(f[l], p[b[i]]);
}
}
cout << len << "\n";
return 0;
}字符串哈希
单哈希封装
bool isprime(int n) {
if (n <= 1) {
return false;
}
for (int i = 2; i * i <= n; i++) {
if (n % i == 0) {
return false;
}
}
return true;
}
int findPrime(int n) {
while (!isprime(n)) {
n++;
}
return n;
}
std::mt19937 rng(std::chrono::steady_clock::now().time_since_epoch().count());
const int P = findPrime(rng() % 900000000 + 100000000);
const int base = uniform_int_distribution<>(8e8, 9e8)(rng);
int p[N];
void init_hash(int n) {
p[0] = 1;
for (int i = 1; i <= n; ++i)p[i] = p[i - 1] * base % P;
}
struct Hash {
vector<int> h;
int n;
string s;
Hash(int n, string s) {
s = ' ' + s;
this->n = n;
this->s = s;
h.resize(n + 1, 0);
for (int i = 1; i <= n; ++i) h[i] = (h[i - 1] * base + s[i]) % P;
}
int get(int l, int r) {
return (h[r] + (P - h[l - 1]) * p[r - l + 1]) % P;
}
};双哈希封装
随机质数列表:1111111121、1211111123、1311111119。
const int N = 1 << 21;
static const int mod1 = 1E9 + 7, base1 = 127;
static const int mod2 = 1E9 + 9, base2 = 131;
using U = Zmod<mod1>;
using V = Zmod<mod2>;
vector<U> val1;
vector<V> val2;
void init(int n = N) {
val1.resize(n + 1), val2.resize(n + 2);
val1[0] = 1, val2[0] = 1;
for (int i = 1; i <= n; i++) {
val1[i] = val1[i - 1] * base1;
val2[i] = val2[i - 1] * base2;
}
}
struct String {
vector<U> hash1;
vector<V> hash2;
string s;
String(string s_) : s(s_), hash1{1}, hash2{1} {
for (auto it : s) {
hash1.push_back(hash1.back() * base1 + it);
hash2.push_back(hash2.back() * base2 + it);
}
}
pair<U, V> get() { // 输出整串的哈希值
return {hash1.back(), hash2.back()};
}
pair<U, V> substring(int l, int r) { // 输出子串的哈希值
if (l > r) swap(l, r);
U ans1 = hash1[r + 1] - hash1[l] * val1[r - l + 1];
V ans2 = hash2[r + 1] - hash2[l] * val2[r - l + 1];
return {ans1, ans2};
}
pair<U, V> modify(int idx, char x) { // 修改 idx 位为 x
int n = s.size() - 1;
U ans1 = hash1.back() + val1[n - idx] * (x - s[idx]);
V ans2 = hash2.back() + val2[n - idx] * (x - s[idx]);
return {ans1, ans2};
}
};前后缀去重
sample please ease 去重后得到 samplease。
string compress(vector<string> in) { // 前后缀压缩
vector<U> hash1{1};
vector<V> hash2{1};
string ans = "#";
for (auto s : in) {
s = "#" + s;
int st = 0;
U chk1 = 0;
V chk2 = 0;
for (int j = 1; j < s.size() && j < ans.size(); j++) {
chk1 = chk1 * base1 + s[j];
chk2 = chk2 * base2 + s[j];
if ((hash1.back() == hash1[ans.size() - 1 - j] * val1[j] + chk1) &&
(hash2.back() == hash2[ans.size() - 1 - j] * val2[j] + chk2)) {
st = j;
}
}
for (int j = st + 1; j < s.size(); j++) {
ans += s[j];
hash1.push_back(hash1.back() * base1 + s[j]);
hash2.push_back(hash2.back() * base2 + s[j]);
}
}
return ans.substr(1);
}马拉车
时间求出字符串的最长回文子串。
string s;
cin >> s;
int n = s.length();
string t = "-#";
for (int i = 0; i < n; i++) {
t += s[i];
t += '#';
}
int m = t.length();
t += '+';
int mid = 0, r = 0;
vector<int> p(m);
for (int i = 1; i < m; i++) {
p[i] = i < r ? min(p[2 * mid - i], r - i) : 1;
while (t[i - p[i]] == t[i + p[i]]) p[i]++;
if (i + p[i] > r) {
r = i + p[i];
mid = i;
}
}字典树 trie
struct Trie {
int ch[N][63], cnt[N], idx = 0; // N为字符串总长度!
map<char, int> mp;
void init() {
LL id = 0;
for (char c = 'a'; c <= 'z'; c++) mp[c] = ++id;
for (char c = 'A'; c <= 'Z'; c++) mp[c] = ++id;
for (char c = '0'; c <= '9'; c++) mp[c] = ++id;
}
void insert(string s) {
int u = 0;
for (int i = 0; i < s.size(); i++) {
int v = mp[s[i]];
if (!ch[u][v]) ch[u][v] = ++idx;
u = ch[u][v];
cnt[u]++;
}
}
LL query(string s) {
int u = 0;
for (int i = 0; i < s.size(); i++) {
int v = mp[s[i]];
if (!ch[u][v]) return 0;
u = ch[u][v];
}
return cnt[u];
}
void Clear() {
for (int i = 0; i <= idx; i++) {
cnt[i] = 0;
for (int j = 0; j <= 62; j++) {
ch[i][j] = 0;
}
}
idx = 0;
}
} trie;01 字典树
struct Trie {
int n, idx;
vector<vector<int>> ch;
Trie(int n) {
this->n = n;
idx = 0;
ch.resize(30 * (n + 1), vector<int>(2));
}
void insert(int x) {
int u = 0;
for (int i = 30; ~i; i--) {
int &v = ch[u][x >> i & 1];
if (!v) v = ++idx;
u = v;
}
}
int query(int x) {
int u = 0, res = 0;
for (int i = 30; ~i; i--) {
int v = x >> i & 1;
if (ch[u][!v]) {
res += (1 << i);
u = ch[u][!v];
} else {
u = ch[u][v];
}
}
return res;
}
};后缀数组 SA
以 的复杂度求解。
struct SuffixArray {
int n;
vector<int> sa, rk, lc;
SuffixArray(const string &s) {
n = s.length();
sa.resize(n);
lc.resize(n - 1);
rk.resize(n);
iota(sa.begin(), sa.end(), 0);
sort(sa.begin(), sa.end(), [&](int a, int b) { return s[a] < s[b]; });
rk[sa[0]] = 0;
for (int i = 1; i < n; ++i) {
rk[sa[i]] = rk[sa[i - 1]] + (s[sa[i]] != s[sa[i - 1]]);
}
int k = 1;
vector<int> tmp, cnt(n);
tmp.reserve(n);
while (rk[sa[n - 1]] < n - 1) {
tmp.clear();
for (int i = 0; i < k; ++i) {
tmp.push_back(n - k + i);
}
for (auto i : sa) {
if (i >= k) {
tmp.push_back(i - k);
}
}
fill(cnt.begin(), cnt.end(), 0);
for (int i = 0; i < n; ++i) {
++cnt[rk[i]];
}
for (int i = 1; i < n; ++i) {
cnt[i] += cnt[i - 1];
}
for (int i = n - 1; i >= 0; --i) {
sa[--cnt[rk[tmp[i]]]] = tmp[i];
}
swap(rk, tmp);
rk[sa[0]] = 0;
for (int i = 1; i < n; ++i) {
rk[sa[i]] = rk[sa[i - 1]] + (tmp[sa[i - 1]] < tmp[sa[i]] || sa[i - 1] + k == n ||
tmp[sa[i - 1] + k] < tmp[sa[i] + k]);
}
k *= 2;
}
for (int i = 0, j = 0; i < n; ++i) {
if (rk[i] == 0) {
j = 0;
continue;
}
for (j -= j > 0;
i + j < n && sa[rk[i] - 1] + j < n && s[i + j] == s[sa[rk[i] - 1] + j];) {
++j;
}
lc[rk[i] - 1] = j;
}
}
};AC 自动机
定义 是模板串的长度, 是文本串的长度, 是字符集的大小(常数,一般为 ),时间复杂度为 。
struct AhoCorasick {
static constexpr int ALPHABET = 26; // 字符集大小
struct Node {
int len; // 该节点表示的字符串长度(深度)
int link; // fail指针
int cnt; // 该字符串的个数
std::array<int, ALPHABET> next;
Node() : len{0}, link{0}, cnt{0}, next{} {}
};
std::vector<Node> t;
AhoCorasick() {
init();
}
void init() {
t.assign(2, Node());
t[0].next.fill(1); // 0虚结点(便于fail)
t[0].len = -1; // 1空节点(空字符串)
}
int newNode() {
t.emplace_back();
return t.size() - 1;
}
void add(const std::string &a) {
int p = 1;
for (const auto &c: a) {
int x = c - 'a';
if (!t[p].next[x]) {
t[p].next[x] = newNode();
t[t[p].next[x]].len = t[p].len + 1;
}
p = t[p].next[x];
}
++t[p].cnt;
}
void work() {
std::queue<int> q;
q.push(1);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < ALPHABET; i++) {
int &v = t[u].next[i];
if (!v) v = next(link(u), i);
else t[v].link = next(link(u), i), q.push(v);
}
}
}
i64 query(const std::string &a) {
i64 ans = 0, u = 1;
for (const auto &c: a) {
int x = c - 'a';
u = next(u, x);
for (int v = u; v && ~t[v].cnt; v = link(v)) {
ans += t[v].cnt;
t[v].cnt = -1;
}
}
return ans;
}
int next(int p, int x) {
return t[p].next[x];
}
int link(int p) {
return t[p].link;
}
int len(int p) {
return t[p].len;
}
int size() {
return t.size();
}
};回文自动机 PAM(回文树)
应用:
- 本质不同的回文串个数: ;
- 回文子串出现次数。
对于一个字符串 ,它的本质不同回文子串个数最多只有 个,那么,构造 的回文树的时间复杂度是 。
struct PalindromeAutomaton {
constexpr static int N = 5e5 + 10;
int tr[N][26], fail[N], len[N];
int cntNodes, last;
int cnt[N];
string s;
PalindromeAutomaton(string s) {
memset(tr, 0, sizeof tr);
memset(fail, 0, sizeof fail);
len[0] = 0, fail[0] = 1;
len[1] = -1, fail[1] = 0;
cntNodes = 1;
last = 0;
this->s = s;
}
void insert(char c, int i) {
int u = get_fail(last, i);
if (!tr[u][c - 'a']) {
int v = ++cntNodes;
fail[v] = tr[get_fail(fail[u], i)][c - 'a'];
tr[u][c - 'a'] = v;
len[v] = len[u] + 2;
cnt[v] = cnt[fail[v]] + 1;
}
last = tr[u][c - 'a'];
}
int get_fail(int u, int i) {
while (i - len[u] - 1 <= -1 || s[i - len[u] - 1] != s[i]) {
u = fail[u];
}
return u;
}
};后缀自动机 SAM
定义 是字符集的大小,复杂度为 。
// 有向无环图
struct SuffixAutomaton {
static constexpr int N = 1e6;
struct node {
int len, link, nxt[26];
int siz;
} t[N << 1];
int cntNodes;
SuffixAutomaton() {
cntNodes = 1;
fill(t[0].nxt, t[0].nxt + 26, 1);
t[0].len = -1;
}
int extend(int p, int c) {
if (t[p].nxt[c]) {
int q = t[p].nxt[c];
if (t[q].len == t[p].len + 1) {
return q;
}
int r = ++cntNodes;
t[r].siz = 0;
t[r].len = t[p].len + 1;
t[r].link = t[q].link;
copy(t[q].nxt, t[q].nxt + 26, t[r].nxt);
t[q].link = r;
while (t[p].nxt[c] == q) {
t[p].nxt[c] = r;
p = t[p].link;
}
return r;
}
int cur = ++cntNodes;
t[cur].len = t[p].len + 1;
t[cur].siz = 1;
while (!t[p].nxt[c]) {
t[p].nxt[c] = cur;
p = t[p].link;
}
t[cur].link = extend(p, c);
return cur;
}
};子序列自动机
对于给定的长度为 的主串 ,以 的时间复杂度预处理、 的复杂度判定长度为 的询问串是否是主串的子序列。
自动离散化、自动类型匹配封装
template<class T> struct SequenceAutomaton {
vector<T> alls;
vector<vector<int>> ver;
SequenceAutomaton(auto in) {
for (auto &i : in) {
alls.push_back(i);
}
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
ver.resize(alls.size() + 1);
for (int i = 0; i < in.size(); i++) {
ver[get(in[i])].push_back(i + 1);
}
}
bool count(T x) {
return binary_search(alls.begin(), alls.end(), x);
}
int get(T x) {
return lower_bound(alls.begin(), alls.end(), x) - alls.begin();
}
bool contains(auto in) {
int at = 0;
for (auto &i : in) {
if (!count(i)) {
return false;
}
auto j = get(i);
auto it = lower_bound(ver[j].begin(), ver[j].end(), at + 1);
if (it == ver[j].end()) {
return false;
}
at = *it;
}
return true;
}
};博弈论
巴什博奕
有 个石子,两名玩家轮流行动,按以下规则取石子:
规定:每人每次可以取走 个石子,拿到最后一颗石子的一方获胜。
双方均采用最优策略,询问谁会获胜。
两名玩家轮流报数。
规定:第一个报数的人可以报 ,后报数的人需要比前者所报数大 ,率先报到 的人获胜。
双方均采用最优策略,询问谁会获胜。
- (其中 ),后手必胜(后手可以控制每一回合结束时双方恰好取走 个,重复 轮后即胜利);
- (其中 ),先手必胜(先手先取走 个,之后控制每一回合结束时双方恰好取走 个,重复 轮后即胜利)。
扩展巴什博弈
有 颗石子,两名玩家轮流行动,按以下规则取石子:。
规定:每人每次可以取走 个石子,如果最后剩余物品的数量小于 个,则不能再取,拿到最后一颗石子的一方获胜。
双方均采用最优策略,询问谁会获胜。
- 时,后手必胜;
- (其中 ) 时,后手必胜(这些数量不够再取一次,先手无法逆转局面);
- (其中 ) 时,先手必胜;
- (其中 ) 时,先手必胜(这些数量不够再取一次,后手无法逆转局面);
Nim 博弈
有 堆石子,给出每一堆的石子数量,两名玩家轮流行动,按以下规则取石子:
规定:每人每次任选一堆,取走正整数颗石子,拿到最后一颗石子的一方获胜(注:几个特点是不能跨堆、不能不拿)。
双方均采用最优策略,询问谁会获胜。
记初始时各堆石子的数量 ,定义尼姆和 。
当 时先手必败,反之先手必胜。
Nim 游戏具体取法
先计算出尼姆和,再对每一堆石子计算 ,记为 。
若得到的值 , 即为一个可行解,即剩下 颗石头,取走 颗石头(这里取小于号是因为至少要取走 颗石子)。
Moore’s Nim 游戏(Nim-K 游戏)
有 堆石子,给出每一堆的石子数量,两名玩家轮流行动,按以下规则取石子:
规定:每人每次任选不超过 堆,对每堆都取走不同的正整数颗石子,拿到最后一颗石子的一方获胜。
双方均采用最优策略,询问谁会获胜。
把每一堆石子的石子数用二进制表示,定义 为二进制第 位上 的个数。
以下局面先手必胜:
对于每一位, 均不为 的倍数。
Anti-Nim 游戏(反 Nim 游戏)
有 堆石子,给出每一堆的石子数量,两名玩家轮流行动,按以下规则取石子:
规定:每人每次任选一堆,取走正整数颗石子,拿到最后一颗石子的一方出局。
双方均采用最优策略,询问谁会获胜。
- 所有堆的石头数量均不超过 ,且 (也可看作“且有偶数堆”);
- 至少有一堆的石头数量大于 ,且 。
阶梯 - Nim 博弈
有 级台阶,每一级台阶上均有一定数量的石子,给出每一级石子的数量,两名玩家轮流行动,按以下规则操作石子:
规定:每人每次任选一级台阶,拿走正整数颗石子放到下一级台阶中,已经拿到地面上的石子不能再拿,拿到最后一颗石子的一方获胜。
双方均采用最优策略,询问谁会获胜。
对奇数台阶做传统 博弈,当 时先手必败,反之先手必胜.
SG 游戏(有向图游戏)
我们使用以下几条规则来定义暴力求解的过程:
- 使用数字来表示输赢情况, 代表局面必败,非 代表存在必胜可能,我们称这个数字为这个局面的SG值;
- 找到最终态,根据题意人为定义最终态的输赢情况;
- 对于非最终态的某个节点,其SG值为所有子节点的SG值取 ;
- 单个游戏的输赢态即对应根节点的SG值是否为 ,为 代表先手必败,非 代表先手必胜;
- 多个游戏的总SG值为单个游戏SG值的异或和。
使用哈希表,以 的复杂度计算。
int n, m, a[N], num[N];
int sg(int x) {
if (num[x] != -1) return num[x];
unordered_set<int> S;
for (int i = 1; i <= m; ++ i)
if(x >= a[i])
S.insert(sg(x - a[i]));
for (int i = 0; ; ++ i)
if (S.count(i) == 0)
return num[x] = i;
}
void Solve() {
cin >> m;
for (int i = 1; i <= m; ++ i) cin >> a[i];
cin >> n;
int ans = 0; memset(num, -1, sizeof num);
for (int i = 1; i <= n; ++ i) {
int x; cin >> x;
ans ^= sg(x);
}
if (ans == 0) no;
else yes;
}Anti-SG 游戏(反 SG 游戏)
SG 游戏中最先不能行动的一方获胜。
以下局面先手必胜:
- 单局游戏的SG值均不超过 ,且总SG值为 ;
- 至少有一局单局游戏的SG值大于 ,且总SG值不为 。
在本质上,这与 Anti-Nim 游戏的结论一致。
Lasker’s-Nim 游戏( Multi-SG 游戏)
有 堆石子,给出每一堆的石子数量,两名玩家轮流行动,每人每次任选以下规定的一种操作石子:
- 任选一堆,取走正整数颗石子;
- 任选数量大于 的一堆,分成两堆非空石子。
拿到最后一颗石子的一方获胜。双方均采用最优策略,询问谁会获胜。
本题使用SG函数求解,SG值定义为:
Every-SG 游戏
给出一个有向无环图,其中 个顶点上放置了石子,两名玩家轮流行动,按以下规则操作石子:
移动图上所有还能够移动的石子;
无法移动石子的一方出局。双方均采用最优策略,询问谁会获胜。
定义 为某一局游戏至多需要经过的回合数。
以下局面先手必胜: 为奇数 。
威佐夫博弈
有两堆石子,给出每一堆的石子数量,两名玩家轮流行动,每人每次任选以下规定的一种操作石子:
- 任选一堆,取走正整数颗石子;
- 从两队中同时取走正整数颗石子。
拿到最后一颗石子的一方获胜。双方均采用最优策略,询问谁会获胜。
以下局面先手必败:
具体而言,每一对的第一个数为此前没出现过的最小整数,第二个数为第一个数加上 。
更一般地,对于第 对数,第一个数为 ,第二个数为 。
其中,在两堆石子的数量均大于 次时,由于需要使用高精度计算,我们需要人为定义 的取值为 。
const double lorry = (sqrt(5.0) + 1.0) / 2.0;
//const double lorry = 1.618033988749894848204586834;
void Solve() {
int n, m; cin >> n >> m;
if (n < m) swap(n, m);
double x = n - m;
if ((int)(lorry * x) == m) cout << "lose\n";
else cout << "win\n";
}斐波那契博弈
有一堆石子,数量为 ,两名玩家轮流行动,按以下规则取石子:
先手第1次可以取任意多颗,但不能全部取完,此后每人取的石子数不能超过上个人的两倍,拿到最后一颗石子的一方获胜。
双方均采用最优策略,询问谁会获胜。
当且仅当 为斐波那契数时先手必败。
int fib[100] = {1, 2};
map<int, bool> mp;
void Force() {
for (int i = 2; i <= 86; ++ i) fib[i] = fib[i - 1] + fib[i - 2];
for (int i = 0; i <= 86; ++ i) mp[fib[i]] = 1;
}
void Solve() {
int n; cin >> n;
if (mp[n] == 1) cout << "lose\n";
else cout << "win\n";
}树上删边游戏
给出一棵 个节点的有根树,两名玩家轮流行动,按以下规则操作:
选择任意一棵子树并删除(即删去任意一条边,不与根相连的部分会同步被删去);
删掉最后一棵子树的一方获胜(换句话说,删去根节点的一方失败)。双方均采用最优策略,询问谁会获胜。
结论:当根节点SG值非 时先手必胜。
相较于传统SG值的定义,本题的SG函数值定义为:
- 叶子节点的SG值为 。
- 非叶子节点的SG值为其所有孩子节点SG值 的异或和。
auto dfs = [&](auto self, int x, int fa) -> int {
int x = 0;
for (auto y : ver[x]) {
if (y == fa) continue;
x ^= self(self, y, x);
}
return x + 1;
};
cout << (dfs(dfs, 1, 0) == 1 ? "Bob\n" : "Alice\n");无向图删边游戏(Fusion Principle 定理)
给出一张 个节点的无向联通图,有一个点作为图的根,两名玩家轮流行动,按以下规则操作:
选择任意一条边删除,不与根相连的部分会同步被删去;
删掉最后一条边的一方获胜。双方均采用最优策略,询问谁会获胜。
- 对于奇环,我们将其缩成一个新点+一条新边;
- 对于偶环,我们将其缩成一个新点;
- 所有连接到原来环上的边全部与新点相连。
此时,本模型转化为“树上删边游戏”。
STL
库函数
pb_ds 库
其中 gp_hash_table 使用的最多,其等价于 unordered_map ,内部是无序的。
#include <bits/extc++.h>
#include <ext/pb_ds/assoc_container.hpp>
template<class S, class T> using omap = __gnu_pbds::gp_hash_table<S, T, myhash>;查找后继 lower_bound、upper_bound
lower 表示 ,upper 表示 。使用前记得先进行排序。
//返回a数组[start,end)区间中第一个>=x的地址【地址!!!】
cout << lower_bound(a + start, a + end, x);
cout << lower_bound(a, a + n, x) - a; //在a数组中查找第一个>=x的元素下标
upper_bound(a, a + n, k) - lower_bound(a, a + n, k) //查找k在a中出现了几次数组打乱 shuffle
mt19937 rnd(chrono::steady_clock::now().time_since_epoch().count());
shuffle(ver.begin(), ver.end(), rnd);二分搜索 binary_search
用于查找某一元素是否在容器中,相当于 find 函数。在使用前需要先进行排序。
//在a数组[start,end)区间中查找x是否存在,返回bool型
cout << binary_search(a + start, a + end, x);批量递增赋值函数 iota
对容器递增初始化。
//将a数组[start,end)区间复制成“x,x+1,x+2,…”
iota(a + start, a + end, x);数组去重函数 unique
在使用前需要先进行排序。
其作用是,对于区间 [开始位置, 结束位置) ,不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置。并且返回去重后容器中不重复序列的最后一个元素的下一个元素。所以在进行操作后,数组、容器的大小并没有发生改变。
//将a数组[start,end)区间去重,返回迭代器
unique(a + start, a + end);
//与earse函数结合,达到去重+删除的目的
a.erase(unique(ALL(a)), a.end());bit 库与位运算函数 __builtin_
__builtin_popcount(x) // 返回x二进制下含1的数量,例如x=15=(1111)时答案为4
__builtin_ffs(x) // 返回x右数第一个1的位置(1-idx),1(1) 返回 1,8(1000) 返回 4,26(11010) 返回 2
__builtin_ctz(x) // 返回x二进制下后导0的个数,1(1) 返回 0,8(1000) 返回 3
bit_width(x) // 返回x二进制下的位数,9(1001) 返回 4,26(11010) 返回 5注:以上函数的 版本只需要在函数后面加上 ll 即可(例如 __builtin_popcountll(x) ), 加上 ull 。
数字转字符串函数
itoa 虽然能将整数转换成任意进制的字符串,但是其不是标准的C函数,且为Windows独有,且不支持 long long ,建议手写。
// to_string函数会直接将你的各种类型的数字转换为字符串。
// string to_string(T val);
double val = 12.12;
cout << to_string(val);// 【不建议使用】itoa允许你将整数转换成任意进制的字符串,参数为待转换整数、目标字符数组、进制。
// char* itoa(int value, char* string, int radix);
char ans[10] = {};
itoa(12, ans, 2);
cout << ans << endl; /*1100*/
// 长整型函数名ltoa,最高支持到int型上限2^31。ultoa同理。字符串转数字
// stoi直接使用
cout << stoi("12") << endl;
// 【不建议使用】stoi转换进制,参数为待转换字符串、起始位置、进制。
// int stoi(string value, int st, int radix);
cout << stoi("1010", 0, 2) << endl; /*10*/
cout << stoi("c", 0, 16) << endl; /*12*/
cout << stoi("0x3f3f3f3f", 0, 0) << endl; /*1061109567*/
// 长整型函数名stoll,最高支持到long long型上限2^63。stoull、stod、stold同理。// atoi直接使用,空字符返回0,允许正负符号,数字字符前有其他字符返回0,数字字符前有空白字符自动去除
cout << atoi("12") << endl;
cout << atoi(" 12") << endl; /*12*/
cout << atoi("-12abc") << endl; /*-12*/
cout << atoi("abc12") << endl; /*0*/
// 长整型函数名atoll,最高支持到long long型上限2^63。全排列算法 next_permutation、prev_permutation
在提及这个函数时,我们先需要补充几点字典序相关的知识。
对于三个字符所组成的序列
{a,b,c},其按照字典序的6种排列分别为:{abc},{acb},{bac},{bca},{cab},{cba}
其排序原理是:先固定a(序列内最小元素),再对之后的元素排列。而b<c,所以abc<acb。同理,先固定b(序列内次小元素),再对之后的元素排列。即可得出以上序列。
算法,即是按照字典序顺序输出的全排列;相对应的, 则是按照逆字典序顺序输出的全排列。可以是数字,亦可以是其他类型元素。其直接在序列上进行更新,故直接输出序列即可。
int n;
cin >> n;
vector<int> a(n);
// iota(a.begin(), a.end(), 1);
for (auto &it : a) cin >> it;
sort(a.begin(), a.end());
do {
for (auto it : a) cout << it << " ";
cout << endl;
} while (next_permutation(a.begin(), a.end()));字符串转换为数值函数 sto
可以快捷的将一串字符串转换为指定进制的数字。
使用方法
stoi(字符串, 0, x进制):将一串 进制的字符串转换为 型数字。
stoll(字符串, 0, x进制):将一串 进制的字符串转换为 型数字。- 同理。
数值转换为字符串函数 to_string
允许将各种数值类型转换为字符串类型。
//将数值num转换为字符串s
string s = to_string(num);判断非递减 is_sorted
//a数组[start,end)区间是否是非递减的,返回bool型
cout << is_sorted(a + start, a + end);累加 accumulate
//将a数组[start,end)区间的元素进行累加,并输出累加和+x的值
cout << accumulate(a + start, a + end, x);迭代器 iterator
//构建一个UUU容器的正向迭代器,名字叫it
UUU::iterator it;
vector<int>::iterator it; //创建一个正向迭代器,++ 操作时指向下一个
vector<int>::reverse_iterator it; //创建一个反向迭代器,++ 操作时指向上一个其他函数
exp2(x) :返回
log2(x) :返回
gcd(x, y) / lcm(x, y) :以 的复杂度返回 与 ,且返回值符号也为正数。
容器与成员函数
元组 tuple
//获取obj对象中的第index个元素——get<index>(obj)
//需要注意的是这里的index只能手动输入,使用for循环这样的自动输入是不可以的
tuple<string, int, int> Student = {"Wida", 23, 45000);
cout << get<0>(Student) << endl; //获取Student对象中的第一个元素,这里的输出结果应为“Wida”数组 array
array<int, 3> x; // 建立一个包含三个元素的数组x
[] // 跟正常数组一样,可以使用随机访问
cout << x[0]; // 获取数组重的第一个元素变长数组 vector
resize(n) // 重设容器大小,但是不改变已有元素的值
assign(n, 0) // 重设容器大小为n,且替换容器内的内容为0
// 尽量不要使用[]的形式声明多维变长数组,而是使用嵌套的方式替代
vector<int> ver[n + 1]; // 不好的声明方式
vector<vector<int>> ver(n + 1);
// 嵌套时只需要在最后一个注明变量类型
vector dis(n + 1, vector<int>(m + 1));
vector dis(m + 1, vector(n + 1, vector<int>(n + 1)));栈 stack
栈顶入,栈顶出。先进后出。
//没有clear函数
size() / empty()
push(x) //向栈顶插入x
top() //获取栈顶元素
pop() //弹出栈顶元素队列 queue
队尾进,队头出。先进先出。
//没有clear函数
size() / empty()
push(x) //向队尾插入x
front() / back() //获取队头、队尾元素
pop() //弹出队头元素//没有clear函数,但是可以用重新构造替代
queue<int> q;
q = queue<int>();双向队列 deque
size() / empty() / clear()
push_front(x) / push_back(x)
pop_front(x) / pop_back(x)
front() / back()
begin() / end()
[]优先队列 priority_queue
默认升序(大根堆),自定义排序需要重载 < 。
//没有clear函数
priority_queue<int, vector<int>, greater<int> > p; //重定义为降序(小根堆)
push(x); //向栈顶插入x
top(); //获取栈顶元素
pop(); //弹出栈顶元素//重载运算符【注意,符号相反!!!】
struct Node {
int x; string s;
friend bool operator < (const Node &a, const Node &b) {
if (a.x != b.x) return a.x > b.x;
return a.s > b.s;
}
};字符串 string
size() / empty() / clear()//从字符串S的S[start]开始,取出长度为len的子串——S.substr(start, len)
//len省略时默认取到结尾,超过字符串长度时也默认取到结尾
cout << S.substr(1, 12);
find(x) / rfind(x); //顺序、逆序查找x,返回下标,没找到时返回一个极大值【!建议与 size() 比较,而不要和 -1 比较,后者可能出错】
//注意,没有count函数有序、多重有序集合 set、multiset
默认升序(大根堆), 去重, 不去重, 。
set<int, greater<> > s; //重定义为降序(小根堆)
size() / empty() / clear()
begin() / end()
++ / -- //返回前驱、后继
insert(x); //插入x
find(x) / rfind(x); //顺序、逆序查找x,返回迭代器【迭代器!!!】,没找到时返回end()
count(x); //返回x的个数
lower_cound(x); //返回第一个>=x的迭代器【迭代器!!!】
upper_cound(x); //返回第一个>x的迭代器【迭代器!!!】特殊函数 next 和 prev 详解:
auto it = s.find(x); // 建立一个迭代器
prev(it) / next(it); // 默认返回迭代器it的前/后一个迭代器
prev(it, 2) / next(it, 2); // 可选参数可以控制返回前/后任意个迭代器
/* 以下是一些应用 */
auto pre = prev(s.lower_bound(x)); // 返回第一个<x的迭代器
int ed = *prev(S.end(), 1); // 返回最后一个元素erase(x); 有两种删除方式:
- 当x为某一元素时,删除所有这个数,复杂度为 ;
- 当x为迭代器时,删除这个迭代器。
//连续头部删除
set<int> S = {0, 9, 98, 1087, 894, 34, 756};
auto it = S.begin();
int len = S.size();
for (int i = 0; i < len; ++ i) {
if (*it >= 500) continue;
it = S.erase(it); //删除所有小于500的元素
}
//错误用法如下【千万不能这样用!!!】
//for (auto it : S) {
// if (it >= 500) continue;
// S.erase(it); //删除所有小于500的元素
//}map、multimap
默认升序(大根堆), 去重, 不去重, ,其中 为元素数量。
map<int, int, greater<> > mp; //重定义为降序(小根堆)
size() / empty() / clear()
begin() / end()
++ / -- //返回前驱、后继
insert({x, y}); //插入二元组
[] //随机访问,multimap不支持
count(x); //返回x为下标的个数
lower_cound(x); //返回第一个下标>=x的迭代器
upper_cound(x); //返回第一个下标>x的迭代器erase(x); 有两种删除方式:
- 当x为某一元素时,删除所有以这个元素为下标的二元组,复杂度为 ;
- 当x为迭代器时,删除这个迭代器。
慎用随机访问!——当不确定某次查询是否存在于容器中时,不要直接使用下标查询,而是先使用 count() 或者 find() 方法检查key值,防止不必要的零值二元组被构造。
int q = 0;
if (mp.count(i)) q = mp[i];慎用自带的 pair、tuple 作为key值类型!使用自定义结构体!
struct fff {
LL x, y;
friend bool operator < (const fff &a, const fff &b) {
if (a.x != b.x) return a.x < b.x;
return a.y < b.y;
}
};
map<fff, int> mp;bitset
将数据转换为二进制,从高位到低位排序,以 为最低位。当位数相同时支持全部的位运算。
// 如果输入的是01字符串,可以直接使用">>"读入
bitset<10> s;
cin >> s;
//使用只含01的字符串构造——bitset<容器长度>B (字符串)
string S; cin >> S;
bitset<32> B (S);
//使用整数构造(两种方式)
int x; cin >> x;
bitset<32> B1 (x);
bitset<32> B2 = x;
// 构造时,尖括号里的数字不能是变量
int x; cin >> x;
bitset<x> ans; // 错误构造
[] //随机访问
set(x) //将第x位置1,x省略时默认全部位置1
reset(x) //将第x位置0,x省略时默认全部位置0
flip(x) //将第x位取反,x省略时默认全部位取反
to_ullong() //重转换为ULL类型
to_string() //重转换为ULL类型
count() //返回1的个数
any() //判断是否至少有一个1
none() //判断是否全为0
_Find_fisrt() // 找到从低位到高位第一个1的位置
_Find_next(x) // 找到当前位置x的下一个1的位置,复杂度 O(n/w + count)
bitset<23> B1("11101001"), B2("11101000");
cout << (B1 ^ B2) << "\n"; //按位异或
cout << (B1 | B2) << "\n"; //按位或
cout << (B1 & B2) << "\n"; //按位与
cout << (B1 == B2) << "\n"; //比较是否相等
cout << B1 << " " << B2 << "\n"; //你可以直接使用cout输出哈希系列 unordered
通常指代 unordered_map、unordered_set、unordered_multimap、unordered_multiset,与原版相比不进行排序。
如果将不支持哈希的类型作为 key 值代入,编译器就无法正常运行,这时需要我们为其手写哈希函数。而我们写的这个哈希函数的正确性其实并不是特别重要(但是不可以没有),当发生冲突时编译器会调用 key 的 operator == 函数进行进一步判断。参考
对 pair、tuple 定义哈希
struct hash_pair {
template <class T1, class T2>
size_t operator()(const pair<T1, T2> &p) const {
return hash<T1>()(p.fi) ^ hash<T2>()(p.se);
}
};
unordered_set<pair<int, int>, int, hash_pair> S;
unordered_map<tuple<int, int, int>, int, hash_pair> M;对结构体定义哈希
需要两个条件,一个是在结构体中重载等于号(区别于非哈希容器需要重载小于号,如上所述,当冲突时编译器需要根据重载的等于号判断),第二是写一个哈希函数。注意 hash<>() 的尖括号中的类型匹配。
struct fff {
string x, y;
int z;
friend bool operator == (const fff &a, const fff &b) {
return a.x == b.x || a.y == b.y || a.z == b.z;
}
};
struct hash_fff {
size_t operator()(const fff &p) const {
return hash<string>()(p.x) ^ hash<string>()(p.y) ^ hash<int>()(p.z);
}
};
unordered_map<fff, int, hash_fff> mp;对 vector 定义哈希
以下两个方法均可。注意 hash<>() 的尖括号中的类型匹配。
struct hash_vector {
size_t operator()(const vector<int> &p) const {
size_t seed = 0;
for (auto it : p) {
seed ^= hash<int>()(it);
}
return seed;
}
};
unordered_map<vector<int>, int, hash_vector> mp;namespace std {
template<> struct hash<vector<int>> {
size_t operator()(const vector<int> &p) const {
size_t seed = 0;
for (int i : p) {
seed ^= hash<int>()(i) + 0x9e3779b9 + (seed << 6) + (seed >> 2);
}
return seed;
}
};
}
unordered_set<vector<int> > S;卡常
基础算法 | 最大公约数 gcd | 位运算加速
略快于内置函数。
LL gcd(LL a, LL b) {
#define tz __builtin_ctzll
if (!a || !b) return a | b;
int t = tz(a | b);
a >>= tz(a);
while (b) {
b >>= tz(b);
if (a > b) swap(a, b);
b -= a;
}
return a << t;
#undef tz
}数论 | 质数判定 | 预分类讨论加速
常数优化,达到 。
bool is_prime(int n) {
if (n < 2) return false;
if (n == 2 || n == 3) return true;
if (n % 6 != 1 && n % 6 != 5) return false;
for (int i = 5, j = n / i; i <= j; i += 6) {
if (n % i == 0 || n % (i + 2) == 0) {
return false;
}
}
return true;
}数论 | 质数判定 | Miller-Rabin
借助蒙哥马利模乘加速取模运算。
using u64 = uint64_t;
using u128 = __uint128_t;
struct Montgomery {
u64 m, m2, im, l1, l2;
Montgomery() {}
Montgomery(u64 m) : m(m) {
l1 = -(u64)m % m, l2 = -(u128)m % m;
m2 = m << 1, im = m;
for (int i = 0; i < 5; i++) {
im *= 2 - m * im;
}
}
inline u64 operator()(i64 a, i64 b) const {
u128 c = (u128)a * b;
return u64(c >> 64) + m - u64((u64)c * im * (u128)m >> 64);
}
inline u64 reduce(u64 a) const {
a = m - u64(a * im * (u128)m >> 64);
return a >= m ? a - m : a;
}
inline u64 trans(i64 a) const {
return (*this)(a, l2);
}
inline u64 mul(i64 a, i64 b) const {
u64 r = (*this)(trans(a), trans(b));
return reduce(r);
}
u64 pow(u64 a, u64 n) {
u64 r = l1;
a = trans(a);
for (; n; n >>= 1, a = (*this)(a, a)) {
if (n & 1) r = (*this)(r, a);
}
return reduce(r);
}
};
bool isprime(i64 n) {
if (n < 2 || n % 6 % 4 != 1) {
return (n | 1) == 3;
}
u64 s = __builtin_ctzll(n - 1), d = n >> s;
Montgomery M(n);
for (i64 a : {2, 325, 9375, 28178, 450775, 9780504, 1795265022}) {
u64 p = M.pow(a, d), i = s;
while (p != 1 && p != n - 1 && a % n && i--) {
p = M.mul(p, p);
}
if (p != n - 1 && i != s) return false;
}
return true;
}数论 | 质因数分解 | Pollard-Rho
struct Montgomery {} M(10); // 注意预赋值
bool isprime(i64 n) {}
i64 rho(i64 n) {
if (!(n & 1)) return 2;
i64 x = 0, y = 0, prod = 1;
auto f = [&](i64 x) -> i64 {
return M.mul(x, x) + 5; // 这里的种子能被 hack ,如果是在线比赛,请务必 rand 生成
};
for (int t = 30, z = 0; t % 64 || gcd(prod, n) == 1; ++t) {
if (x == y) x = ++z, y = f(x);
if (i64 q = M.mul(prod, x + n - y)) prod = q;
x = f(x), y = f(f(y));
}
return gcd(prod, n);
}
vector<i64> factorize(i64 x) {
vector<i64> res;
auto f = [&](auto f, i64 x) {
if (x == 1) return;
M = Montgomery(x); // 重设模数
if (isprime(x)) return res.push_back(x);
i64 y = rho(x);
f(f, y), f(f, x / y);
};
f(f, x), sort(res.begin(), res.end());
return res;
}数论 | 取模运算类 | 蒙哥马利模乘
using u64 = uint64_t;
using u128 = __uint128_t;
struct Montgomery {
u64 m, m2, im, l1, l2;
Montgomery() {}
Montgomery(u64 m) : m(m) {
l1 = -(u64)m % m, l2 = -(u128)m % m;
m2 = m << 1, im = m;
for (int i = 0; i < 5; i++) im *= 2 - m * im;
}
inline u64 operator()(i64 a, i64 b) const {
u128 c = (u128)a * b;
return u64(c >> 64) + m - u64((u64)c * im * (u128)m >> 64);
}
inline u64 reduce(u64 a) const {
a = m - u64(a * im * (u128)m >> 64);
return a >= m ? a - m : a;
}
inline u64 trans(i64 a) const {
return (*this)(a, l2);
}
inline u64 add(i64 a, i64 b) const {
u64 c = trans(a) + trans(b);
if (c >= m2) c -= m2;
return reduce(c);
}
inline u64 sub(i64 a, i64 b) const {
u64 c = trans(a) - trans(b);
if (c >= m2) c += m2;
return reduce(c);
}
inline u64 mul(i64 a, i64 b) const {
return reduce((*this)(trans(a), trans(b)));
}
inline u64 div(i64 a, i64 b) const {
a = trans(a), b = trans(b);
u64 n = m - 2, inv = l1;
for (; n; n >>= 1, b = (*this)(b, b))
if (n & 1) inv = (*this)(inv, b);
return reduce((*this)(a, inv));
}
u64 pow(u64 a, u64 n) {
u64 r = l1;
a = trans(a);
for (; n; n >>= 1, a = (*this)(a, a))
if (n & 1) r = (*this)(r, a);
return reduce(r);
}
};快读
注意读入到文件结尾才结束,直接运行会无输出。
template<class T>
void read(T &in) {
T x = 0, t = 1;
char ch = getchar();
while (ch < '0' || ch > '9') {
if (ch == '-') t = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
in = x * t;
}
template<class T>
void out(T x) {
if (x < 0) {
putchar('-');
x = -x;
}
if (x > 9) out(x / 10);
putchar(x % 10 + '0');
}
template<class T>
void outline(T x) {
out(x);
putchar('\n');
}杂类
统计区间不同数字的数量(离线查询)
核心在于使用 pre 数组滚动维护每一个数字出现的最后位置,配以树状数组统计数量。由于滚动维护具有后效性,所以需要离线操作,从前往后更新。时间复杂度 ,常数瓶颈在于 map,用手造哈希或者离散化可以优化到理想区间;同时也有莫队做法,复杂度稍劣。例题链接 。
signed main() {
int n;
cin >> n;
vector<int> in(n + 1);
for (int i = 1; i <= n; i++) {
cin >> in[i];
}
int q;
cin >> q;
vector<array<int, 3>> query;
for (int i = 0; i < q; i++) {
int l, r;
cin >> l >> r;
query.push_back({r, l, i});
}
sort(query.begin(), query.end());
vector<pair<int, int>> ans;
map<int, int> pre;
int st = 1;
BIT bit(n);
for (auto [r, l, id] : query) {
for (int i = st; i <= r; i++, st++) {
if (pre.count(in[i])) { // 消除此前操作的影响
bit.add(pre[in[i]], -1);
}
bit.add(i, 1);
pre[in[i]] = i; // 更新操作
}
ans.push_back({id, bit.ask(r) - bit.ask(l - 1)});
}
sort(ans.begin(), ans.end());
for (auto [id, w] : ans) {
cout << w << endl;
}
}选数(DFS 解)
从 个整数中任选 个整数相加。使用 求解。
int n, k; cin >> n >> k;
vector<int> in(n), now(n);
for (auto &it : in) { cin >> it; }
auto dfs = [&](auto self, int k, int bit, int idx) -> void {
for (int i = idx; i < n; i++) {
now[bit] = in[i];
if (bit < k - 1) { self(self, k, bit + 1, i + 1); }
if (bit == k - 1) {
int add = 0;
for (int j = 0; j < k; j++) {
add += now[j];
}
cout << add << endl;
}
}
};
dfs(dfs, k, 0, 0);选数(位运算状压)
int n, k; cin >> n >> k;
vector<int> in(n);
for (auto &it : in) { cin >> it; }
int comb = (1 << k) - 1, U = 1 << n;
while (comb < U) {
int add = 0;
for (int i = 0; i < n; i++) {
if (1 << i & comb) {
add += in[i];
}
}
cout << add << "\n";
int x = comb & -comb;
int y = comb + x;
int z = comb & ~y;
comb = (z / x >> 1) | y;
}网格路径计数
从 走到 ,规定每次只能从 走到左下或者右下,方案数记为 。
- ;
- 若路径和直线 不能有交点,则方案数为 ;
- 若路径和两条直线 不能有交点,方案数记为 ,可以使用 递归求解;
- 若路径必须碰到 但是不能碰到 ,方案数记为 ,可以使用 递归求解(递归过程中两条直线距离会越来越大)。
从 走到 ,规定每次只能走到左下或者右下,且必须有恰好一次传送(向下 单位),且不能走到 轴下方,方案数为 。
德州扑克
读入牌型,并且支持两副牌之间的大小比较。代码参考
struct card {
int suit, rank;
friend bool operator < (const card &a, const card &b) {
return a.rank < b.rank;
}
friend bool operator == (const card &a, const card &b) {
return a.rank == b.rank;
}
friend bool operator != (const card &a, const card &b) {
return a.rank != b.rank;
}
friend auto &operator>> (istream &it, card &C) {
string S, T; it >> S;
T = "__23456789TJQKA"; //点数
FOR (i, 0, T.sz - 1) {
if (T[i] == S[0]) C.rank = i;
}
T = "_SHCD"; //花色
FOR (i, 0, T.sz - 1) {
if (T[i] == S[1]) C.suit = i;
}
return it;
}
};
struct game {
int level;
vector<card> peo;
int a, b, c, d, e;
int u, v, w, x, y;
bool Rk10() { //Rk10: Royal Flush,五张牌同花色,且点数为AKQJT(14,13,12,11,10)
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (u != v || v != w || w != x || x != y) return 0;
if (a == 14 && b == 13 && c == 12 && d == 11 && e == 10) return 1;
return 0;
}
bool Dif(vector<card> &peo) { //专门用于检查A2345这种顺子的情况(这是最小的顺子)
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (a != 14 || b != 5 || c != 4 || d != 3 || e != 2) return 0;
vector<card> peo2 = {peo[1], peo[2], peo[3], peo[4], peo[0]}; //重新排序
peo = peo2;
return 1;
}
bool Rk9() { //Rk9: Straight Flush,五张牌同花色,且顺连【r1 > r2 > r3 > r4 > r5】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (u != v || v != w || w != x || x != y) return 0;
if (Dif(peo)) return 1; //特判:A2345
if (a == b + 1 && b == c + 1 && c == d + 1 && d == e + 1) return 1;
return 0;
}
bool Rk8() { //Rk8: Four of a Kind,四张牌点数一样【r1 = r2 = r3 = r4】
sort(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (a == b && b == c && c == d) return 1;
if (b == c && c == d && d == e) {
reverse(ALL(peo));
return 1;
}
return 0;
}
bool Rk7() { //Rk7: Fullhouse,三张牌点数一样,另外两张点数也一样【r1 = r2 = r3,r4 = r5】
sort(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (a == b && b == c && d == e) return 1;
if (a == b && c == d && d == e) {
reverse(ALL(peo));
return 1;
}
return 0;
}
bool Rk6() { //Rk6: Flush,五张牌同花色【r1 > r2 > r3 > r4 > r5】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (u != v || v != w || w != x || x != y) return 0;
return 1;
}
bool Rk5() { //Rk5: Straight,五张牌顺连【r1 > r2 > r3 > r4 > r5】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (Dif(peo)) return 1; //特判:A2345
if (a == b + 1 && b == c + 1 && c == d + 1 && d == e + 1) return 1;
return 0;
}
bool Rk4() { //Rk4: Three of a kind,三张牌点数一样【r1 = r2 = r3,r4 > r5】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (a == b && b == c) return 1;
if (b == c && c == d) {
swap(peo[3], peo[0]);
return 1;
}
if (c == d && d == e) {
swap(peo[3], peo[0]);
swap(peo[4], peo[1]);
return 1;
}
return 0;
}
bool Rk3() { //Rk3: Two Pairs,两张牌点数一样,另外有两张点数也一样(两个对子)【r1 = r2 > r3 = r4】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
if (a == b && c == d) return 1;
if (a == b && d == e) {
swap(peo[2], peo[4]);
return 1;
}
if (b == c && d == e) {
swap(peo[0], peo[2]);
swap(peo[2], peo[4]);
return 1;
}
return 0;
}
bool Rk2() { //Rk2: One Pairs,两张牌点数一样(一个对子)【r1 = r2,r3 > r4 > r5】
sort(ALL(peo));
reverse(ALL(peo));
a = peo[0].rank, b = peo[1].rank, c = peo[2].rank, d = peo[3].rank, e = peo[4].rank;
u = peo[0].suit, v = peo[1].suit, w = peo[2].suit, x = peo[3].suit, y = peo[4].suit;
vector<card> peo2;
if (a == b) return 1;
if (b == c) {
peo2 = {peo[1], peo[2], peo[0], peo[3], peo[4]};
peo = peo2;
return 1;
}
if (c == d) {
peo2 = {peo[2], peo[3], peo[0], peo[1], peo[4]};
peo = peo2;
return 1;
}
if (d == e) {
peo2 = {peo[3], peo[4], peo[0], peo[1], peo[2]};
peo = peo2;
return 1;
}
return 0;
}
bool Rk1() { //Rk1: high card
sort(ALL(peo));
reverse(ALL(peo));
return 1;
}
game (vector<card> New_peo) {
peo = New_peo;
if (Rk10()) { level = 10; return; }
if (Rk9()) { level = 9; return; }
if (Rk8()) { level = 8; return; }
if (Rk7()) { level = 7; return; }
if (Rk6()) { level = 6; return; }
if (Rk5()) { level = 5; return; }
if (Rk4()) { level = 4; return; }
if (Rk3()) { level = 3; return; }
if (Rk2()) { level = 2; return; }
if (Rk1()) { level = 1; return; }
}
friend bool operator < (const game &a, const game &b) {
if (a.level != b.level) return a.level < b.level;
FOR (i, 0, 4) if (a.peo[i] != b.peo[i]) return a.peo[i] < b.peo[i];
return 0;
}
friend bool operator == (const game &a, const game &b) {
if (a.level != b.level) return 0;
FOR (i, 0, 4) if (a.peo[i] != b.peo[i]) return 0;
return 1;
}
};
void debug(vector<card> peo) {
for (auto it : peo) cout << it.rank << " " << it.suit << " ";
cout << "\n\n";
}
int clac(vector<card> Ali, vector<card> Bob) {
game atype(Ali), btype(Bob);
if (atype < btype) return -1;
else if (atype == btype) return 0;
return 1;
}N*M 数独字典序最小方案
规则:每个宫大小为 ,大图一共由 个宫组成(总大小即 ),要求每行、每列、每宫都要出现 到 的全部数字。输出字典序最小方案。
下例为 和 时数独字典序最小的示意。
公式: 格所填的内容为 ,注意 从 开始。
高精度进制转换
进制相互转换。输入格式:"转换前进制 转换后进制 要转换的数据"。注释:进制排序为 0-9,A-Z,a-z。
struct numpy {
vector<int> mp; // 将字符转化为数字
vector<char> mp2; // 将数字转化为字符
numpy() : mp(123), mp2(62) { // 0-9A-Za-z
for (int i = 0; i < 10; i++) mp[i + 48] = i, mp2[i] = i + 48;
for (int i = 10; i < 36; i++) mp[i + 55] = i, mp2[i] = i + 55;
for (int i = 36; i < 62; i++) mp[i + 61] = i, mp2[i] = i + 61;
}
// 转换前进制 转换后进制 要转换的数据
string solve(int a, int b, const string &s) {
vector<int> nums, ans;
for (auto c : s) {
nums.push_back(mp[c]);
}
reverse(nums.begin(), nums.end());
while (nums.size()) { // 短除法,将整个大数一直除 b ,取余数
int remainder = 0;
for (int i = nums.size() - 1; ~i; i--) {
nums[i] += remainder * a;
remainder = nums[i] % b;
nums[i] /= b;
}
ans.push_back(remainder); // 得到余数
while (nums.size() && nums.back() == 0) {
nums.pop_back(); // 去掉前导 0
}
}
reverse(ans.begin(), ans.end());
string sh;
for (int i : ans) sh += mp2[i];
return sh;
}
};物品装箱
有 个物品,第 个物品为 ,有无限个容量为 的空箱子。两种装箱方式,输出需要多少个箱子才能装完所有物品。
从前往后装(线段树解)
选择最前面的能放下物品的箱子放入物品。
const int N = 1e6 + 10;
int T, n, a[N], c, tr[N << 2];
void pushup(int u){
tr[u] = max(tr[u << 1], tr[u << 1 | 1]);
}
void build(int u, int l, int r){
if (l == r) tr[u] = c;
else {
int mid = l + r >> 1;
build(u << 1, l, mid);
build(u << 1 | 1, mid + 1, r);
pushup(u);
}
}
void update(int u, int l, int r, int p, int k){
if (l > p || r < p) return;
if (l == r) tr[u] -= k;
else {
int mid = l + r >> 1;
update(u << 1, l, mid, p, k);
update(u << 1 | 1, mid + 1, r, p, k);
pushup(u);
}
}
int query(int u, int l, int r, int k){
if (l == r){
if (tr[u] >= k) return l;
return n + 1;
}
int mid = l + r >> 1;
if (tr[u << 1] >= k) return query(u << 1, l, mid, k);
else return query(u << 1 | 1, mid + 1, r, k);
}
int main() {
cin >> n >> c;
for (int i = 1; i <= n; i++) cin >> a[i];
build(1, 1, n);
for (int i = 1; i <= n; i++)
update(1, 1, n, query(1, 1, n, a[i]), a[i]);
cout << query(1, 1, n, c) - 1 << " ";
}选择最优的箱子装(multiset 解)
选择能放下物品且剩余容量最小的箱子放物品
void solve(){
cin >> n >> c;
for (int i = 1; i <= n; i++) cin >> a[i];
multiset <int> s;
for (int i = 1; i <= n; i++){
auto it = s.lower_bound(a[i]);
if (it == s.end()) s.insert(c - a[i]);
else {
int x = *it;
// multiset 可以存放重复数据,如果是删除某个值的话,会去掉多个箱子
// 导致答案错误,所以直接删除对应位置的元素
s.erase(it);
s.insert(x - a[i]);
}
}
cout << s.size() << "\n";
}浮点数比较
比较下列浮点数的大小: 和 。
vector<pair<ld, int>> val = {
{log(x) * pow(y, z), 0}, {log(x) * pow(z, y), 1}, {log(x) * y * z, 2},
{log(x) * z * y, 3}, {log(y) * pow(x, z), 4}, {log(y) * pow(z, x), 5},
{log(y) * x * z, 6}, {log(y) * z * x, 7}, {log(z) * pow(x, y), 8},
{log(z) * pow(y, x), 9}, {log(z) * x * y, 10}, {log(z) * y * x, 11}};
sort(val.begin(), val.end(), [&](auto x, auto y) {
if (equal(x.first, y.first)) return x.second < y.second; // queal比较两个浮点数是否相等
return x.first > y.first;
});
cout << ans[val.front().second] << endl;阿达马矩阵 (Hadamard matrix)
构造题用,其有一些性质:将 看作 ; 看作 ,整个矩阵可以构成一个 维向量组,任意两个行、列向量的点积均为 See。例如,在 时行向量 和行向量 的点积为 。
构造方式:
int n;
cin >> n;
int N = pow(2, n);
vector ans(N, vector<int>(N));
ans[0][0] = 1;
for (int t = 0; t < n; t++) {
int m = pow(2, t);
for (int i = 0; i < m; i++) {
for (int j = m; j < 2 * m; j++) {
ans[i][j] = ans[i][j - m];
}
}
for (int i = m; i < 2 * m; i++) {
for (int j = 0; j < m; j++) {
ans[i][j] = ans[i - m][j];
}
}
for (int i = m; i < 2 * m; i++) {
for (int j = m; j < 2 * m; j++) {
ans[i][j] = 1 - ans[i - m][j - m];
}
}
}幻方
构造题用,其有一些性质(保证 为奇数): 到 每个数字恰好使用一次,且每行、每列及两条对角线上的数字之和都相同,且为奇数 See 。
构造方式:将 写在第一行的中间,随后不断向右上角位置填下一个数字,直到填满。
int n;
cin >> n;
int x = 1, y = (n + 1) / 2;
vector ans(n + 1, vector<int>(n + 1));
for (int i = 1; i <= n * n; i++) {
ans[x][y] = i;
if (!ans[(x - 2 + n) % n + 1][y % n + 1]){
x = (x - 2 + n) % n + 1;
y = y % n + 1;
} else {
x = x % n + 1;
}
}最长严格/非严格递增子序列 (LIS)
一维
注意子序列是不连续的。使用二分搜索,以 复杂度通过,另也有 的 解法。
vector<int> val; // 堆数
for (int i = 1, x; i <= n; i++) {
cin >> x;
int it = upper_bound(val.begin(), val.end(), x) - val.begin(); // low/upp: 严格/非严格递增
if (it >= val.size()) { // 新增一堆
val.push_back(x);
} else { // 更新对应位置元素
val[it] = x;
}
}
cout << val.size() << endl;二维+输出方案
vector<array<int, 3>> in(n + 1);
for (int i = 1; i <= n; i++) {
cin >> in[i][0] >> in[i][1];
in[i][2] = i;
}
sort(in.begin() + 1, in.end(), [&](auto x, auto y) {
if (x[0] != y[0]) return x[0] < y[0];
return x[1] > y[1];
});
vector<int> val{0}, idx{0}, pre(n + 1);
for (int i = 1; i <= n; i++) {
auto [x, y, z] = in[i];
int it = lower_bound(val.begin(), val.end(), y) - val.begin(); // low/upp: 严格/非严格递增
if (it >= val.size()) { // 新增一堆
pre[z] = idx.back();
val.push_back(y);
idx.push_back(z);
} else { // 更新对应位置元素
pre[z] = idx[it - 1];
val[it] = y;
idx[it] = z;
}
}
vector<int> ans;
for (int i = idx.back(); i != 0; i = pre[i]) {
ans.push_back(i);
}
reverse(ans.begin(), ans.end());
cout << ans.size() << "\n";
for (auto it : ans) {
cout << it << " ";
}cout 输出流控制
设置字段宽度:setw(x) ,该函数可以使得补全 位输出,默认用空格补全。
bool Solve() {
cout << 12 << endl;
cout << setw(12) << 12 << endl;
return 0;
}
设置填充字符:setfill(x) ,该函数可以设定补全类型,注意这里的 只能为 类型。
bool Solve() {
cout << 12 << endl;
cout << setw(12) << setfill('*') << 12 << endl;
return 0;
}
读取一行数字,个数未知
string s;
getline(cin, s);
stringstream ss;
ss << s;
while (ss >> s) {
auto res = stoi(s);
cout << res * 100 << endl;
}约瑟夫问题
个人编号 ,每次数到 出局,求最后剩下的人的编号。
。
int jos(int n,int k){
int res=0;
repeat(i,1,n+1)res=(res+k)%i;
return res; // res+1,如果编号从1开始
},适用于 较小的情况。
int jos(int n,int k){
if(n==1 || k==1)return n-1;
if(k>n)return (jos(n-1,k)+k)%n; // 线性算法
int res=jos(n-n/k,k)-n%k;
if(res<0)res+=n; // mod n
else res+=res/(k-1); // 还原位置
return res; // res+1,如果编号从1开始
}日期换算(基姆拉尔森公式)
已知年月日,求星期数。
int week(int y,int m,int d){
if(m<=2)m+=12,y--;
return (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400)%7+1;
}单调队列
查询区间 的最大最小值。
deque<int> D;
int n, k, x, a[MAX];
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int i = 1; i <= n; i++) {
while (!D.empty() && a[D.back()] <= a[i]) D.pop_back();
D.emplace_back(i);
if (!D.empty()) if (i - D.front() >= k) D.pop_front();
if (i >= k)cout << a[D.front()] << endl;
}
return 0;
}高精度快速幂
求解 ,其中 。容易发现 可以直接取模,瓶颈在于 See。
魔改十进制快速幂(暴力计算)
该算法复杂度 。
int mypow10(int n, vector<int> k, int p) {
int r = 1;
for (int i = k.size() - 1; i >= 0; i--) {
for (int j = 1; j <= k[i]; j++) {
r = r * n % p;
}
int v = 1;
for (int j = 0; j <= 9; j++) {
v = v * n % p;
}
n = v;
}
return r;
}
signed main() {
string n_, k_;
int p;
cin >> n_ >> k_ >> p;
int n = 0; // 转化并计算 n % p
for (auto it : n_) {
n = n * 10 + it - '0';
n %= p;
}
vector<int> k; // 转化 k
for (auto it : k_) {
k.push_back(it - '0');
}
cout << mypow10(n, k, p) << endl; // 暴力快速幂
}扩展欧拉定理(欧拉降幂公式)
最终我们可以将幂降到 的级别,使得能够直接使用快速幂解题,复杂度瓶颈在求解欧拉函数 。
int phi(int n) { //求解 phi(n)
int ans = n;
for (int i = 2; i <= n / i; i++) {
if (n % i == 0) {
ans = ans / i * (i - 1);
while (n % i == 0) {
n /= i;
}
}
}
if (n > 1) { //特判 n 为质数的情况
ans = ans / n * (n - 1);
}
return ans;
}
signed main() {
string n_, k_;
int p;
cin >> n_ >> k_ >> p;
int n = 0; // 转化并计算 n % p
for (auto it : n_) {
n = n * 10 + it - '0';
n %= p;
}
int mul = phi(p), type = 0, k = 0; // 转化 k
for (auto it : k_) {
k = k * 10 + it - '0';
type |= (k >= mul);
k %= mul;
}
if (type) {
k += mul;
}
cout << mypow(n, k, p) << endl;
}对拍版子
- 文件控制
// BAD.cpp, 存放待寻找错误的代码
freopen("A.txt","r",stdin);
freopen("BAD.out","w",stdout);
// 1.cpp, 存放暴力或正确的代码
freopen("A.txt","r",stdin);
freopen("1.out","w",stdout);
// Ask.cpp
freopen("A.txt", "w", stdout);- 版
int main() {
int T = 1E5;
while(T--) {
system("BAD.exe");
system("1.exe");
system("A.exe");
if (system("fc BAD.out 1.out")) {
puts("WA");
return 0;
}
}
}随机数生成与样例构造
mt19937 rnd(chrono::steady_clock::now().time_since_epoch().count());
int r(int a, int b) {
return rnd() % (b - a + 1) + a;
}
void graph(int n, int root = -1, int m = -1) {
vector<pair<int, int>> t;
for (int i = 1; i < n; i++) { // 先建立一棵以0为根节点的树
t.emplace_back(i, r(0, i - 1));
}
vector<pair<int, int>> edge;
set<pair<int, int>> uni;
if (root == -1) root = r(0, n - 1); // 确定根节点
for (auto [x, y] : t) { // 偏移建树
x = (x + root) % n + 1;
y = (y + root) % n + 1;
edge.emplace_back(x, y);
uni.emplace(x, y);
}
if (m != -1) { // 如果是图,则在树的基础上继续加边
for (int i = n; i <= m; i++) {
while (true) {
int x = r(1, n), y = r(1, n);
if (x == y) continue; // 拒绝自环
if (uni.count({x, y})) continue; // 拒绝重边
edge.emplace_back(x, y);
uni.emplace(x, y);
}
}
}
random_shuffle(edge.begin(), edge.end()); // 打乱节点
for (auto [x, y] : edge) {
cout << x << " " << y << endl;
}
}手工哈希
struct myhash {
static uint64_t hash(uint64_t x) {
x += 0x9e3779b97f4a7c15;
x = (x ^ (x >> 30)) * 0xbf58476d1ce4e5b9;
x = (x ^ (x >> 27)) * 0x94d049bb133111eb;
return x ^ (x >> 31);
}
size_t operator()(uint64_t x) const {
static const uint64_t SEED = chrono::steady_clock::now().time_since_epoch().count();
return hash(x + SEED);
}
size_t operator()(pair<uint64_t, uint64_t> x) const {
static const uint64_t SEED = chrono::steady_clock::now().time_since_epoch().count();
return hash(x.first + SEED) ^ (hash(x.second + SEED) >> 1);
}
};
// unordered_map<int, int, myhash>Python常用语法
读入与定义
- 读入多个变量并转换类型:
X, Y = map(int, input().split()) - 读入列表:
X = eval(input()) - 多维数组定义:
X = [[0 for j in range(0, 100)] for i in range(0, 200)]
格式化输出
- 保留小数输出:
print("{:.12f}".format(X))指保留 位小数 - 对齐与宽度:
print("{:<12f}".format(X))指左对齐,保留 个宽度
排序
- 倒序排序:使用
reverse实现倒序X.sort(reverse=True) - 自定义排序:下方代码实现了先按第一关键字降序、再按第二关键字升序排序。
X.sort(key=lambda x: x[1]) X.sort(key=lambda x: x[0], reverse=True)
文件IO
- 打开要读取的文件:
r = open('X.txt', 'r', encoding='utf-8') - 打开要写入的文件:
w = open('Y.txt', 'w', encoding='utf-8') - 按行写入:
w.write(XX)
增加输出流长度、递归深度
import sys
sys.set_int_max_str_digits(200000)
sys.setrecursionlimit(100000)自定义结构体
自定义结构体并且自定义排序
class node:
def __init__(self, A, B, C):
self.A = A
self.B = B
self.C = C
w = []
for i in range(1, 5):
a, b, c = input().split()
w.append(node(a, b, c))
w.sort(key=lambda x: x.C, reverse=True)
for i in w:
print(i.A, i.B, i.C)数据结构
- 模拟于 ,定义:
dic = dict() - 模拟栈与队列:使用常见的 即可完成,
list.insert(0, X)实现头部插入、list.pop()实现尾部弹出、list.pop(0)实现头部弹出
python高精度
从 decimal 模块导入 Decimal 类和 setcontext 函数。
设置计算上下文,以支持高达 2000000 位的精度,以及相应的指数范围。
从标准输入读取两行,每行包含一个数字,并将它们转换为 Decimal 对象。
执行乘法运算,并将结果打印出来。
高精度
from decimal import * import sys setcontext(Context(prec=2000000, Emax=2000000, Emin=0)) print((Decimal(sys.stdin.readline())*Decimal(sys.stdin.readline())))
其他
- 获取ASCII码:
ord()函数 - 转换为ASCII字符:
chr()函数
OJ测试
对于一个未知属性的OJ,应当在正式赛前进行以下全部测试:
GNU C++ 版本测试
for (int i : {1, 2}) {} // GNU C++11 支持范围表达式
auto cc = [&](int x) { x++; }; // GNU C++11 支持 auto 与 lambda 表达式
cc(2);
tuple<string, int, int> V; // GNU C++11 引入
array<int, 3> C; // GNU C++11 引入
auto dfs = [&](auto self, int x) -> void { // GNU C++14 支持 auto 自递归
if (x > 10) return;
self(self, x + 1);
};
dfs(dfs, 1);
vector in(1, vector<int>(1)); // GNU C++17 支持 vector 模板类型缺失
map<int, int> dic;
for (auto [u, v] : dic) {} // GNU C++17 支持 auto 解绑
dic.contains(12); // GNU C++20 支持 contains 函数
constexpr double Pi = numbers::pi; // C++20 支持评测器环境测试
Windows 系统输出 ;反之则为一个随机数。
#define int long long
map<int, int> dic;
int x = dic.size() - 1;
cout << x << endl;运算速度测试
| 本地-20(64) | CodeForces-20(64) | AtCoder-20(64) | 牛客-17(64) | 学院OJ | CodeForces-17(32) | 马蹄集 | |
|---|---|---|---|---|---|---|---|
| 4E3量级-硬跑 | 2454 | 2886 | 874 | 4121 | 4807 | 2854 | 4986 |
| 4E3量级-手动加速 | 556 | 686 | 873 | 1716 | 1982 | 2246 | 2119 |
// #pragma GCC optimize("Ofast", "unroll-loops")
#include <bits/stdc++.h>
using namespace std;
signed main() {
int n = 4E3, cnt = 0;
bitset<30> ans;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j += 2) {
for (int k = 1; k <= n; k += 4) {
ans |= i | j | k;
cnt++;
}
}
}
cout << cnt << "\n";
}// #pragma GCC optimize("Ofast", "unroll-loops")
#include <bits/stdc++.h>
using namespace std;
mt19937 rnd(chrono::steady_clock::now().time_since_epoch().count());
signed main() {
size_t n = 340000000, seed = 0;
for (int i = 1; i <= n; i++) {
seed ^= rnd();
}
return 0;
}编译器设置
g++ -O2 -std=c++20 -pipe
-Wall -Wextra -Wconversion /* 这部分是警告相关,可能用不到 */
-fstack-protector
-Wl,--stack=268435456CMAKE
MATH(EXPR stack_size "256*1024*1024") # 手动修改栈空间256MB
set(CMAKE_EXE_LINKER_FLAGS "-Wl,--stack,${stack_size}")